
Big Data analytics are a set of concepts and characteristics of processing, storing and analyzing data for when traditional data processing software would not be able to handle the amount of records which are too expensive, too slow, complicated or not suited for the use case.
Hence, the concepts and characteristics of Big Data analytics commonly means ways of processing, storing and analyzing large volume data with additional means to traditional (SQL) databases.
There are many more fine grained definitions of Big Data out there. Some describe it by the characteristics of the Big Data and others define it by tooling and concepts of Big Data.
Therefore, this article answers the following questions about the concepts and characteristics of Big Data analytics:
- What are the main concepts of Big Data?
- Which are typical characteristics of Big Data solutions?

Modifed picture credits: Air force website
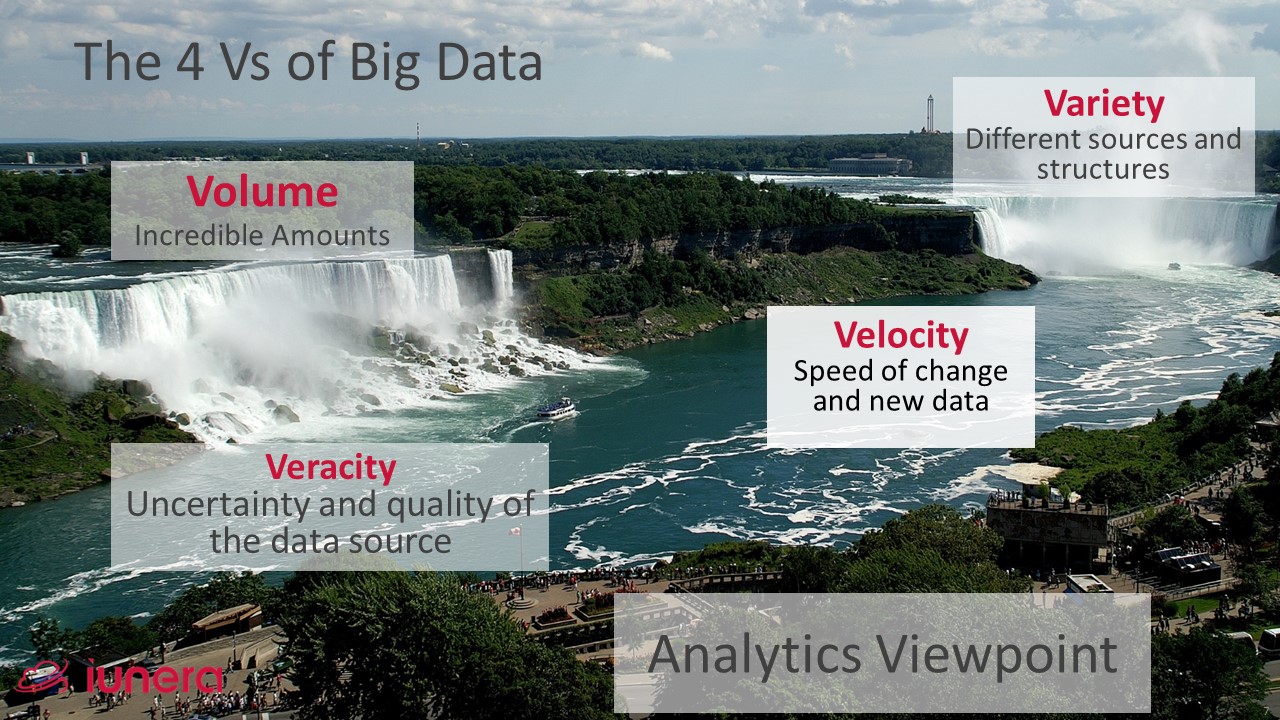
The 4V characteristics of Big Data Analytics
Big Data projects are conceptually very challenging for enterprises and fail often. Often Big Data are defined by 4Vs, or even more Vs, which are refered to as the Big Data challenges or at other times as Big Data characteristics. The regularly mentioned Big Data four Vs are:
Picture credits: Wikipedia
Big Data Volume
Characteristic is the immense Volume of data which is larger than the data that is processed in a normal enterprise system, which leads to newly designed systems. Reason for the immense amount of data are different developments.
One reason for the Big Data amount is that, the data of different IT systems are merged with what multiplies the amount of data. Alternatively, thrid party data might be procured or extracted by a crawler with the goal to merge it with own systems.
Veracity and truthfulness of data
The ingestion and the processing data of different systems leads to Veracity challenges about the accuracy of data and is another key characteristic of Big Data. Imagine there are different records showing the same data and they differ in the date timestamp. Which record is the truthful one?
Alternatively, data might be incomplete and one does not know that the records are incomplete and there was a system error. Hence, Big Data Systems need concepts, tools and methods to overcome the veracity challenge.
Variety of data types and data sources
In addition to the different source systems, Data which were not logged and overriden before can be stored in Big Data scenarios. Such data are like change histories, record updates and the likes which can enable new use cases like Time Series Analytics which are not possible on old overriden data.
There are new data sources which produce immense amounts of data. Most simplistic versions of these are social media data or data from smartphone apps which produces new insights of customer interactions.
Characteristic in call cases is that the Varity in these data is very different from another, It is from unstructured social media text data to structured operative enterprise system data. The variety can go over Time Series commit logs, computable financial time series data, and end up in app usage- and semi-structured customer interaction data.
Big Data landscapes and systems face the challange to handle this different data and to enable users to merge it together, where it makes sense.
Velocity challenges Big Data processing concepts in
Aside all of the prior mentioned data sources, IoT data is countinously increasing and future business models of enterprises are depening on IoT data.
IoT data and new data sources like social media, consumer apps, Time Series Data and increasing data in the supply chain are generating a increasing speed in data generation.
Data generation cannot be solely seen as static records in a database anymore and a new viewpoint of data as continous stream is necessary.
This leads to new questions of data storage, but also in computation and reaction to events in the data streams. Batch processing that is sufficient for a large volume of data does not copy anymore with an increasing Velocity. Therefore, modern Big Data Analytics Landscapes need to be able to store fast data quickly, but to also execute computations and movements of data in an efficent way.
What are Big Data concepts?
There are also very often concepts of Big Data Analytics software, landscapes and tool combinations, addressing scalability, functionality, differing from monolithic software.
Big Data Clusters
A typical concept of Big Data software is designed to run in clusters with different nodes. Clusters of different Big Data processing or storage tools are desinged to be failure tolerant and offer scale-out capabilities to gain performance or storage almost in linear when adding new nodes.

