
Challenges abound in Big Data-driven companies. Such companies commonly use three data source origins – first-party, second-party and third-party data sources – for Data Science investigations in the Big Data space.
In this context, the word ‘party’ refers to the individual or organisation involved in using and owning the data. The term data source refers to the location where data that are being used come from.
Data sources differ according to the purpose of the data and their type. Data source types include databases, files, datasheets, hard-coded data, scraped web data, and real-time streaming data.
For example, an online store of a fashion brand uses data from the inventory database to display the availability of a product. So the inventory database is the data source for the online store.
Regardless of the data type, different legal and logical data origins have different business purposes. Thereby, leveraging different data source origins enables different capabilities and benefits for an enterprise. We explain how first-, second- and third-party data sources differ and how they contribute value to a company.
First-Party Data
First-party data is basically your own data. Your company collects the data directly from your audience (site visitors, social media followers, customers, etc). It is the data that you own and where you have direct access to.
First-party data include link clicks, website visit/read times, bounce rates, sales deals, sales revenue, customer feedback, cost per click, and ad revenue. Such data are commonly found in your CRM database, which I would call a first-party data source.

First-party data is said to give the most valuable and reliable data to learn more about their current audience’s interests, traits and behaviours. Such first-party audience insights can then be used to predict future audience behaviour, improve marketing efforts, and personalise content.
First-party data is able to do this because of its availability, relevance, accuracy, security and cost-effectiveness:
- It’s readily available because it’s already being collected through your data management platform connected to your sales, CRM or website analytics system.
- It’s highly relevant to your company obviously because it’s your own audience.
- It’s accurate because it’s collected straight from the source. There’s hardly any distance between your company and the data source, so the likelihood of errors are minimised. Even if there were errors in relation to a particular audience member, you can easily verify them with the audience member yourself.
- Privacy issues can be managed more easily too because you know the exact data source.
- You don’t have to buy first-party data since you own the data.
Second-Party Data
Second-party data is your partner company’s first-party data. In the case whereby you’re collaborating with another company, the partner company gathers its own data and sells the data directly to your company.

Hence, second-party data would include the same first-party data, except that the data originates from someone else you agreed to partner with.
We know that first-party data is awesome but it’s not good enough, so second-party data can be used to make up for what’s missing in first-party data.
First-party data lacks information about what your audience does outside your website, what other sites your audience visits, what they view, buy, etc. Supplementing first-party data with second-party data can provide a panoramic view of the audience.
Second-party data is also high-quality, precise, transparent, gives access to niche data, allows for price negotiations and opens up opportunities to building a business relationship which can be useful in the long run:
- You know that second-party data is high-quality and precise because you know that you are buying the data from a reliable partner company. You can even verify the data with your partner company more easily.
- Working closely with a partner company allows you to get a lot of information about the data you’re buying, making second-party data so transparent.
- You can ask your partner company for a unique data agreement to get niche data. There’s also room for negotiations.
- Second-party data deals require interactions between your company and your partner company, leading to a relationship between the two. In such business relationships, you can go back to the same partner later on to buy more data more quickly and with better deals.
Third-Party Data
Third-party data is data collected by a company that has no direct connection to your company. Third-party data is also data collected by an aggregator from various sources and sold as a package.
The aggregators pay data owners for their first-party data, compile them into one large data set and sell it as third-party data. Examples of third-party data are panel/market data, legal data and financial data.

