
There is a lot of hype on Data Science; that said, what exactly is essential to know for Data Science and who are Data Scientists? What are typical Data Science techniques? Which methods and tools do Data Scientists use? Which programming languages and infrastructures are most important in Data Science? We provide brief applied answers which is commonly understood as Data Science, what a Data Scientiest does and which common Data Science tools, methods, techniques and programming languages are used.

What is Data Science?
Data Science is a mixture of Computer science, and math applied in a specific business domain.
The above is an abstract definition in pratice, but in more simple words:
The goal of Data Science is to investigate data and to refine concrete enterprise value out of the data.
Logically, Data Science is an interdisciplinary field.
- One one end, it’s a domain expertise of the enterprise business processes and data is required to do Data Science for the benefit of an enterprise.
- On top of that, someone who understands some fundamantals of data processing and computer science offers benefits.
- Lastly, data understanding and math skills are needed to interpret causalities and assemble statistics.
What does a Data Scientist do?
Data Scientists utilizes the data within an enterprise and support the business units in their decisions and plannings with actionable solid data foundations.

Then, a Data Scientist assembles the necessary data together to try and come up with data underlined business solutions and proposals that can help to tackle these challanges.
Data Scientists therefore loosely follows scientific methods.
- First, Data Scientists generate a theory/hypothesis
- The data which to test the hypnothesis is acquired
- The acquired data is analyzed
- Ouf the the analysis further data needs to be acquired or tested
- Conclusions of the data analysis are communicated and fact based enterprise decisions are made.
Often reality influences this process and the time spent to process the different tasks is not spread evenly.
Commonly, 80 percent of the work time of Data Scientists is spend for data preparation and acquisition.
Often data is available in an and Data Scientists spend most of their time in finding, cleaning and reorganizing huge amounts of data.
The analysis normally takes only a fraction of a Data Scientists’ time.
Logically, it is important to note that Data Scientists know how to work with different tools which support them in reorganizing, cleaning and analyzing data.
Notebooks for Data Wrangling
Data Science notebooks are web-based interactive development environments where code, data and processing results are mixed. One can also call them a Data Science Workbench.
The most known Data Science notebooks are Apache Zeppelin and Project Jupyter.
Notebooks allow Data Scientists to mix Python, Java and Scala code and to process, access and transform data. In addition, Data Scientists can visualize data easily in a notebook.
The notebook approach is that there is code in one language in one section. The code of a section can also show a result in the form of tables or data visualisations.
In the next section the other code is added and the result of the processing of the prior section can be accessed if need be.
The notebooks support adding different interpreters of different lanuages and also frameworks and can also be connected to do the computations in the backend clusters of the different frameworks.
This makes notebooks a powerful tool which Data Scientists can transparently wrangle data.
Data Science notebooks makes it easy and seamles to develop documented and visualized investigations which can be easily repeated and just re-run all the code form the notebook.
Visualization and presentation
Typical work tools for Data Science are ways to present and understand the reserach results in a graphics.
In short, Data Scientists would like to present their catch to everyone.

Picture credit
The most known Data Science tools for this are the use of previously described visulalisations in Data Science notebooks and using special dashboarding and analysis software which can connect to different data sources.
The two most likely well known dashboarding softwares in Data Science are QlikView and Tableau.
, do not offer an open source version, but they are widespread in the industry.
In the open source world, there are also other different solutions available such as Metabase, Superset.
Metabase allows to query different datasources and to answer and share questions about the data, whereby an Apache Superset enables users to build and share complete professional dashboards.
In addition there are visualisation tools like Grafana which enable to create complete monitoring dashboards. Ultimately, those monitoring tools like Grafana are used for cases where it is necessary to monitor the most important findings of a Data Scientist to continously allow fast business reactions.