Clear CAP focus
Science dictates that when a system is constructed, we can only focus on two of the following attributes:
1. Consistency:
Wikipedia /
Every read receives the most recent write or an error
2. Availability:
Every request receives a (non-error) response, without the guarantee that it contains the most recent write
3. Partition tolerance:
The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes
Armando Fox and Eric Brewer, “Harvest, Yield and Scalable Tolerant Systems”, Proc. 7th Workshop Hot Topics in Operating Systems (HotOS 99), IEEE CS, 1999, pg. 174–178.
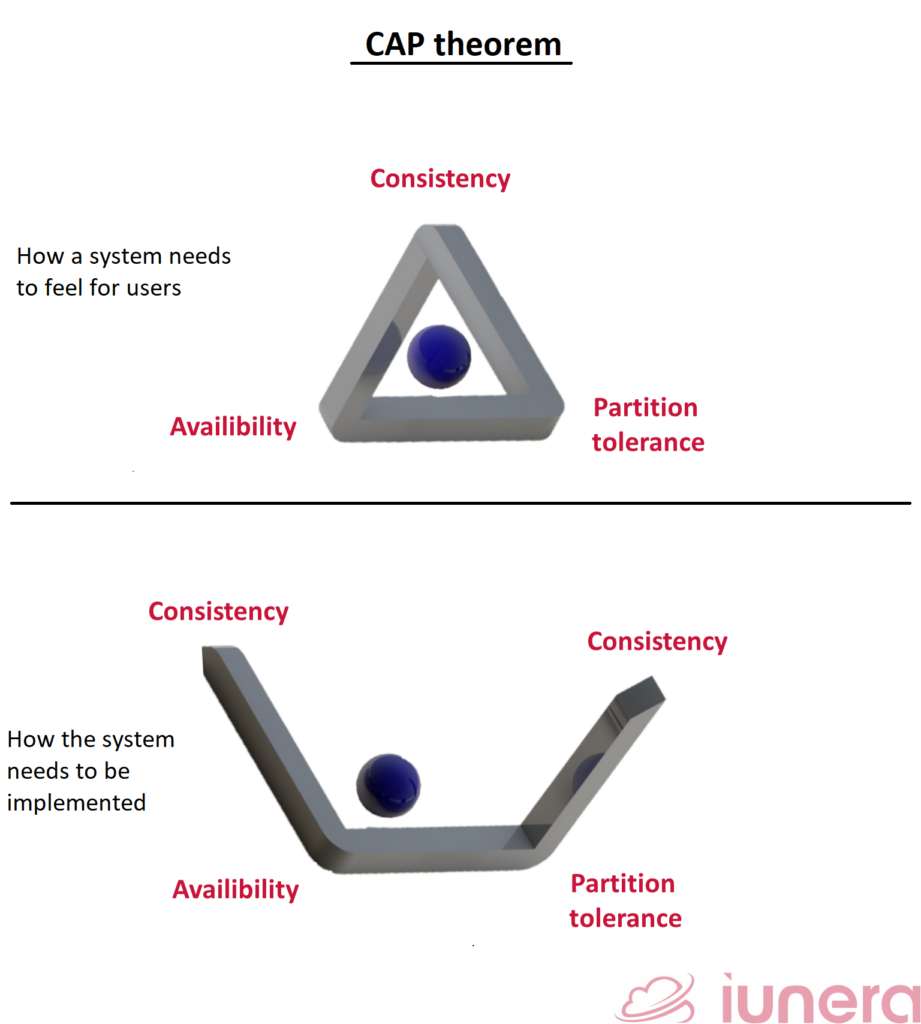
Picture credits: Modified triangle from Philippe Put
Big Data tools are normally aware of this choice and predecide in tool architecture for partitioning and evantual consistency or let the user decide between consistency and availability.
For instance in Kafka, a partitioned message broker. Kafka installations can decide via configuration if they take availability or consistency as second concern. Depending on the use case decistions can be made between the tradeoffs between eventual consistency and availability.
Big Data architects and engineers need to design system with various tools then that query tools like a Time Series Database will focus on availability and partitioning to scale well for queries. Storing data is done in a transactional way where the heavy computations data integrations are offloaded into offline processing.
Ingestion as concern
Merging and analysis data out of different sources is canother concept Big Data analytics. Thus data transfer, extraction, cleansing, transformation and integration play a central role.
A key reason as to why ingestion is a major concern in Big data scenarios is because the Big Data landscape viewpoint differs from the pure relational world.
A record is percieved as one represtation of reality and it is abolutely natural to keep a copy of a transformed record in another application. Once an original record is updated the transformation is re-executed and then the application with the transformation will also have the update.
This way, one gains scalability for some consistency and data can be pre-processed in the format which an application can work best with it. Easiest to imagine that is when one thinks of the Big Data version materialized views from the SQL.
For example, Druid, a Time Series Big Data database allows data ingestion over various channels. Thereby, one can ingest the same data multiple times into different querable aggregates.