The importance of using third-party data lies in filling the gaps of the first and second-party data. Third-party data allows a company to scale beyond its current audience and expand its audience base to include more audience segments that could possibly be interested in your company’s offerings.
Third-party data also accounts for external events like demographic changes, geographical trends, economic changes and political events that may affect the company.
An exemplary use case for e-commerce
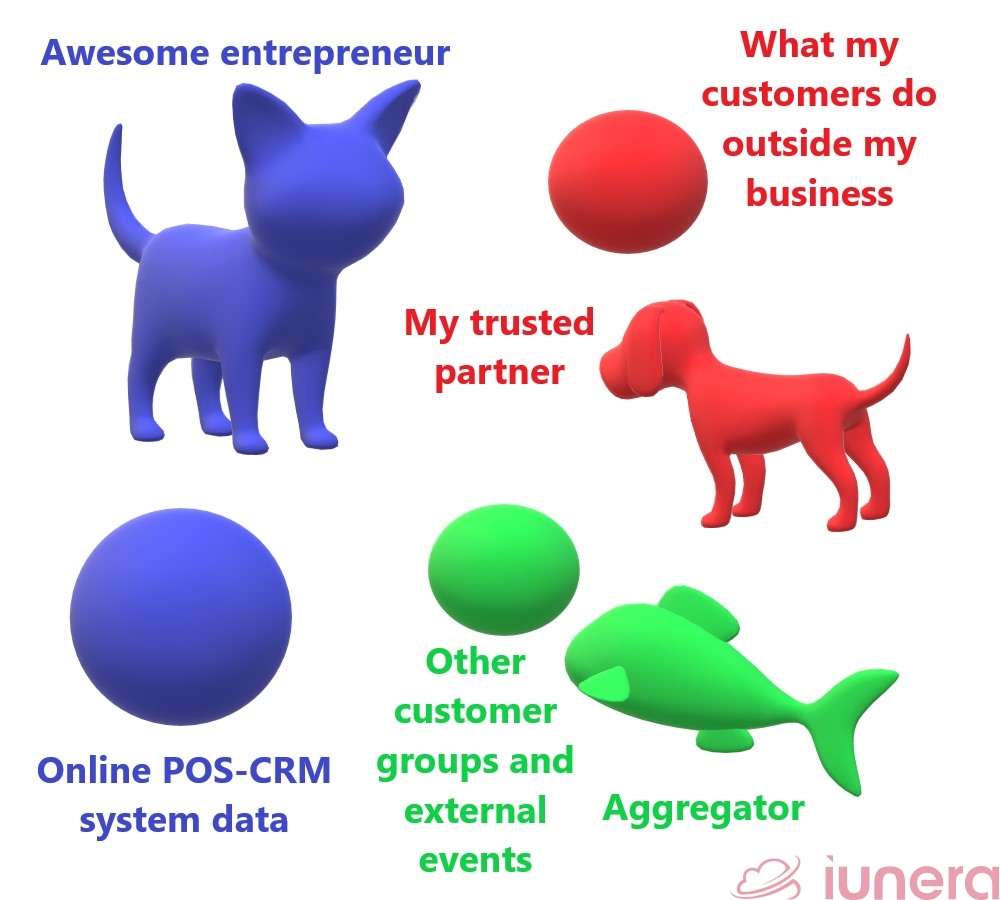
Let’s imagine that you are an awesome sustainable tiffin entrepreneur who manages an online store selling sustainable food containers for consumers and businesses.
First-party data
Your online point-of-sale-CRM system collects and stores data about your products for sale and the interaction of your website visitors/customers with your website. This data set is your first-party data as the data is owned by your tiffin company and collected directly under its control.
It’s good enough to tell you what your customers are like, whether your website is awesome for them, what sort of feedback they send, which products appeal to them, which products actually get sold, and anything else related to your online e-commerce store.
Such insights are easy for you to get and don’t require telling your accountant to add the acquisition of first-party data to the income statement since it’s readily available.
Second-party data
But it’s not good enough to tell you what your customers do outside your online store, what other websites they visit, what else they buy, and what motivates them to buy similar products.
Therefore, you can create an agreement with another company to use their first-party data as your second-party data for these insights.
Your partner can be a price search engine or an affiliate partner with whom you can sync details about other products customers are searching for.
Third-party data
You also want to know who else would buy your products to expand your customer base. In addition, you also want to see if there are social media trends and environmental awareness that can affect your business and how. This is the part where you buy third-party data from an aggregator to find out more.
Specifically, you use the data from your buyers group and match your buyer persona to the aggregator’s persona set. Then, you explore how the aggregator’s personas behave in general, where they are active on social media, which topics they follow and which other behaviours they have.
Ultimately, you leverage the third-party data to acquire new customers by advertising and reaching out on the respective channels to new customers who are similar to your already existing customers.
Buying third-party data comes at a price. But when you utilise and process it properly, then you can gain more for your investment.
One is never enough
As we can see from this example above, companies gotta catch them all. Companies reliant on data analytics can’t just use one data source origin just because someone says that one origin is the best or the largest.
Each data source origin has different uses, so the three data source origins are complements to each other, rather than substitutes.
In a nutshell, first-party data is useful for analysing the audience you currently have; second-party data is useful for learning more about your audience and strategising how you can retain them; and third-party data is useful for reaching out to more audiences and considering the impact of external events on your company.
Each data source origin fills the gaps left out by the other, so you can think of them as puzzle pieces. How the puzzle pieces look like and are fitted together depend on the company’s needs as no one company is the same. Thus, by using all three data source origins and leveraging their purposes, you reap their combined benefits.
Takeaway
What are the data source origins?

– First-party data
– Second-party data
– Third-party data
What is first-party data?

First-party data is the data you collect directly from your audience.
Why is first-party data important?
First-party data is very valuable and reliable because it is readily available, accurate, relevant, secure and cost-effective.
What is second-party data?

Second-party data is the data you buy from a partner company who collects from its audience.
Why is second-party data important?
Second-party data can show more information about your audience outside of your first-party dataset. The high-quality, precise and transparent second-party data gives access to niche data, allows for price negotiations and opens up opportunities to building a long-term business relationship.
What is third-party data?

Third-party data is mainly data collected from various data owners by an aggregator (who may have no connection with you) and sold as a packaged data set.
Why is third-party data important?
Third-party data fills the gaps of the first and second-party data by providing larger data sets of external audience segments and events.
What is the relationship between the data source types?

The data source types are complementary to each other.