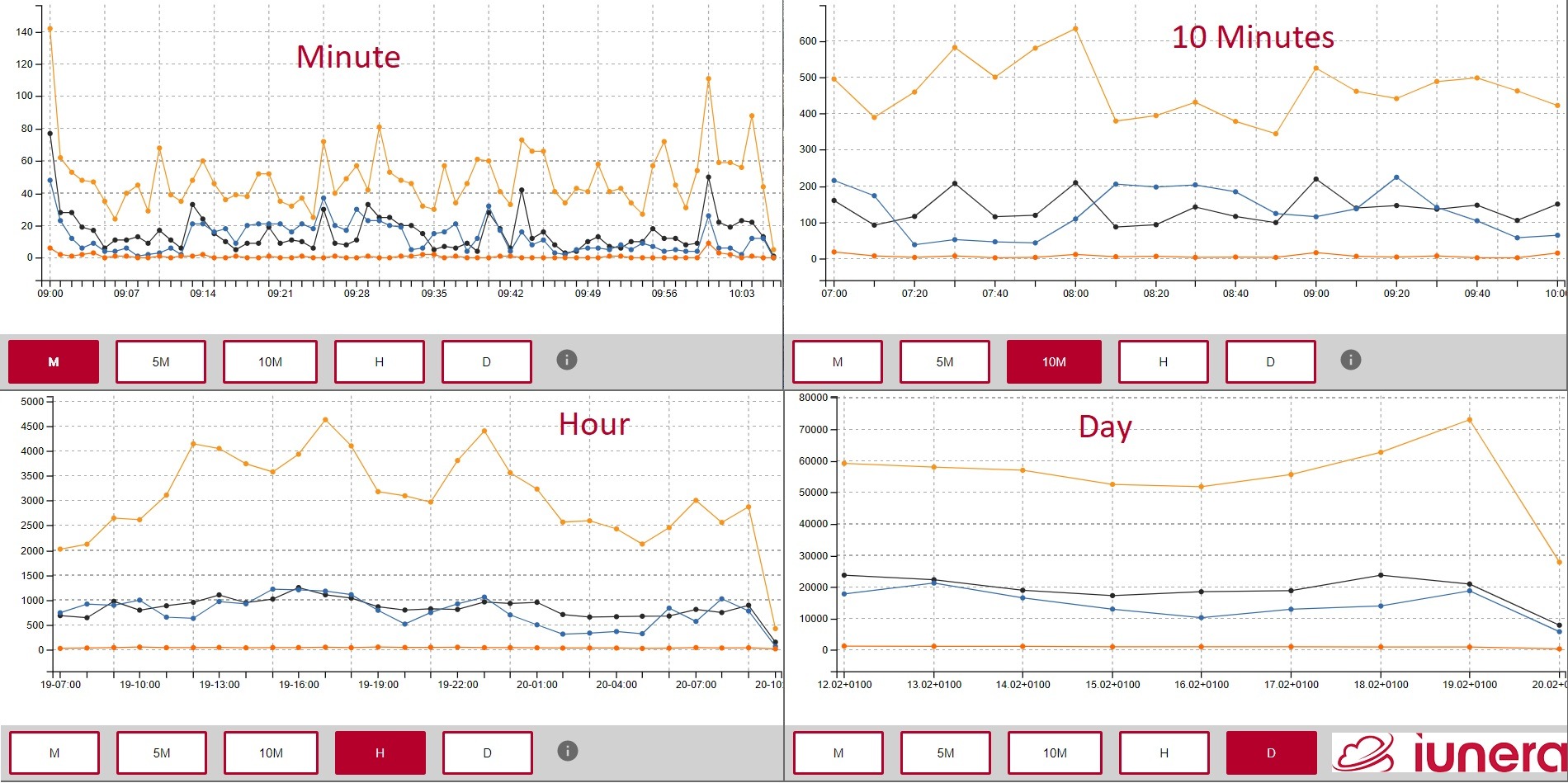
After all, there are plenty of visualisation tools and possibilities which differ in their features, advantages and costs.
In case you believe that we’ve missed out on your most important tool for Data Science, let us know via message or comment.
Rigorous Data Science methods
In order to derive conclusions, a Data Scientist uses different rigorous scientific methods to extract proper value of data.
Hence, fundamental statistic knowlege is applied to ensure a rigorous and truthful interpretation of analysis results.
Pratices like the application of
- statistical hypothesis tests,
- factor analyis,
- statistical inference,
- histogram based analysis,
- regression analysis
and other foundation knowledge of statistics education ensure that analysis results are interpreted and communicatied according to proper standards.
Data Scientists apply these standards and underlying scientific methods. This ensures that correlations are not accidently interpreted as causalities and business decisions can be made based on proper data interpretations.
Programming languages
Commonly, Data Scientists work with different languages.
Python
The most common Data Science language used these days in is Python.
Python is a Turing-complete purpose programming language. Python is a multi-paradigm language and allows coders to program in different styles (imperative, object-oriented, functional, declarative). This way a coder can start with one style and then switch later on to other styles.
Python is popular because it is well designed and has established general-purpose language which seems for most Data Scientists who do not origin a Computer science class easy to learn.
In addition, Python, as a well establised bridge to invoke C/C++ code, and this makes it possible to write high performance code directly in C/C++.
Last but not least many machine learning and deep learning libraries like Keras offer easy integration in Python scripts.
An easy to use packing system and plenty of ready-to-use libraries and infrastructures like prior mentioned Keras and other artifacts and algorithms from the newest research make Python a simple entry point to learning machine learning and AI.
In enterprises, Data Science Phyton is often used in conjunction with Spark a large scale data processing framework/infrastructure, running on the Java virtual machine. This is then called Pyspark.
