
Big Data streams have become so important because a large number of applications generate a massive amount of data at an incredible velocity, large volume, variety, and with unknown veracity. Big Data streams from various sources help businesses to make critical data-driven decisions, upscale profits, and harness new opportunities. But these rely on the processing techniques used to enable real-time Big Data stream processing such as event processing, pattern modelling, pattern queries, etc.
In this article, we will discuss Complex Event Processing and the tools that can be used, and how it is used in event processing for any applications.
Introduction to Event Processing
Event processing is a computational method to track and analyse streams of data information and to derive rational conclusions from them. As taken from IBM:
An event is anything that happens that is significant to an enterprise. Event processing is the capture, enrichment, formatting and emission of events, the subsequent routing and any further processing of emitted events (sometimes in combination with other events), and the consumption of the processed events.
Source: IBM
In a simple sense, an event processing architecture is based on interactions between 3 components which are listed below:
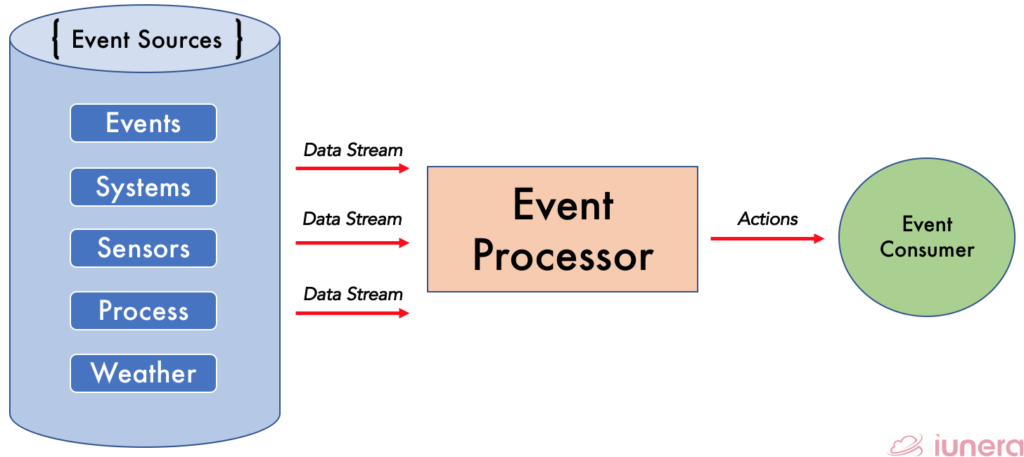
- Event Source – A pool of data in the form of a data lake such as data streams and commit logs such as updates of sensors and business events in the form of message queues.
- Event Processor – A system that performs various actions such as adding timestamps, adding information or metadata, or even process multiple information at once.
- Event Consumer – A system that reacts to the event that can be as simple as updating a database, interacting with external services, starting/closing new applications or services.
What is Complex Event Processing?
In today’s world, where there is a continuous flow of data from various sources, applications need to handle those data in a distributed and timely manner to ensure uptime. From IoT monitoring applications, which process raw sensor data from devices to applications performing analysis of stock prices to identify trends, the system created to handle these data must be fault-tolerant and reactive to the data flow.
Complex event processing (CEP) which could also be called stream processing is the method where different technologies can be used to query, modify, and transform the data with event streaming tools before storing it in a database for further work in the pipeline.
The idea behind CEP is to apply a cause-and-effect relationship when handling a Big Data stream to discover events and patterns which can result in an action that is required for the business organisation.
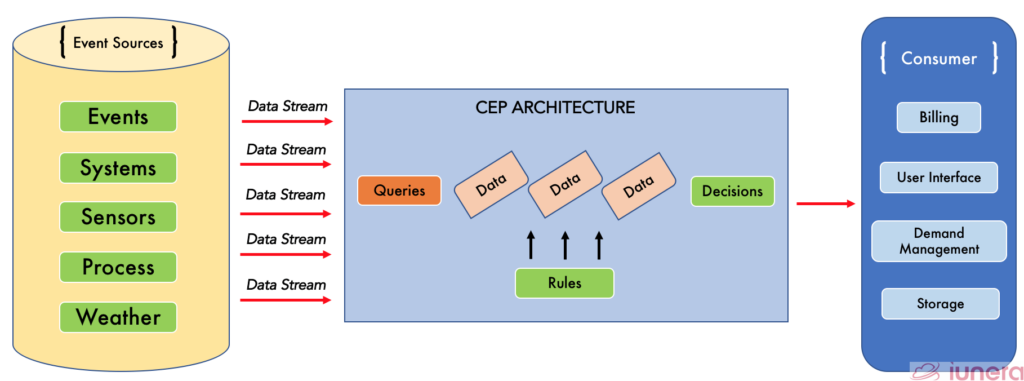
CEP is the concept of how to deal with a large amount of data from various sources. Event processors support different technical features and concepts to ensure consistency through processing is guaranteed and near real-time performance by scaling through partitioned processing.
