
What is Hadoop, and what can it offer for large scale storage management?
Businesses today are finding that the amount of data they generate and store is rising exponentially. If that’s the case with your organization, you’re probably searching for ways to manage all that information efficiently and cost-effectively. One popular option for doing just that is a system called Hadoop by Apache.
Introduction to Hadoop
Apache Hadoop is an open-source distributed processing framework that manages data processing and storage for big data applications in scalable clusters of computer servers.
It’s at the center of an ecosystem of big data technologies that are primarily used to support advanced analytics initiatives, including predictive analytics, data mining and Machine learning. Hadoop is able to handle various forms of structured and unstructured data, giving users and engineers more flexibility for collecting, processing, analyzing and managing data than relational databases and data warehouses provide.
If the data is not adequately managed or maintained by a sustainable framework, most of the data will go unused and create a data swamp. In short, a data swamp is a data pond that has grown to the size of a data lake but failed to attract a broad analyst community, usually due to a lack of self-service and governance facilities.
Hadoop’s ability to process and store different data types makes it a perfect fit for big data environments. They typically involve large amounts of data and a mix of structured transaction data and semi-structured and unstructured information, such as internet records, web server and mobile application logs, social media posts, customer emails, and sensor data.
Hadoop also supports JSON. JSON is a JavaScript-based lightweight text format for storing and transporting data, a data interchange process. It is a way to store information in an organised, easy-to-access manner. Most (unstructured) data is stored in JSON and CSV. In HDFS, you can store any file data. Structured data is rather stored in Parquet or ORC.
Ecosystem of Hadoop
Hadoop Ecosystem is a platform or a suite which provides various services to solve the big data problems. It includes Apache projects and various commercial tools and solutions. Let us take a look at some of the tools below
- HDFS: Hadoop Distributed File System
- YARN: Yet Another Resource Negotiator. YARN is the one who helps to manage the resources across the clusters. In short, it performs scheduling and resource allocation for the Hadoop System
- MapReduce: Programming based Data Processing
- Spark: In-Memory data processing. Process consumptive tasks like batch processing, interactive or iterative real-time processing
- PIG, HIVE: Query-based processing of data services. It is a platform for structuring the data flow and processing datasets
- HBase: NoSQL Database
- Mahout, Spark MLLib: Libraries for Machine Learning
Big Data and Hadoop

Generally, Hadoop runs on servers that are able to scale up to support hundreds of hardware nodes. Nodes in this context represent a connection point that can receive, create, store or send data along distributed network routes.
The Hadoop Distributed File System (HDFS) provides fault-tolerant capabilities so applications can continue in a safer manner to run if individual nodes fail. When it comes to handling Big Data, Hadoop can process and store such a wide assortment of data; it enables organisations to set up data lakes as extensive reservoirs for incoming information streams.
A data lake is a centralized Data storage that can store different data types from structured data to unstructured data. As the amount of data in a company or business grows exponentially, the data must be stored somewhere.
The open-source idea of Hadoop enables other frameworks and software to be developed that can be used within the Hadoop ecosystem, enabling and supporting the framework. Below are some of the tools that are commonly used:
- Apache Flume – Tool used to collect, aggregate and move large amounts of streaming data into HDFS
- Apache HBase – A distributed database that’s often paired with Hadoop
- Apache Hive – A SQL-on-Hadoop tool that provides data summarization, query and analysis
- Apache Phoenix – A SQL-based massively parallel processing database engine that uses HBase as its datastore which performs operational analytics in Hadoop for low latency application
Apache Spark and Hadoop

Other than Hadoop, there is also a big data framework called Apache Spark has been setting the world of big data on fire. Spark can run on top of existing Hadoop clusters to provide enhanced and additional functionality.
With Spark’s convenient APIs and promised speeds up to 100 times faster than Hadoop MapReduce, some analysts believe that Spark has signalled the arrival of a new era in big data. Spark is implemented in Scala and can run on Akka. Jobs can be written in Java, Scala, Python, R, and SQL. It also has many out of the box libraries for machine learning and graph processing.
There are some notable features of Spark that goes well with Hadoop
- Hadoop Integration – Spark can work with files stored in HDFS.
- Resilient Distributed Datasets (RDD’s) – RDD’s are distributed objects cached in memory, across a cluster of compute nodes. They are the primary data objects used in Spark.
- Run 100 times faster – Spark, analysis software can also speed jobs that run on the Hadoop data-processing platform.

