
Immense data streams from various origins help businesses to make important data-driven decisions, upscale profits, and to harness new opportunities. Hence, more enterprises have the need to apply online machine learning to react directly to events in Big Data streams.
We discuss how special Online Learning Support Vector Machines (SVM) differ from ordinary offline SVMs in Data Stream mining and how they can be used for Big Data analysis.
Introduction
It has become more important than ever to understand how Big Data can be valuable if used properly. The amount of data created each year is growing faster than ever before. Everyone is trying to change and develop ways to understand data better in a more efficient way. Hence the question is –
“How can businesses leverage data to make a valuable decision”
- Expense Reduction – Big data tools and cloud analytics bring significant cost benefits when it comes to storing massive amounts of data. They help to guide and distribute data efficiently
- Effective Decisions – Companies are able to recognise the underlying pattern of data to make important and clear-cut decisions
- Competitive Advantages – With Big Data analytics, organisations can predict the market trend to capture it early on before the rivals
- Personalised Products – Able to assess customers needs to accommodate customers with what they want
These stated above are just some of the advantages that organisations can attain from the power of Big Data. With Machine Learning, however, the acceleration and impact of data are tremendous.
Extensive and large calculations done over existing datasets in a Neural Network cannot be implemented over a traditional approach. The workaround is to implement distributed computing using Big Data technologies like Apache Mahout, Spark, R-Hadoop to feed output to Machine Learning algorithms for its applications. This is where Machine Learning meets Big Data.
In a Neural Network, traditionally the model is trained using datasets that are sampled from a pool of data and then deployed into production. This is called Offline learning. In Big Data, however, data is rarely ever constant and is instead continuously changing its patterns and trends.

Offline Learning SVM
SVM is a supervised Machine Learning algorithm that is used in many classifications and regression problems. It still presents as one of the most used robust prediction methods that can be applied to many use cases involving classifications.
SVM works by finding an optimal separation line called a ‘hyperplane’ to accurately separate 2 or more different classes in a classification problem. The goal is to find the optimal hyperplane separation through training the linearly separable data with the SVM algorithm.
As for offline SVM, there are 2 types of classifiers namely –
- Linear Classifier – Where a straight-line function can be drawn to separate all the items in class A and class B
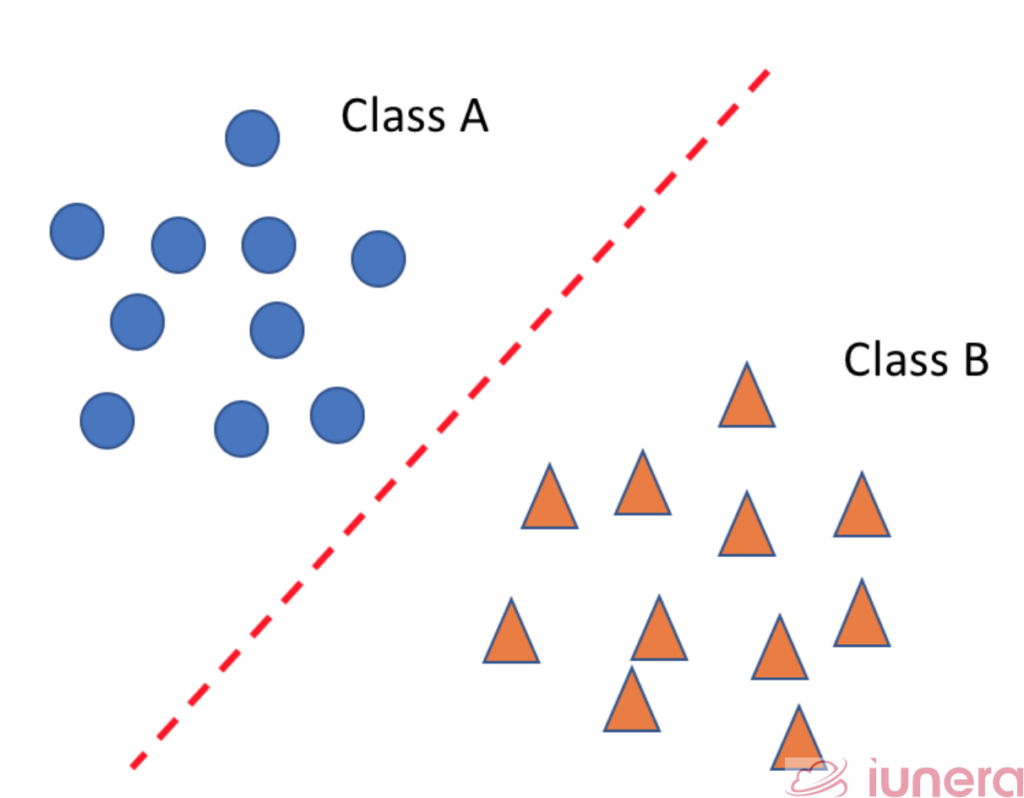
- Non-Linear Classifier – The mapping of the original feature space to some higher-dimensional space where the training set is separable using a special kernel function.
