
In the world of Big Data, the real value of these data depends on the effectiveness of the processing done on it. This is where Stream processing comes in. Stream processing technology allows users to query continuous data streams and detect conditions quickly and effectively. Architectures such as Lambda and Kappa are designed to handle these processes effectively. This article will explain the Lambda and Kappa architectures in Stream processing and how they are designed to handle real-time streaming data from various sources.

Stream Processing
Stream Processing technology enables users to query continuous data stream and detect conditions fast within a small period from the time of receiving the data. It takes in events from a stream, analyses them, and creates new events in new streams.
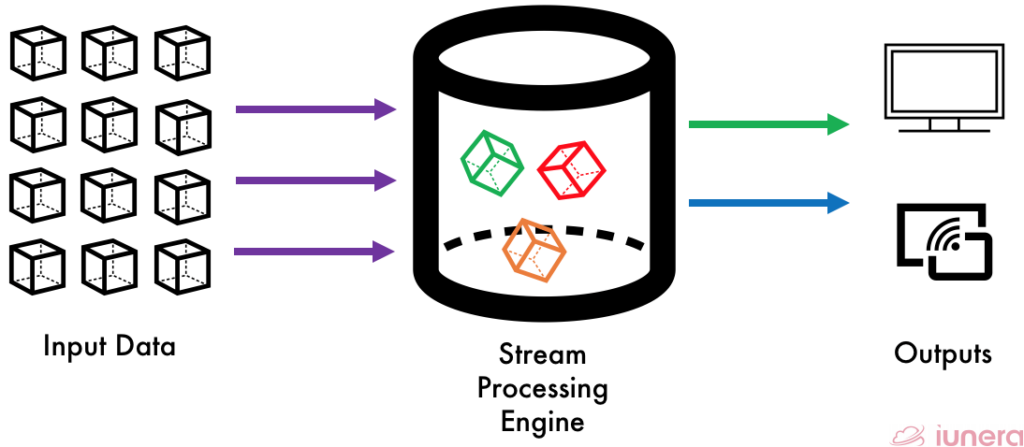
Why do we need Stream processing to handle large amounts of data? Compared to a batch processing technique with a certain latency, Stream processing handles never-ending data streams gracefully and naturally. You can detect patterns, inspect results, look at multiple levels of focus, and easily look at data from multiple streams simultaneously.
When it comes to handling time series data that are from the sources of IoT, financial transactions, and event logs, Stream processing naturally fits with time series data and detecting patterns over time. There are applications and frameworks such as Kafka Streams and Spark Streaming which are built to handle real-time streaming of data.
For example, in Uber, robust data processing systems such as Apache Flink and Apache Spark are utilized to power the streaming applications that help them calculate up-to-date pricing, enhance driver dispatching, and fight fraud on their platform.
Lambda Architecture
Before getting into the Kappa architecture, let us take a look at the Lambda architecture. A Lambda architecture is a type of data processing technique that is capable of dealing with a huge amount of data in an efficient manner.
When handling numerous event sourcing, the stream processing method is relied on to predict updates for the basic model and store the distinct events that serve as a source for predictions in a live data system.
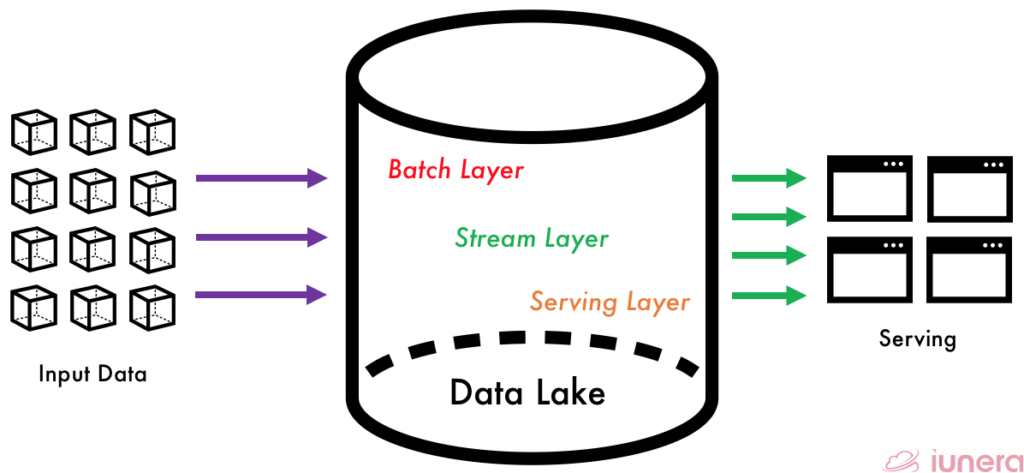
1. Batch Layer
Any new data stream that comes to the data system’s batch layer is computed and processed on top of a data lake. Mostly in the batch layer, data distribution such as managing historical data and recomputing results with Machine Learning models activity happens using frameworks such as Apache Nifi and Apache Spark. However, the results come at the cost of high latency due to high computation time.
