
Enterprises have the need to apply online machine learning to react directly to events in Big Data streams by using Big Data Stream mining. In this article, we discuss how Random Forests differs from Adaptive Random Forests and how they can be used for Big Data analysis.

Neural Networks are insufficient for Big Data Stream mining
Neuronal Networks and Deep learning are often considered as the non plus ultra in machine learning. However, Neural Networks are often not the perfect Big Data Stream mining.
A Neural Network is trained with input data of any sample size for any task which includes classification, recognition, Natural Language Processing (NLP) and more. These computations using Neural Network mostly requires large amounts of processed data of similar pattern and type in which the model will be trained on.
But what if the pattern of data is changing continuously and in real-time?
Extensive and large calculations done over existing datasets in a Neural Network cannot be implemented over a traditional approach and when the patterns in the data are not stable, a Neural Network will likely fail. The workaround is therefore to implement Big Data Stream mining with distributed computing. Thereby, one uses using Big Data technologies like Spark Streaming, Apache Flink or similar to feed data continuously to Machine Learning algorithms for its applications.
What is Random Forest?

To understand Adaptive Random Forests, we have to first understand decision trees. Decision trees in most simple terms are basically a decision tool that uses root and branch-like models to identify possible consequences by using control statements.
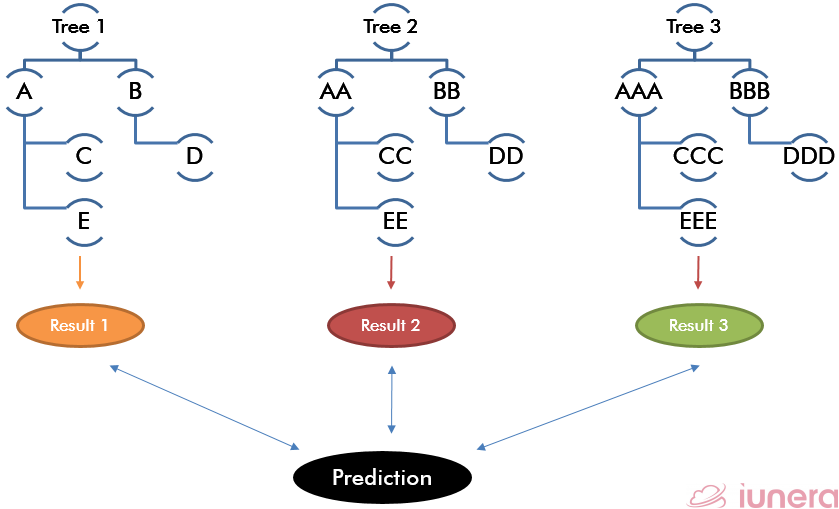
Random Forests are basically the combination of multiple individual decision trees to act as an ensemble. Ensemble learning can be defined as a paradigm whereby multiple learners are trained to solve the same problem.
Ensemble learning actually has been used in several applications such as optical character recognition, medical purpose, etc. In fact, ensemble learning can be used wherever machine learning techniques can be used.
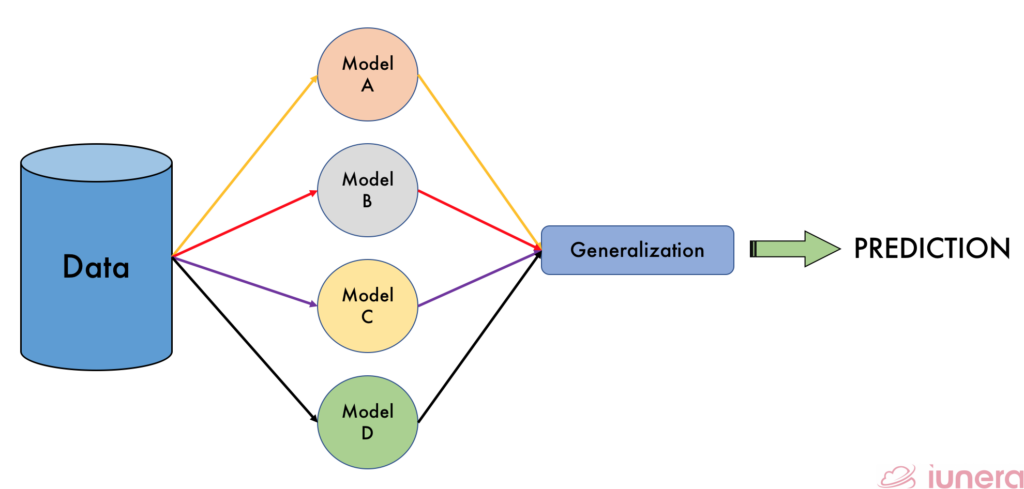
Combining multiple trees (learner) may be a better choice if the learners are performing well. In fact, Random Forests is currently one of the most used Machine Learning algorithms in the batch setting.
What is Adaptive Random Forest?