Typically, computations are performed on the event stream compared to a typical database. Computations such as minimum/maximum, sampling, stream partitioning, parallelism are done reactively during the event stream flow.
Tools used in Complex Event Processing
With the recent growth of sensor networks, smart devices, and IoT applications collecting more and more data, the typical business now faces challenges to analyze real-time streaming data.
The flow of streaming data makes it challenging for decisions or delivery of business intelligence in an organization, which is a critical factor that could decide the company’s profits or growth. Let’s compare CEP to a traditional Database Management System (DBMS).
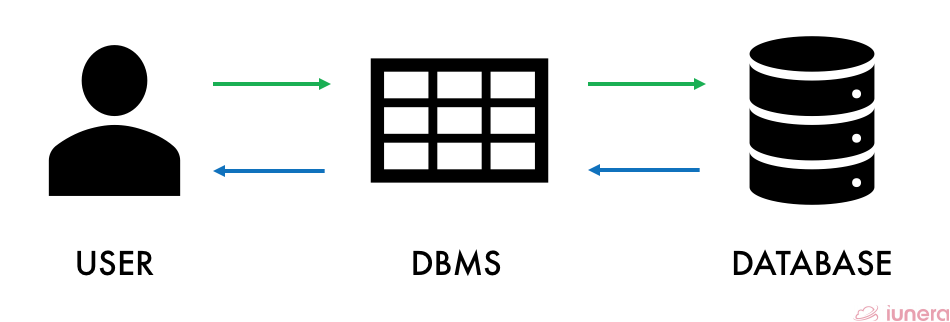
DBMS allows the user or certain programs to modify, query, or extract the managed data. Some of the most popular tools of DBMS are MySQL, PostgreSQL, SQL Server and Oracle. In comparison to CEP, the database is a finite set of stored data where queries are executed.
A query by the user or application/host gets executed by polling the database. CEP follows the concept of an infinite stream which is being ingested and processed continuously. Therefore, CEP applications can act reactively towards the event stream.
Let’s take a closer look at the tools that are commonly used for Big Data streaming used within the CEP architecture.
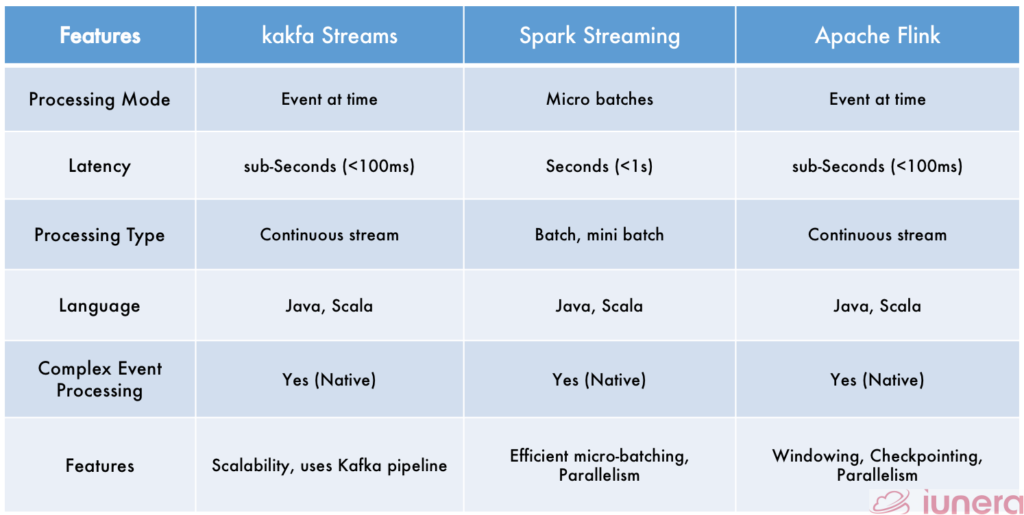
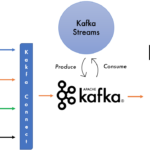
Kafka Streams
Kafka Streams is a client library for processing and analysing data stored in Kafka and either write the resulting data back to Kafka or send the final output to an external system.
It builds upon essential streams processing concepts such as properly distinguishing between event time and processing time, windowing support, and simple yet efficient management of application state.