2. Stream Layer (Speed Layer)
The speed layer processes data from the batch layer that has not been processed in the last batch of the batch layer. The stream layer compensates for the high latency of updates to the serving layer from the batch layer. Hence, it produces real-time views that are always up-to-date. Spark streaming is one of the most popular streaming frameworks used for this kind of application.
3. Serving Layer
The results of the batch layer are called batch views and are stored in a persistent storage layer. The storage layer is scalable data that swaps in the new batch views as soon they are readily available from the stream layer. One of the popular frameworks is called Cassandra used on Facebook.
Apache Cassandra – A structured storage system on a P2P Network managing structured data that is designed to scale to an enormous size across many commodity servers, with no single point of failure
Facebook Engineering Team
Kappa Architecture
Kappa Architecture is actually very similar to Lambda architecture, except it does not have the Batch layer to perform the processing. The canonical data stored in a Kappa Architecture system is an append-only immutable log. From the log, data is streamed through the speed layer and is stored for serving.
Kappa Architecture is Lambda architecture with the Batch layer removed. Data is fed through the streaming layer quickly.
Kappa architecture revolutionizes database migrations and reorganizations because much of the computations and processing latencies are removed since there is no batch processing layer.
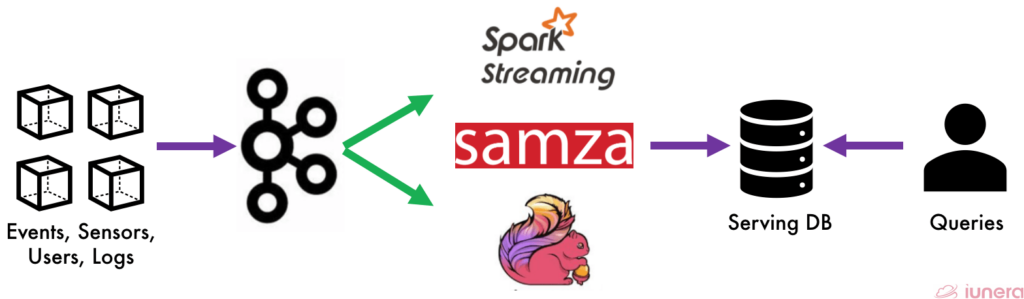
The Kappa architecture’s main advantage is that we can perform both real-time processing and batch processing, especially anything related to Big Data analytics, with a single technology stack.
It starts with the incoming data being stored in a messaging engine model such as Apache Kafka, followed by streaming frameworks like Samza, Flink, or Spark Streaming. The incoming data will be processed and stored in a serving database for the end-user to perform queries.