Big Data stream, or Online Learning classification, is similar to batch or Offline classification in the sense that both are concerned with predicting a class value of an unlabelled instance. The difference between Online learning or Adaptive vs Offline learning, however, is how the learning and predictions take place.
How does an Adaptive Random Forests work?
Similarly to Adaptive Random Forests, there are also different online algorithms which can be used for Big Data such as Online Learning Support Vector Machines (SVM) which can be adapted for real-time data streaming.
In general, for Random Forests, the key elements are bagging and random feature selection. Bagging stands for Bootstrap Aggregation which is a very powerful ensemble method. It combines predictions from multiple algorithms to have a more accurate prediction as stated above. In Offline or traditional Random Forests, non-streaming bagging is done.
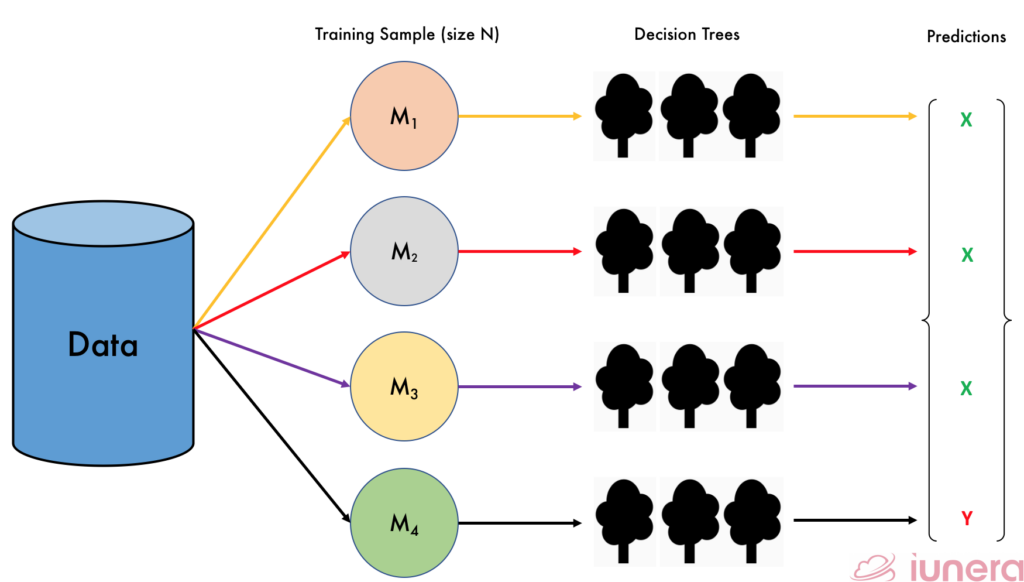
The algorithm builds a set of M base samples with size N, training each models or learners individually taken from random samples with replacement from the original training dataset. The predictions are then produced which follows a binomial distribution. When the value of N is large, the distribution now becomes a Poisson distribution.
In Online bagging, instead of replacement, each of the M samples is given a certain random weight, W which follows a Poisson distribution
When the weights, W of a certain sample M is greater or more significant than the other, the others are then resampled accordingly. By this way, the diversity of the weights and the input space of the classifiers inside the ensemble are being modified actively to find the accurate prediction with the most number of occurence.
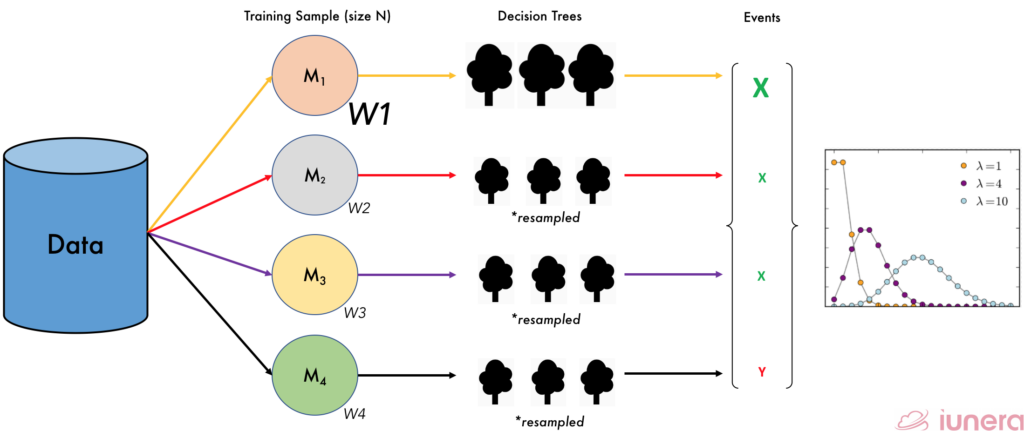
In Online bagging, concept drifts are ought to occur. Adaptive Windowing (ADWIN) is a popular method to detect a change of pattern in data. In relation to Online Random Forest, we can then train the classifier with the random weights, and when a change or drift is detected, the worst classifier of the ensemble of classifiers is removed and a new classifier is added to the ensemble.