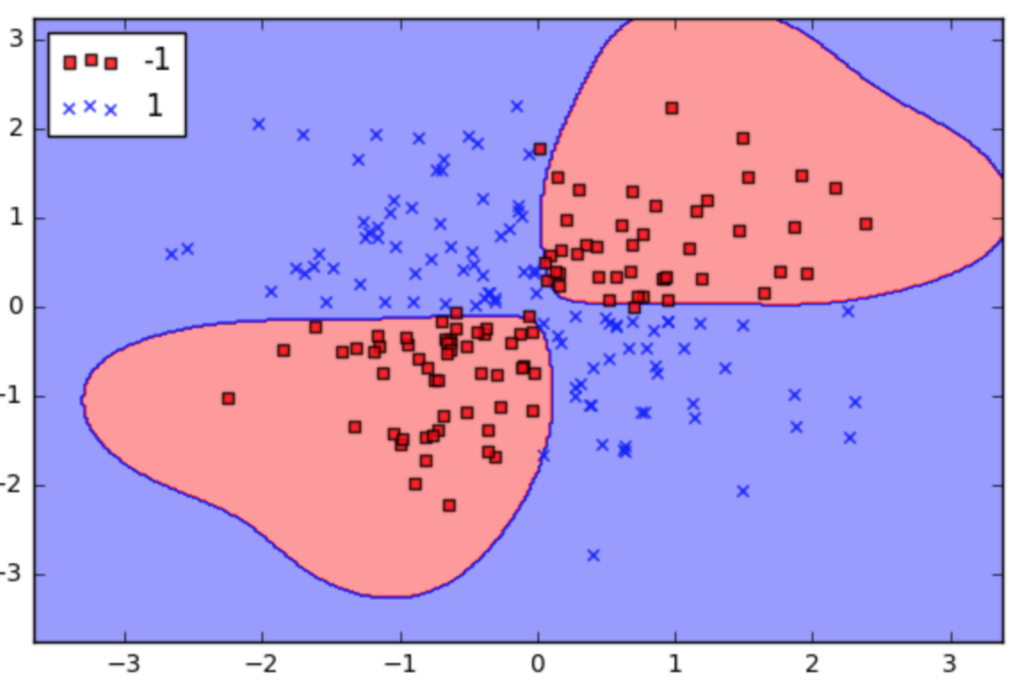
In offline SVM, the algorithm is trained on data that is not continuously changing. But what if the data being streamed is of different patterns and happens in real-time? This is where active learning SVM is important.
Online Learning SVM
In Active learning SVM, the assumption is that the SVM algorithm is not trained on only 1 sample of data, but is continuously being trained with real-time data observations coming in periodically.
One of the most popular active learning SVM algorithms is called LaSVM. LaSVM is a Big Data stream mining algorithm developed by Bordes in 2005 which incorporates the workings of Support Vector Machines but with online kernel classifiers.
The algorithm uses the traditional SVM (Quadratic Programming) solver with online kernel approximation by using the similar single sequential pass method used in SVM.
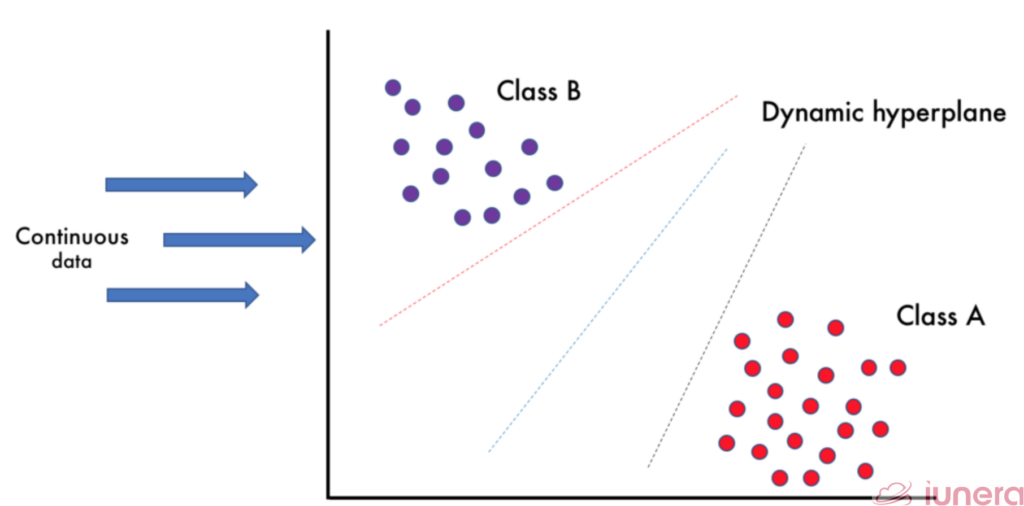
When real-time data is fed into LaSVM continuously, the algorithm finds out the correct label using the trained model at that point of time.