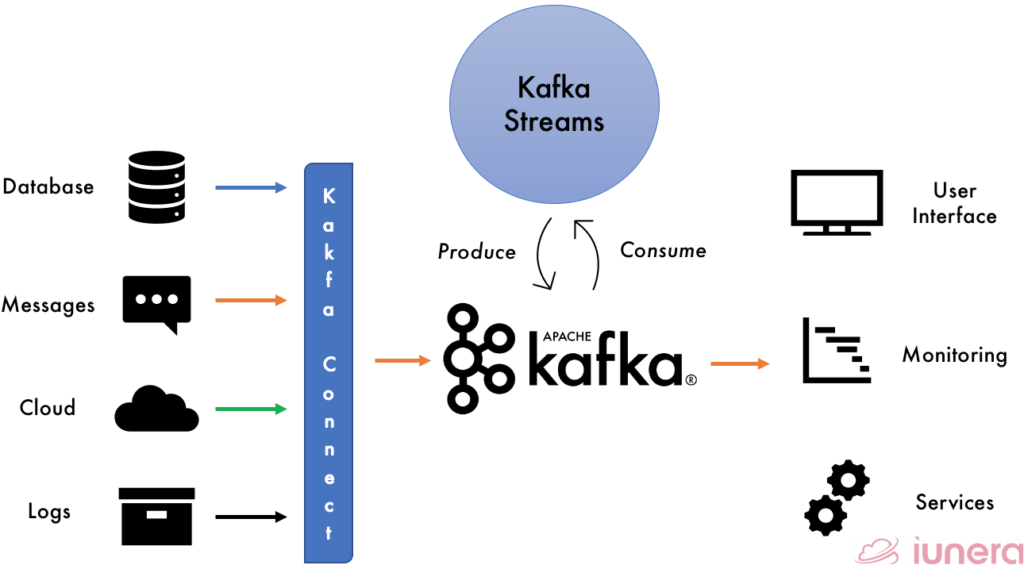
A streaming application such as Kafka Streams is designed to accomplish these 3 abilities:
- Gigantic streams of data from multiple sources are stored in a durable and fault-tolerant way
- Process the streams in real-time with low latency
- Perform publish and subscribe
“Kafka Streams is the easiest way to write mission-critical real-time applications and microservices”
Kafka Streams can be used in numerous scenarios and applications such as:
- Processing substantial payments and financial transactions with low latency
- Tracking logistical movement in real-time to ensure speed and robustness
- Capture and analyse real-time stream of sensor data to increase output
- Server as a foundation for data platforms and to handle small services
Spark Streaming
Spark Streaming is a scalable fault-tolerant streaming processing system that natively supports both batch and streaming workloads. Similarly to other stream processing frameworks, it has to be fault-tolerant and scalable when ingesting the data, and Spark streaming has those features in its development natively.
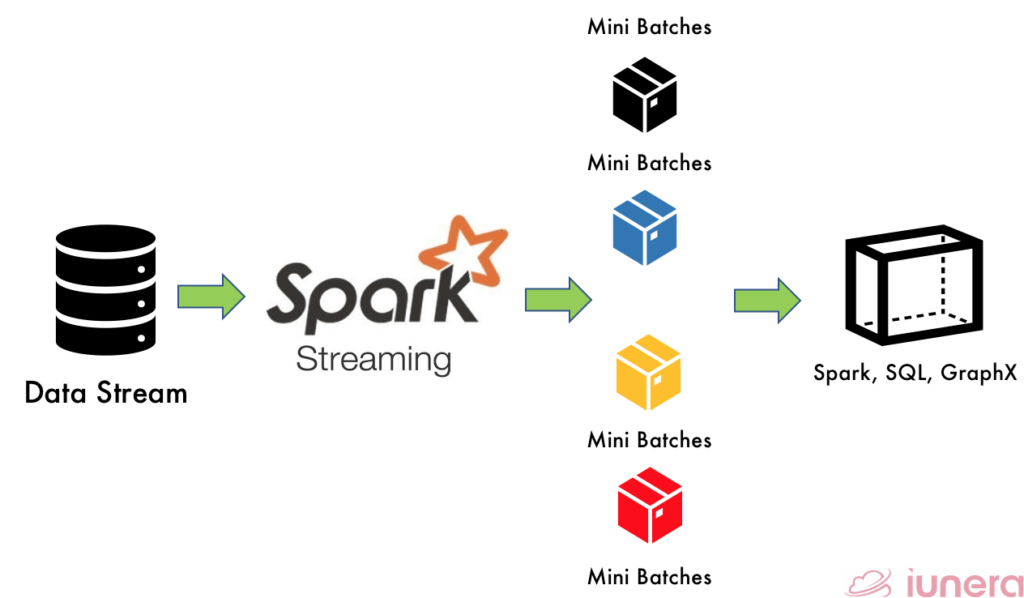
Spark Streaming is also one of the essential parts of the Big Data ecosystem. It is a software framework from Apache Spark Foundation used to manage Big Data. It can be used to process real-time data streams from applications like Twitter, Facebook, financial institutions, real-time cryptocurrency data, or anything that has constant data flow.
