
What is kNN and how is it applied to Machine Learning?

In the domain of Machine Learning, a supervised algorithm is used to solve classification or regression problems. One of the most popular classification algorithms is called k-nearest neighbours (kNN).
In this article, we will understand the basics of kNN and how it is applied to classification problems.
What is Classification?
In statistics and Machine Learning, many different methods and techniques could be used in a separate area of interest. Classification is one of the domains of Machine Learning that help to assign a class label to an input.
Noble classifications algorithms make it possible to perform this. Below listed are some of the popular ones that are commonly used in the industry and researchers in the application:
- Decision Trees
- k Nearest Neighbour (k-NN)
- Artificial Neural Networks (ANN)
- Support Vector Machines (SVM)
- Random Forest
- Clustering
What is k-Nearest Neighbours?
In short, k-nearest neighbour, or kNN, is one of the simplest Machine Learning algorithms based on supervised learning technique. kNN algorithm assumes the similarity between the new case/data and available cases and puts the unique point into the most similar category to the general categories.
The kNN algorithm assumes that similar things exist in close proximity. In other words, similar things are near to each other.
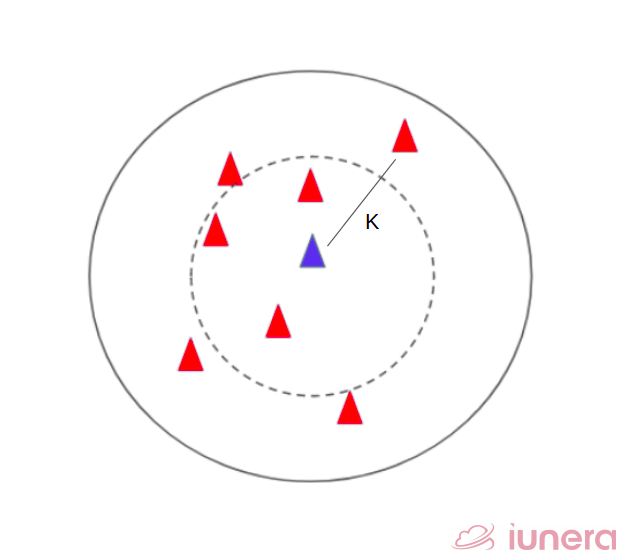
How does the algorithm actually work? The algorithm captures the idea of similarity (sometimes called distance, proximity, or closeness) with some mathematics we might have learned in our childhood— calculating the distance between points on a graph.
Why do we need the kNN algorithm?
Suppose there is a data point that needs to be categorized or classified into one of 2 classes, Class A and Class B. By using kNN algorithm, we can easily identify the class that this particular data point will go to.
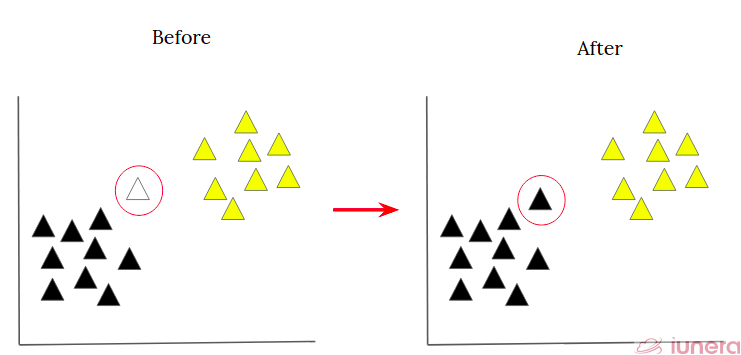
By using this algorithm, we can accurately classify the data points so that it belongs to a particular class. kNN classifies the new data points based on the similarity measure of the earlier stored data points.
Working Principle of a kNN algorithm
Below listed are the internal mechanism of a kNN algorithm:
Step 1 – The k number of neighbours are set. This determines the overall radius of the data points being classified. The higher the k value, the more data points will be classified for that particular class.
Step 2 – Calculate the Euclidean distance of k number of neighbours.
Step 3 – Take the k-nearest neighbours as per the calculated Euclidean distance.
Step 4 – Among these k neighbours, count the number of the data points in each category.
Step 5 – Assign the new data points to that category for which the number of the neighbours is maximum.
To select the k value that is right for the data, we run the algorithm several times with different values of k and choose the k that reduces the number of errors we encounter while maintaining the algorithm’s ability to accurately make predictions when it’s given data it hasn’t seen before.
What is Euclidean Distance?
In mathematics, a Euclidean distance matrix is an nxn matrix representing the spacing of a set of n points in Euclidean space. It is one of the most popular distance formulae that is commonly used in the domain of machine learning.
A distance function provides distance between the elements of a set. If the distance is zero, then elements are equivalent; else, they are different from each other.
The distance formula is shown as below:
dist((x, y), (a, b)) = √(x - a)² + (y - b)²As an example, the (Euclidean) distance between points (2, -1) and (-2, 2) is found to be
dist((2, -1), (-2, 2)) = √(2 - (-2))² + ((-1) - 2)²
= √(2 + 2)² + (-1 - 2)²
= √(4)² + (-3)²
= √16 + 9
= √25
= 5More information about this formula can be found in the article below.
There are, however, many different distance models, for example, Minkowski Distance, Manhattan Distance, Cosine Distance and Jaccard Distance.
Advantages of kNN
There are some notable advantages of this algorithm.
- It is simple to implement in any classification problem. Comparing to neural network-based classifications, kNN provides a more traditional and straightforward implementation.
- It is robust to the noisy training data.
- There’s no need to build a model, tune several parameters, or make additional assumptions.
- As the number of training data increases, the kNN algorithm can be more effective.
- Easy to implement in a multi-class problem: Other classifier algorithms are easy to implement for binary problems and needs the extra effort to implement for multi-class, whereas kNN adjusts to multi-class without any extra efforts.
- kNN can be used both for classification and regression problems.
Drawbacks of kNN
There are some notable disadvantages to this algorithm.
- It might be a little complex to determine the ideal value of k in this algorithm.
- The computation cost is high because of calculating the distance between the data points for all the training samples.
- The optimal number of neighbours to be considered while classifying the new data entry can be quite complex.
- The algorithm is very sensitive to outliers as it simply chose the neighbors based on distance criteria.
- If compared to Support Vector Machines (SVM), SVM outperforms kNN when there are significant features and lesser training data.
In Summary
Let us recap the article above. kNN algorithm assumes the similarity between the new case/data and available cases and puts the unique point into the most similar category to the general categories.
kNN works by finding the distances between a query and all the data points in the data, selecting the specified number of examples that is k, which is the closest to the data points, then performs classification.
It’s easy to implement and understand, but has a major drawback of becoming significantly slows as the size of that data in use grows.
In the case of classification and regression, we saw that choosing the right k for our data is done by trying several k values and picking the one that works best.
Are you looking for ways to get the best out of your data?
If yes, then let us help you use your data.
Related Posts
What is k Nearest Neighbour algorithm?
kNN algorithm assumes the similarity between the new case/data and available cases and puts the unique point into the most similar category to the general categories.
Why is the k Nearest Neighbour algorithm important?
Suppose there is a data point that needs to be categorized or classified into one of 2 classes, Class A and Class B. By using kNN algorithm, we can easily identify the class that this particular data point will go to
What are the advantages of the kNN?
It is simple to implement in any classification problem. Comparing to neural network-based classifications, kNN provides a more traditional and simple implementation.
What are some of the drawbacks of kNN?
If the training data is large, the computation cost is high because of calculating the distance between the data points for all the training samples