

Introduction
In today’s applications, Artificial Intelligence is often used as a synonym for Machine Learning which in layman’s terms means to train a Neural Network model to perform certain predictions by using specific algorithms. The Neural Network model is trained on a sample dataset, and once it has been trained, the model can be used for prediction, recognition, etc.
Commonly, this is called offline learning or batch learning which is the traditional way the neural network models are trained in Machine Learning.
It merely means that the model is only trained with the data it was provided and could only predict a similar type of data. Offline learning is more common in the industry as it is advantageous in many different ways.
Traditionally machine learning is performed offline, called Offline Learning, which means we have a batch of data, and we optimize an equation. However, if we have streaming data, we need to perform online learning, so we can update our estimates as each new data point arrives rather than waiting until “the end” (which may never occur)
Extracted from page 261, Machine Learning: A Probabilistic Perspective, 2012.
But, what if there is a continuous stream of new data that the model has to learn on the spot? – introducing Online Learning
What exactly is Online Learning?

In the simplest term, Online learning is an approach used in Machine Learning that ingests sample of real-time data one observation at a time.
Online learning models process one sample of data at a time – thus be significantly more efficient both in time and space with more practical batch algorithms.
There is no doubt that data are now rapidly expanding – in all domains. While the potential of these massive data is significant, making sense of them requires new ways of development and learning techniques to address the various challenges.
Online learning is usable for those problems where samples are presented over time and where the probability distribution of samples is expected to also change over time.
Therefore, the model is expected to change just as regularly to capture and adapt to those changes. This could be seen as an advantage in a specific industry where real-time personalisation is deemed crucial.
For example, having a personalised shopping experience where the model constantly learns the real-time user behaviour with an attempt to provide personalised shopping is crucial for every customer-centric business model.
Commonly, there are 2 ways as to how a Machine Learning model is trained:
- A model is trained on new and unseen data. If the performance suffices, the model is then said to be ready to be deployed.
- Scheduled training when there are newer data to optimise the model performance based on new unseen data.
The methods above have been the de-facto standard of how a model is trained and deployed in businesses or organisations.
However, with large amounts of new and unseen data that are being digested, the model has to learn how to adapt to the fluctuations and drifts of data in terms of quality, pattern types, features, etc. Only then the model is said to be robust to be deployed to the particular use cases.
There are tons of learning types in Machine Learning which is stated below. Keep in mind that there is definitely much correlation between all the methods as listed below.
- Supervised Learning – Model trained on a labelled dataset
- Unsupervised Learning – Model trained on an unlabelled dataset
- Reinforcement Learning – Models trained to take suitable action for the highest reward
- Active Learning – Models that trained with few active labels to achieve high performance
- Transfer Learning – Model is first trained on one task, then a part of it is deployed to another model for training
- Online learning – Model that is constantly updated by a real-time stream of data
Offline vs Online Learning