Together with Scala, Java, and R, Python is one of the de-factor need to know standards in the Data Science and Big Data industry.
Like any other programming language being effective in Python comes with programming experience and mindfulness.
The downside to Python is that some data processing frameworks like Apache Spark are written in other languages (Scala) and there Python loses its advantage of being fast and slows down out of integration challenges.
In the special case of Spark, Python is not running on the Java infrastructure and calling Python from Java or vice versa can lead to performance bottlenecks.
Furthermore, a lot of legacy programs and systems are written in Java what creates challenges in integration Python into productive landscapes.
Last but not least, Python focuses on multiple programming paradigms and scripting makes larger programs often hard to read when the coder is not experienced enough to structure the code sufficiently.
Nevertheless, Python has a lot of ups and also a lot of benefits, and that makes it a must-know for applied Data Science.
R-project
R is not a general purpose programming language and focuses directly on statistical functions and plotting data views. This makes it very well suited for Data Science.
Depending on the application and on the amount of data, the R programming language is slower than Scala or Python. Nevertheless, several features still make R a very good candidate for data wrangling.
For example, the R project also allows to mix data directly into the programming language. The feature of mixing data is very different to other languages but also allows beginners a quick beginning.
A special thing about it is the packaging system, where extensions for visualisations and analysis models can be written and consumed easily. Data Scientists have access to over 15,000 packages for visualisations, models, time-series and geo-spatial coordinates. This creates a luxurious problem of finding the right extension with the required quality for the right task.
This therefore becomes the strength of the R programming language as well as its weakness at the same time.
All in all, the R language is a powerful Data Science tool to investigate data with statistical methods and to gain overviews and visualisations, quickly.
Scala / Java
Scala is a complete functional programming language which runs on the Java virtual machine. This makes Scala artifacts invocable from Java which is already widespread in enterprises.
The immense advantage of Scala is that many data processing frameworks in the Big Data and Data Science area are written directly in Scala.
This makes it very often much more simple to interface with the data processing frameworks when consuming their native interface directly in Scala.
Java lambda expressions make Scala code of frameworks accessible with a bit of boilerplate code and this allows a decision to use Java for many tasks instead of Scala.
This accessibility from Java is highly relevant, because the Scala developer pool is limited and the syntax and readability sometimes seems strange for Java developers.
Furthermore, the Java virtual machine infrastucture makes it possible to use all devops and continuous devlivery pipelines which are normally already existing in enterprises.
Therefore, the Java connection of Scala needs to be credited as a Scala feature.
Compared with Python, Scala often takes lesser lines of code and therefore less lines of “may-existing bugs”, when programming Spark with Scala in a functional way.
In addition, Python is easier to learn and code from Data Science beginners will look more clean.
On the other hand, the Scala/ Java combination has other advantages. For example, when Spark code becomes many times faster when executed in Scala than when consuming it from Python.
A likely major problem for mass adoption, in contrast to Python is: The Scala documentation is written in a very academic way. This makes it hard to read for non-computer scientists and Data Scientists who have just begun coding.
Roughly spoken, Scala is mostly designed to attract professional programmers who already have knowlege in another langauge whereby Python and R are easier to get started with.
Be it hard to learn or whether academic or not, Scala or using Scala code from Java is sooner or later always a topic for Data Scientists.
Commonly, the need for Scala comes up out of the following reasons:
- Processing data volume grows
- Performance of other lanuages is too slow
- Productization and integration into continous development pipelines need to be defined and a Java infrastuctre already exists.
Machine learning
Once the data quality is secured through data warning, Data Scientists often do artifical intelligence in the form of machine learning to gain more value from the data.
A simple example for this are text recognition, clustering, recommendations anomaly detection and more.

Machine learning in Data Science is all about applying algorithms to learn patterns in data. Here, we show the most common ones briefly.
Supervised learning algorithms can be trained with behaviours which manifest in data and then predict outcomes for new records which are similar to other data.
One example is to use machine learning mine patterns and features which customer groups are willing to buy products for a higher price.
Unsupervised learning reveals patterns in the data. It makes it possible to find clusters within datapoints or to find anomalies.
A practical example for such clusters can be persona mining. Thereby, an algorithm can group customers data points (e.g. age, buying time, country, products, price…) into clusters with similar behaviours. The knowlege from these clusters can then be used to refine personalize offers.
Deep Learning is currently a huge trend in Data Science. Thereby different types of artifical neuronal networks is trained with huge amounts of data. Thereby, these neuronal networks can be used for Unsupervised and supervised learning.
Deep learning is in special hyped together with Big Data, because of the data volume and that is needed to train the neuronal network.