Furthermore, organisations that need batch analysis and stream analysis for different services can benefit from using both tools. Hadoop can—at a lower price—deal with heavier operations while Spark processes the more numerous smaller jobs that need an instantaneous turnaround
Spark is a programming Framework which replaces the classic Mapreduce Framework in Hadoop. It uses the MapReduce Computing Pattern but does the job faster, more comfortable and better. Generally, Spark is used on top of the Hadoop YARN computing framework. For more detail about running Spark on YARN using HDFS, please take a look at the link below.
https://blog.knoldus.com/understanding-how-spark-runs-on-yarn-with-hdfs/
The linear processing of large amounts of data is advantageous for Hadoop MapReduce, while Spark offers fast performance, iterative processing, real-time analysis, graph processing, machine learning and more. In many cases, Spark can outperform Hadoop MapReduce. The good news is that Spark is fully compatible with the Hadoop ecosystem.
What is HDFS?
As the number of data grows, it will one day surpass a single physical machine’s storage. It will then become necessary to partition it across several separate machines. File-systems that manage the storage across a network of machines are called distributed filesystems.
Since they are network-based, all network programming complications kick in, thus making distributed filesystems more complex than regular disk filesystems. Hadoop uses blocks to store a file or parts of a file. A Hadoop block is a file on the underlying file system. Hadoop is designed for streaming or sequential data access rather than random access. Sequential data access means fewer seeks since Hadoop only seeks to the beginning of each block and begins reading sequentially from there.
HDFS is the answer to the storage industry for handling and managing unstructured and huge data, which incurs a huge amount of cost. HDFS is also a fault-tolerant file system designed to store data reliably even if failures like namenode, datanode and network occur.
It works on a master-slave architecture wherein a master server manages access to files and slave for storing user data via data nodes.
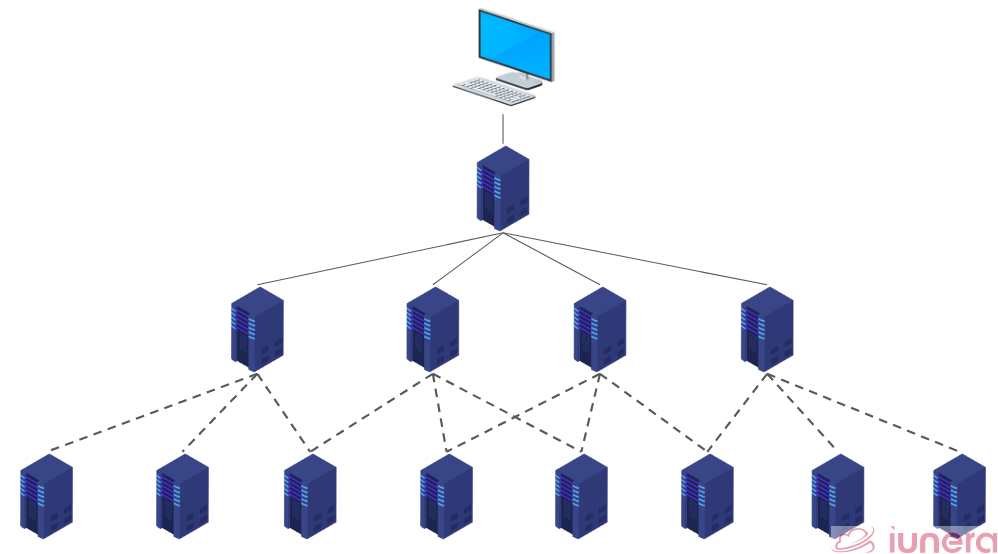
Advantages of HDFS
There are some advantages of implementing an HDFS in a typical data management entity, as shown below:
- Specially designed to deploy on midprice commodity hardware (where CPU, Storage and Memory is on many nodes)
- Provides high throughput access to application data and is suitable for applications that have large data sets
- Read access while streaming through the data is supported
- HDFS is a highly fault-tolerant and self-healing distributed file system
- HDFS is designed to turn a cluster of industry-standard servers into a highly scalable pool of storage
- Maintains high reliability by automatically maintaining multiple copies of data
The Hadoop platform also comprises of an ecosystem including its core components, which are HDFS (File Management System), YARN (Resource Manager and Service Scheduler), and MapReduce (Parallel Programming Model)
MapReduce
MapReduce is a programming model for writing applications that process vast amounts of data in-parallel on large commodity midprice hardware clusters.
A MapReduce job usually splits the input data-set into independent chunks which are processed by the map tasks in a completely parallel manner. As for the output, the map is sorted accordingly which are the input to the reduce tasks.