Imagine you ingest delays of public transport multiple times for different scenarios. One sceneario could be histograms on a day foundation whereas another scenario where the same data is ingested computes aggregates of delays of different lines at specific hours. The data would this way be ingested twice and the query performance would be optimal for each “materialized” transformed data view.
In other cases there are often additional solutions in form or processors for batch ingestion in Big Data landscapes like Apache Nifi. Those read the data, transform it and then store it ultimately in a new format or another database.
Alternatively, stream processors like Apache Samza, Apache Flink or Spark Streaming which are available can transform and process data not only in batch but also near real time in a scalable way when it is popping into a message queue. Those direct transformations or processes can then be stored in a Data Lake, especially Big Data Databases or processed as events to lead to immidiate reactions.
Functional programming style
Big Data infrastructures and tools are often concepted and implemented in a way that they support higher order functions from functional programming as first class citizens.
The application functional programming concepts for the benefit of Big Data is, among others, increased scalability and better testing.
For instance, a very well known higher order functional programming construct used in Big Data is MapReduce.
MapReduce is a programming model and an associated implementation for processing and generating big data sets with a parallel, distributed algorithm on a cluster.
….
MapReduce is useful in a wide range of applications ….inverted index construction, document clustering, machine learning…
https://en.wikipedia.org/wiki/MapReduce
Aside MapReduce, widely applied Big data processing frameblocks like Spark or Flink are built on functional programming languages like Scala and can be used for Big Data analytics.
Are you looking for ways to get the best out of your data?
If yes, then let us help you use your data.
Sum-Up FAQ
What are the often named Vs of Big Data analytics?

Volume, Veracity, Variety, Velocity
What are typical characteristics of Big Data solutions?

Cluster based sofware
CAP focus
Data ingestion interfaces
Functional programming style
What is the CAP theorem in Big Data?
A system cannot ensure consistent data, availability and partition tolerance at the same time.
What are typical features of Big Data Clusters?

– Many equal nodes
– Scale-out architecture
– Active-active design
– Auto-failover
– Auto-leader election
– Checkpoints
– Fault-tolerance
– Auto-recovery