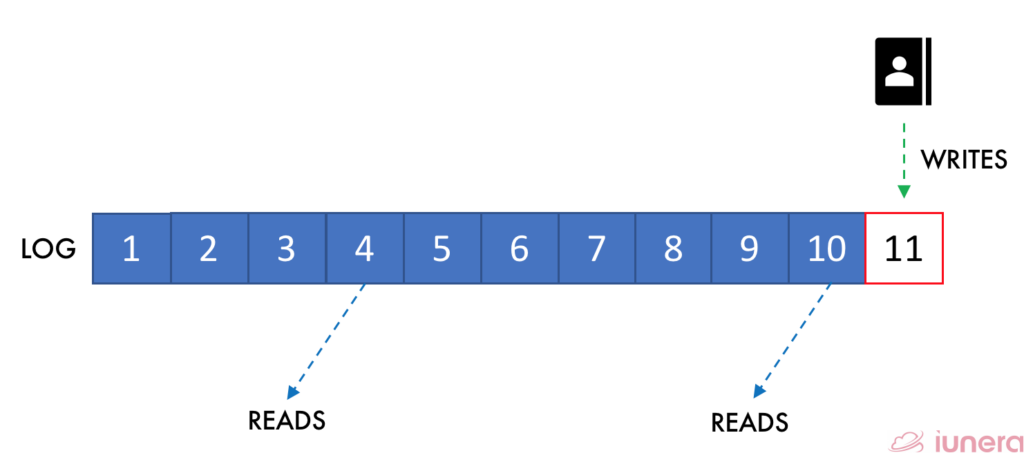
Distributed Commit Log
The Kappa Architecture proposes itself as a non-mutable data stream, unlike the Lambda Architecture, to replicate its codebase in multiple servers. The Kafka framework is utilized within the architecture, a scalable, publish-subscribe messaging system with its core architecture as a distributed commit log. In a simple explanation, Kafka can serve as a kind of external commit-log for a distributed system. The log helps replicate data between nodes and acts as a re-syncing mechanism for failed nodes to restore their data.
Consistency, Availability and Partition
A typical concept of Big Data software is designed to run in clusters with different nodes. Clusters of different Big Data processing or storage tools are designed to be failure tolerant. They offer scale-out capabilities to gain performance or storage almost linearly when adding new nodes. This is where the CAP theorem comes in.
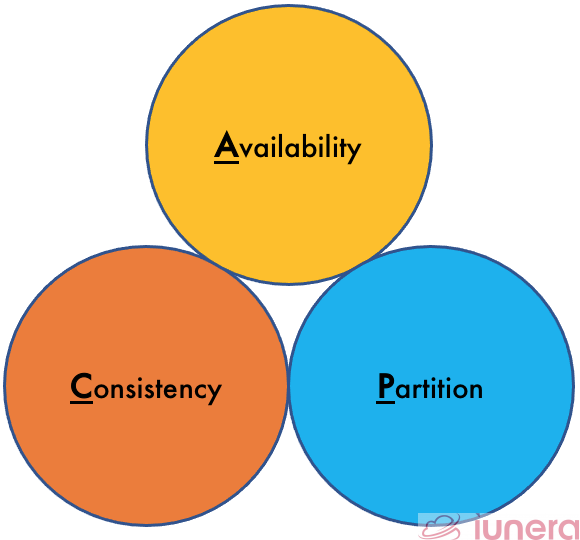
- Consistency – Every read receives the most recent write or an error
- Availability – Every request receives a (non-error) response, without the guarantee that it contains the most recent write
- Partition Tolerance – The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes
However, when dealing with some modern distributed systems, Partition Tolerance is a must to implement. Big Data tools are normally aware of this choice and decide in advance for the tool architecture for partitioning and eventual consistency or let the user decide between consistency and availability.
In Summary
Real-time processing is significant when it comes to handling real-time streaming data from the sources of IoT, financial transactions, and event logs. Kappa architecture is designed without the batch layer whereby the data is streamed into the serving layer, which improves latency. Kappa is more useful where it is required to deal with unique events occurring on the runtime for real-time processing.
Lambda on the other hand is designed to update the data lake to predict the upcoming events in a robust and error-free manner (with Batch Layer). In short, the use of architecture depends on the types of applications that are being used.
Are you looking for ways to get the best out of your data?
If yes, then let us help you use your data.
Takeaways (FAQ)
What is Stream Processing?

Stream Processing technology enables users to query continuous data stream and detect conditions fast within a small period from the time of receiving the data
What are the 3 layers in Lambda Architecture?
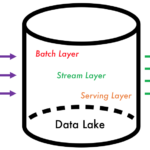
The 3 layers in the Lambda Architecture are Batch Layer, Speed Layer and Serving Layer
What does the Speed Layer do in the Lambda Architecture?
The speed layer processes data from the batch layer that has not been processed in the last batch of the batch layer. The speed layer compensates for the high latency of updates to the serving layer from the batch layer
What is Kappa Architecture?
Essentially, the Kappa Architecture is Lambda architecture with the Batch layer removed. The real-time data is fed through the speed layer quickly by using stream processing frameworks.
What is a commit log in a distributed system?
Apache Kafka can serve as a kind of external commit-log for a distributed system. The log helps replicate data between nodes and acts as a re-syncing mechanism for failed nodes to restore their data.