Adaptive Random Forest vs Random Forest
Bagging Method
- Traditional Random Forests – Multiple classifiers are trained and the most frequently seen observation from the forests are taken as the prediction
- Adaptive Random Forests – Random weights, W is assigned to each classifier and depending on the performance, it is either replaced by a new sample set or retained to produce the prediction following Poison distribution (number of independent events)
Concept Drift
- Traditional Random Forests – Does not take drift into account which means it will perform poorly with streaming data
- Adaptive Random Forest – Takes into account pattern drifts and removes the classifiers which are not performing well to optimise ensemble model
In the End
In a general sense, Adaptive Random Forests are commonly used in Big Data applications where you would have real-time big streaming data for classification or prediction.
Traditional Random Forests, however, is more defined for non-streaming data with simpler prediction applications. The use of the Adaptive Random Forest algorithm ultimately depends on the types and characteristics of the data that we have.
Are you looking for ways to get the best out of your data?
If yes, then let us help you use your data.
Sum-up FAQ
Why are Neural Networks not suitable for Big Data Stream mining?

Extensive and large calculations done over existing datasets in a Neural Network cannot be implemented over a traditional approach and when the patterns in the data are not stable.
What are the main features of Adaptive Random Forests vs Traditional Random Forests?

In Adaptive Random Forests, random weights, are assigned to each classifier to indicate prediction performance. Adaptive Random Forests can also handle concept drifts when the data pattern is not stable.
What are ensembles in Big Data Stream mining??
Ensemble learning can be defined as a paradigm whereby multiple learners are trained to solve the same problem.
What is Bagging in Big Data Stream mining?
Bagging decreases the variance in the prediction by generating additional data, remove data and optimising it.