Model Training and Complexity
In an offline learning model, especially the training process, the weights and parameters of the machine learning model is updated while trying to achieve the global minimum cost function with the data it is trained on.
The model is constantly trained and updated repeatedly until it is robust enough for deployment and Big Data serving or any other use cases.
In an online learning process, however, the changes in the weights that happen at a given stage depend specifically on the (current) example being presented and possibly on the current state of the model.
In this way, the model is continuously seeing a new stream of data and improving itself (learning), which is why Online learning is data-efficient and adaptable.
Computation Timing
Generally, offline model training is much faster since the dataset is only allowed once throughout the whole model for the weights and parameters to be tuned. Offline learning is faster and cheaper.
It is used when you don’t expect the input to behave uncharacteristically.
However, the volume of modern Big Data Streams can make it quite time-consuming to feed all data into an offline model and it can be better to consequently update a model.
Thus, in online learning, the model must be ready to obtain and tune its parameters in real-time when there is a stream of data.
This may sometimes incur more cost and requires a lot more resources (cluster) to train the model constantly.
Use in Production
Online learning models are harder to be managed in production level stage after deployment. Since the model has to churn large amounts of the dataset in real-time, any changes in the pattern of data – or more commonly known as concept drift – will affect the overall performance and prediction of the data.
When the data starts to have an inevitable drift in terms of pattern or more, there will be a necessity to monitor the training all the time.
For example, a train will not be late all the time on all days and a changed customer behaviour changes delays. In fact, human concepts like Monday-to-Sunday result in a different traffic and train loading, thus resulting in different delays occurring, which causes certain drifts in the pattern of the data.
Offline learning, however, with the model being constant after the deployment stage (with same types and pattern of data), it is easier to maintain the whole network or cluster with minimal supervision and control.
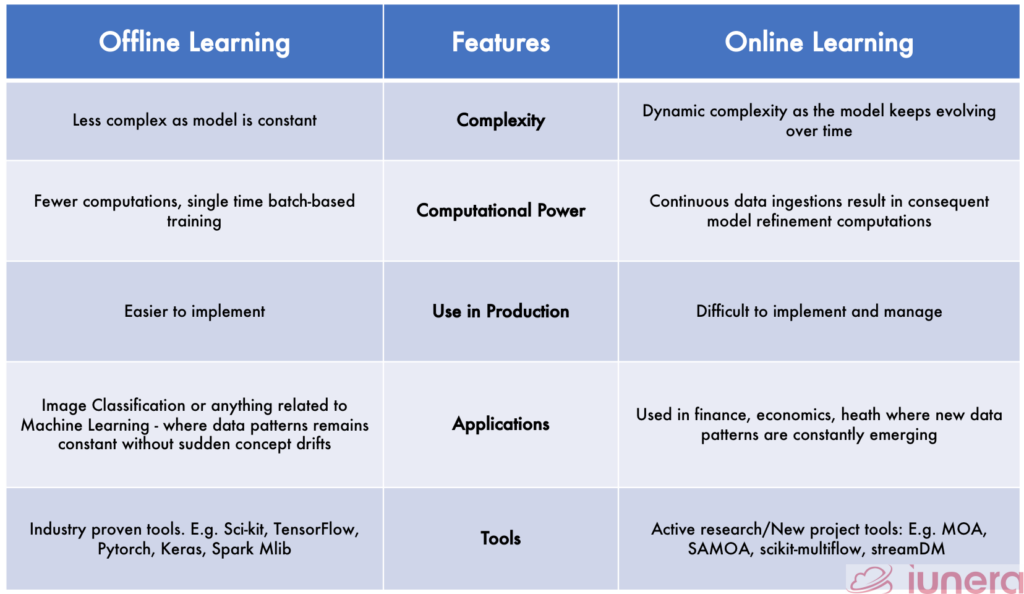
Short Summary
The reality is that – Different applications require different models and how they are supposed to operate. Offline learning and online learning are just the two examples that are shown here, but in reality, there are much more.
Often, offline learning models are much more straightforward to deploy and manage but less adaptable to the changes in data. Online learning models are more complex in the sense that they require more efforts and time since the new stream of data is continually being pushed. That requires all the preprocessing of data where it will take up more time and cost.
Model monitoring is a continuous process. If the model performance starts to degrade, then it’s time to restructure the model design to adapt to the continually changing dataset.
In production-level Machine Learning, the models should focus on delivering the correct information to the user or its application. The model should be as complicated as it needs to be, to accomplish these tasks, and exactly no harder.
Are you looking for ways to get the best out of your data?
If yes, then let us help you use your data.
Sum-up FAQ
What is Online Machine Learning?

In the simplest term, online learning is an approach used in Machine Learning that ingests sample data one observation at a time. Online learning is data-efficient and adaptable.
How is Offline Learning different from Online Learning?

Online learning models are constantly updated and tuned by the real-time stream of data, whereas offline learned models are trained only once with the same type of data.
When to use Online Learning methods in Machine Learning?

Online learning models are commonly used when the models need to learn different types of patterns in data, dynamically. This allows more personalised applications (e.g. dynamic E-commerce recommendations) containing dynamic model refinements.