It then updates its hyperplanes, if necessary, based on the new inserted samples. This characteristic of LaSVM makes it suitable for dealing with big streaming data.
LASVM can be used in the environment with a real-time setup where the model is given a continuous stream of fresh random examples. The online iterations process fresh training examples as they come. There are more advantages of active learning-based SVM in regards to current Machine Learning applications.
How is it different?
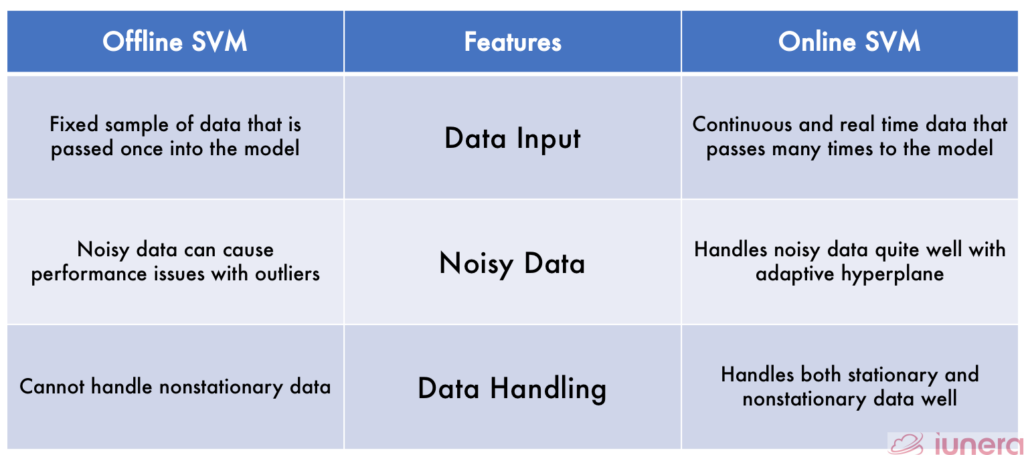
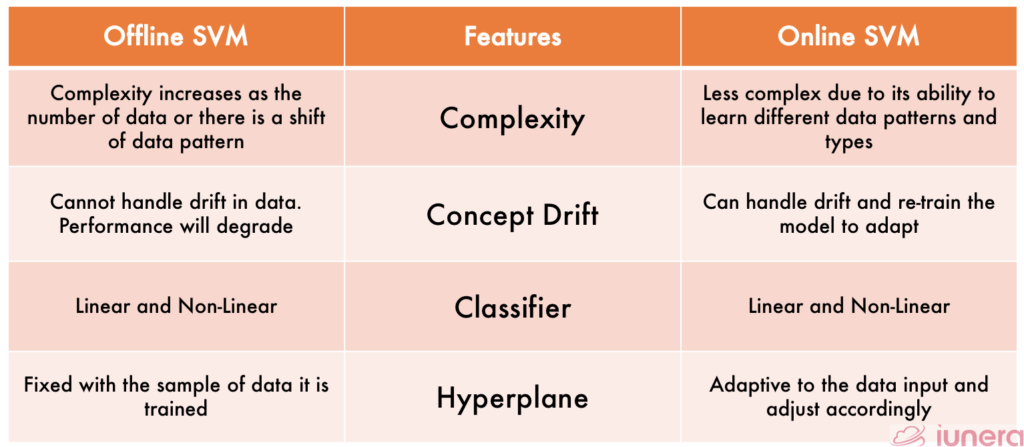
Although both Offline and Online SVM can be used for any application, it depends on the types of data that are being given. A constant data will be the option for Offline learning, whereas a continuously changing data will be most suitable for Online SVM. Below is a detailed comparison table between Online and Offline SVM.
Data Types
Model Features
Final Thoughts?
The use of Offline or Online SVM ultimately depends on the applications. The above table summarises the different features both algorithms exhibit, and from there it can be decided on which algorithm is the most suitable one.
But in a general sense, offline learning models are much more straightforward to deploy and manage but less adaptable to the changes in data.
Online learning models are more complex in the sense that they require more effort and time since the new stream of data is continually being pushed. That requires all the preprocessing of data where it will take up more time and cost.
Support Vector Machines is a huge area of study. There are numerous books and papers on the topic. Listed below are some of the resources that can be referred to dive deeper into the algorithm itself.
Offline Support Vector Machine (SVM)
- Introduction to Support Vector Machine – Andrew Ng, CS559
- Support Vector Machines for Classification – Raj Bridgelall, PhD, Lecture
- Linear and Non Linear Classifier – Medium, TowardsDataScience
Online Support Vector Machine (SVM)
- Active Support Vector Machines (SVM) – Andreas Vlachos, University of Edinburgh 2004
- Fast Kernel Classifiers with Online and Active Learning – Antoine Bordes, NEC Laboratories America
- Incremental Support Vector Learning: Analysis, Implementation and Applications – Pavel Laskov, Fraunhofer-FIRST.IDA
Are you looking for ways to get the best out of your data?
If yes, then let us help you use your data.