Both compute, and storage nodes, MapReduce and HDFS respectively run on the same set of nodes. This configuration allows the framework to effectively schedule tasks on the nodes where data is already present, resulting in very high aggregate bandwidth across the cluster.
Typically both the input and the output of the job are stored in a file-system. The framework takes care of scheduling tasks, monitoring them and re-executes the failed tasks.
In a typical environment, MapReduce jobs are normally “batch” jobs which are scheduled and when you have many of these scheduled batch jobs, the system can be a little chaotic when it comes to handling these jobs.
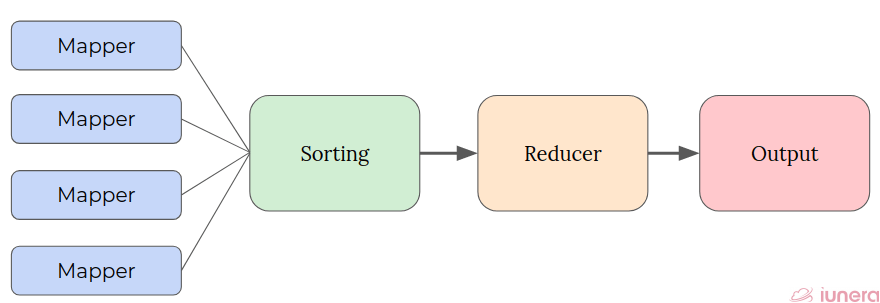
Phases of MapReduce
MapReduce is one of the core components of Hadoop that processes large datasets in parallel by dividing the task into a set of independent tasks.
- Mapper – The input data goes through this function which accepts key-value pairs as input (k, v), where the key represents the offset address of each record, and the value represents the entire record content. This is the first phase of MapReduce programming and contains the coding logic of the mapper function.
- Sort-Shuffle – The mapped data in the (k, v) format then go through this phase where duplicate values are removed, and different values are grouped based on similar keys. Sorting in Hadoop helps reducer to distinguish when a new reduce task should start easily. This saves time for the reducer. The output of the Sort-Shuffle process will be key-value pairs again as key and array of values (k, v[])
- Reducer – In this phase, the function’s logic is executed, and all the values are aggregated against their corresponding keys. Reducer consolidates outputs of various mappers and computes the final job output.
- Output – The final phase that writes the output data in a single file output directory in the HDFS
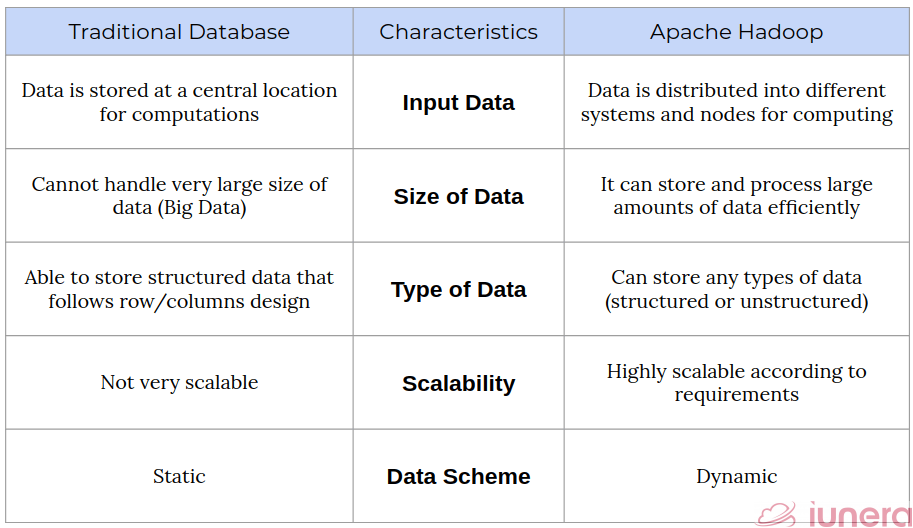
Traditional Database vs Hadoop
A traditional database allows multiple users to maintain, update, and edit stored information quickly, securely, and efficiently. For example, an online directory uses a database to keep people’s data, phone numbers, location, address, etc. Structured data is typically stored in a relational database (RDBMS). Structured data is managed using Structured Query Language (SQL), a software developed by IBM in the 1970s for relational databases.
The main difference between a traditional database and Hadoop is that a traditional database is optimized for transactional operations, whereas Hadoop is meant to store all data types.
On the other hand, Hadoop does things a bit differently. The comparison table below shows where Hadoop excels in comparison with a traditional database.
Limitations of Hadoop
Although Hadoop seems to be advantageous in most scenarios, there are too some drawbacks of this framework.
- Managing multiple clusters is complicated with operations such as debugging, distributing software, collection logs
- Lacks the ability to efficiently support the random reading of small files because of its high capacity design
- Hadoop supports batch processing only, it does not process streamed data, and hence overall performance is slower
- Missing ACID data operation
- Lacking modern Security like Certificate Authentication and OAuth Authentication
In Conclusion
From the comparison above, we can see how Hadoop applied when it comes to handling large scale storage systems. In a comparison of Hadoop and a traditional database, Hadoop offers a better choice in some cases.
A relational database can also be flipped inside-out and to start collecting the stream data in different databases. Depending on the use case, a relational database can have many advantages.
Hadoop is a large-scale, open-source software framework dedicated to scalable, distributed, data-intensive computing. With the help of Hadoop, data management and computations are significantly improved and are more effective.
Are you looking for ways to get the best out of your data?
If yes, then let us help you use your data.
What is Apache Hadoop?