Spark Streaming cannot be confused with Apache Spark as both are not similar. Apache Spark is an in-memory distributed data processing engine that can process structured, semi-structured, and unstructured data using a cluster of machines.
The core difference between both is that Apache Spark uses Resilient Distributed Dataset (RDD) data structure in a more distributed manner. In contrast, Spark Streaming API uses DStream (built on top of RDD), which ingests the incoming streaming data and converts them into micro-batches based on a time batch interval. Ultimately, DStream is meant for continuous processing that always runs when there is new data where classical spark jobs tear down and finish at some point in time.
DStream creates a structured streaming computation as a statelessness series and performs deterministic batch operations (i.e., map, flatMap, filter) on those batches.
Apache Flink
Apache Flink is the most used open-source framework that possesses scalable, distributed and eventful Big Data Stream processing capabilities.
Flink is one of the most recent and pioneering Big Data processing frameworks that is widely used in most architecture which needs to handle real-time streaming of data.
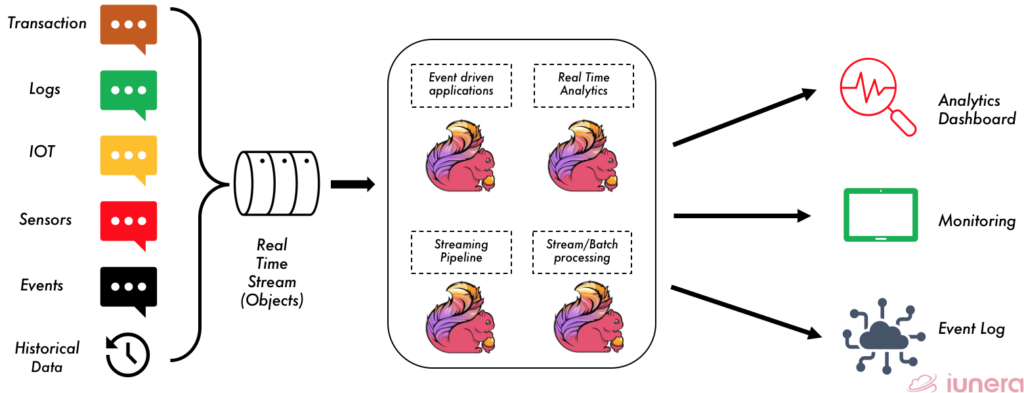
Flink ingests streams of real-time data such as financial transactions, event logs, IOT outputs, connected sensors, etc., which then undergoes various processing depending on the application. Flink can perform much processing, such as stream transformation, scheduling, parallel processing, assignments, etc.
Flink also has a very flexible mechanism to evaluate windows over continuous data streams. This works as follows: Flink divides the stream of data into finite or time-sliding slices based on some criteria like timestamps of elements. This concept of Flink called windowing. Windows split the stream into “buckets” of finite size, over which we can apply computations.
In Summary
The questions to be asked now is how necessary Big Data stream processing for an application or organisation is. Well, it all depends on how the business is operating. Most financial institutions such as credit card transactions, online payments, etc. need real-time processing to be able to handle fault payments quickly and robustly with 99.99% accuracy.
“Without big data analytics, companies are blind and deaf, wandering out onto the web like deer on a freeway”
– By Geoffrey Moore, an American Management Consultant and Author
Although not every application require an immediate response, there are many (e-commerce, financial, healthcare, security) that do, and that is where Big Data stream processing tools and techniques come in handy. Companies that take advantage of stream processing will more often make smarter and better decisions.
Are you looking for ways to get the best out of your data?
If yes, then let us help you use your data.
FAQ
What is Complex Event Processing?
A method where different data processing concepts and technologies are used to query and modify near real-time in a reactive fashion. Typically, and in contrast to a classical database view, complex event data is received as an infinite stream of continous events which are accessed via a publish subscribe mechanism from a message broker.
What are the 3 blocks in Event Processing
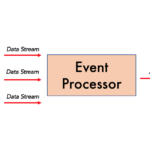
Event Source, Event Processor and Event Consumer
What are some applications of stream processing?
Processing payments and financial transactions, tracking logistical movement in real-time, processing sensors data for IoT applications
What are the standard tools or framework for Stream processing?
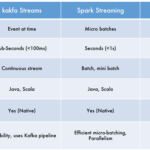
Different tools offer different techniques for stream processing. Some of the popular and widely used ones are Kafka Streams, Apache Flink, Storm and Spark Streaming
What is the difference between RDD and DStream?
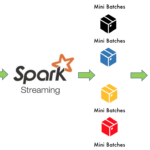
RDDs are created for finite sets of data out of a database or a data lake and get processed in a batch fashion. DStream is built on top of RDD and ingests the incoming streaming data and converts them into micro-batches based on a time batch interval. Ultimately, DStream is meant for continous processing that always runs when there is new data where classical spark jobs tear down and finish at some point of time.