In addition to the immense data amount, powerful clusters are needed to train the network. Therefore, a Big Data landscape often servesthe necessary infrastructure for Deep learning in forms of clusters or the training is excuted in a scalable cloud environment.
All in all, different learning techniques and algorithms have advantages and disadvantages and, it depends on the use case and data quality on which meachnism works best.
For instance, neuronal networks need a lot of data whereas other learning techniques work often with lesser data. Different use cases need to be supervised, semi-supervised or unsupervised learning and it is ultimately up to the Data Scientist to find the right method for the right problem.
Typical Data Science infrastructures
Data Scientists and work with as infromation foundation.
Therefore, it is hard to discriminate from Data Science tools and it is would be more accurate to speak about methods and tools.
Logically, it is very common that Data Scientists ordinarly have a Big Data infrastructure for Data Science investigations at hand.
Often this infastructure offers scaling computation and storage capabilities.
Data Lake storage
Typical is the existence of a data-lake that is often realized in the form of apache-hadoop.

A Data Lake is a distributed system where raw, structured and unstructured data is stored. All data can be stored in this Data Lake for further exploration.
Hence, Data Lakes are commonly designed that fields can be imported from all enterprise, be it internal and external systems.
Therefore a data-lake is the system where a Data Scientist starts the data wrangling journey.
Data Scientists use the data from the data-lake to perform Data Science activities on it. Those Data Science activities can be to process, analyze, clean, refine or to transform the data.
Big Data Processing engines
Data Science requires a lot of data processing like joining, cleaning and transforming.
Data processing engines offer functionality to scale computations and data transformations on a cluster horizonally.

A simple way to do that is a Map-reduce, but nowadays there are more complex frameworks avilable which offer plenty of out-of-the-box functionality to do more complex and common transformations with less code.
Often, there is a Apache Spark cluster for data transformations and processing.
Spark is an open source framework and is written in Scala. A Spark cluster supports streaming data processing, machine learning, graph processing and a special SQL layer to query processed data easily with queries.
It is noteworthy that there are also other processing engine clusters like Apache Flink available.
Flink for instance, offers similar functionality to Apache Spark, but is designed with a newer Java API and a special focus on processing streaming data, but it has a smaller community.
In summary, different data processing clusters offer different functionalities and interfaces for different programming languages; there, it depends on the concrete use case which processing cluster serves a use case best.
NoSQL – Specialized Datastores
In order to query and process Big Data often large file storage systems are used.
In addition to those generic purpose storage systems, often specialized databasebases are available to ease data handling.
Those go from columnar database management systems to key value stores, Graph Databases, Time Series Databases and other specialized engines.
Machine learning cluster
Training machine learning can take a long time. For instance, big volume data or the need to train many machine learning models at the same time can introduce the need to scale a parallelize training and application of machine learning.
In special, deeply layered neuronal network based machine learning techniques needs plenty of computation capabilitities for model training what would end up in weeks or month training on a single computer.
it is because of this reason, Data Science infrastructures often contain scalable distributed machine learning training clusters or on-demand training cloud services for Data Scientists.
Are you looking for ways to get the best out of your data?
If yes, then let us help you use your data.
Sum-up FAQ
What is the goal of Data Science?
The goal of Data Science is to investigate data and to refine concrete enterprise value out of the data.
What are the three skill areas of Data Scientists?
– Business domain knowlege
– Fundamantals of data processing and computer science
– Math skills to interpret causalities and to assemble statistics
What are Data Science notebooks?
Notebooks are web-based interactive development environments where code, data, visualizations and processing results are mixed. Popular examples are Jupyter and Zeppelin Notebooks.
What are Data Science notebooks used for?
They are a transparent tool to wrangle data and to develop documented and visualized investigations which can be easily repeated just by re-running all the code from the notebook.
What are typical Data Science backends?
– Data Lake
(e.g. Hadoop)
– Data processing engines
(e.g. Spark, Flink clusters)
– NoSQL (Specialized Datastores)
(e.g. Apache Cassandra, MongoDB, Apache Druid, OrientDB)
– Machine learning clusters
(e.g. Deep learning training clusters for Tensorflow and PyTorch)
What are examples for data science visualization tools
– Apache Superset
– QlikView
– Tableau
– Metabase
What are Data Science methods?
Rigorous scientific and mathematical methods. For example the application of statistical hypothesis tests, factor analyis, statistical inference, histogram based analysis, regression analysis and other mathematical pratices which is used in research. The application of these scientfic methods ensures that analysis results are interpreted and communicated according to proper standards.
What are the most important Data Science programming languages?
– Python
– R project
– Scala / Java
What are some common Data Science machine learning techniques?
– Supervised learning
– Semi-supervised learning
– Unsupervised learning
– Reinforcement learning
– Deep learning