Apache Hadoop is an open-source distributed processing framework that manages data processing and storage for big data applications in scalable clusters of computer servers.
Why is Hadoop popular?

The Hadoop Distributed File System (HDFS) provides fault-tolerant capabilities so applications can continue in a safer manner to run if individual nodes fail
What is HDFS in Apache Hadoop?
HDFS is also a fault-tolerant file system designed to store data reliably even if failures like namenode, datanode and network occur. It works on a master-slave architecture wherein a master server manages access to files and slave for storing user data via data nodes.
What are some advantages of HDFS?

Specially designed to deploy on low-cost commodity hardware. Provides high throughput access to application data and is suitable for applications that have large data sets. Read access while streaming through the data is supported. HDFS is a highly fault-tolerant and self-healing distributed file system. HDFS is designed to turn a cluster of industry-standard servers into a highly scalable pool of storage
What is MapReduce?

MapReduce is a programming model for writing applications which process vast amounts of data in-parallel on large clusters of commodity hardware
What is the definition of a 'job' in MapReduce?
A MapReduce job usually splits the input data-set into independent chunks processed by the map tasks in a completely parallel manner and reduced in a reduced stage in a partitioned parallel manner.
What are the phases of MapReduce?
The most important phases of a MapReduce job is Mapper, (optional Sort-Shuffle), Reduce and Output
What are some of the ecosystem of Hadoop?
Some of the ecosystems of Hadoop includes HDFS
YARN, MapReduce, Spark, PIG, HIVE, HBase