
Most teams evaluating uncensored models spend a lot of time on model selection. They compare benchmarks. […]
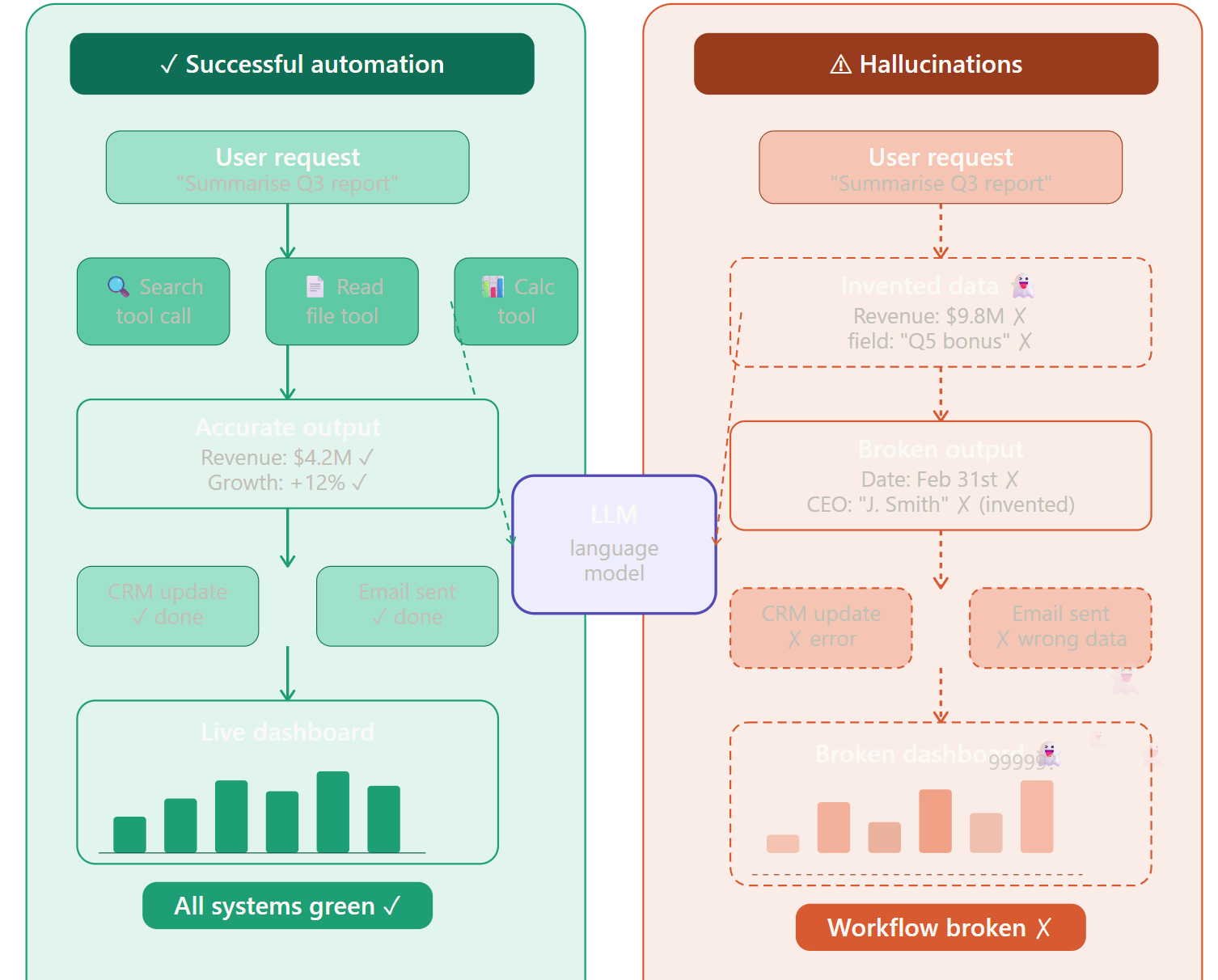
There’s a pattern that plays out almost every time a team switches from an aligned cloud […]
Uncensored language models are having a moment. Developers are frustrated. Researchers are annoyed. Enterprise teams are […]
“The pipeline didn’t crash. The JSON was valid. The workflow completed. And the data was quietly […]
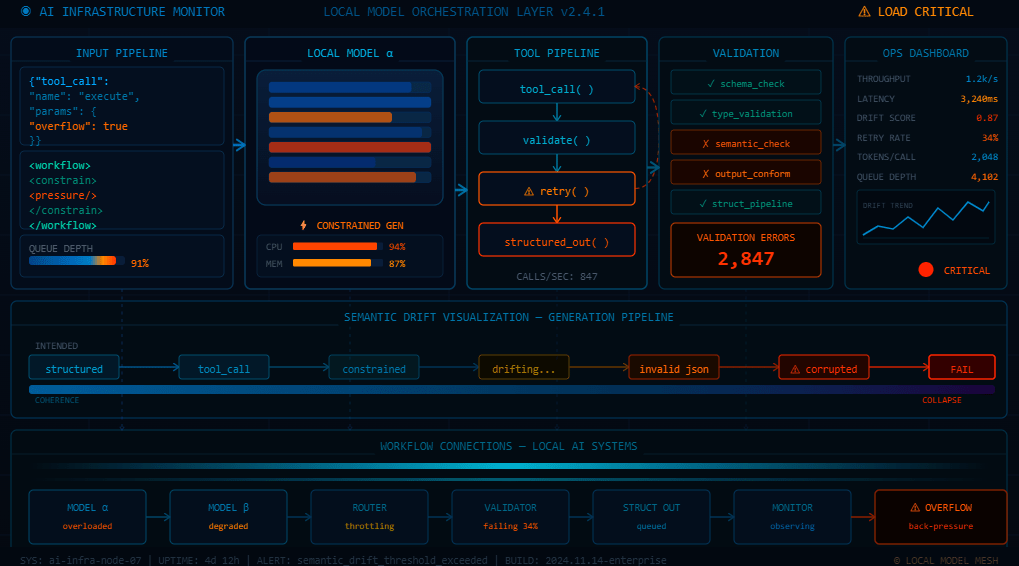
“The more I locked down the output format, the worse the actual content got. Tighter constraints, […]
“The model didn’t fail. The output looked perfect. But the data it returned never existed in […]

The controversy around “uncensored” AI models is mostly noise. The operational reality is actually pretty interesting. […]
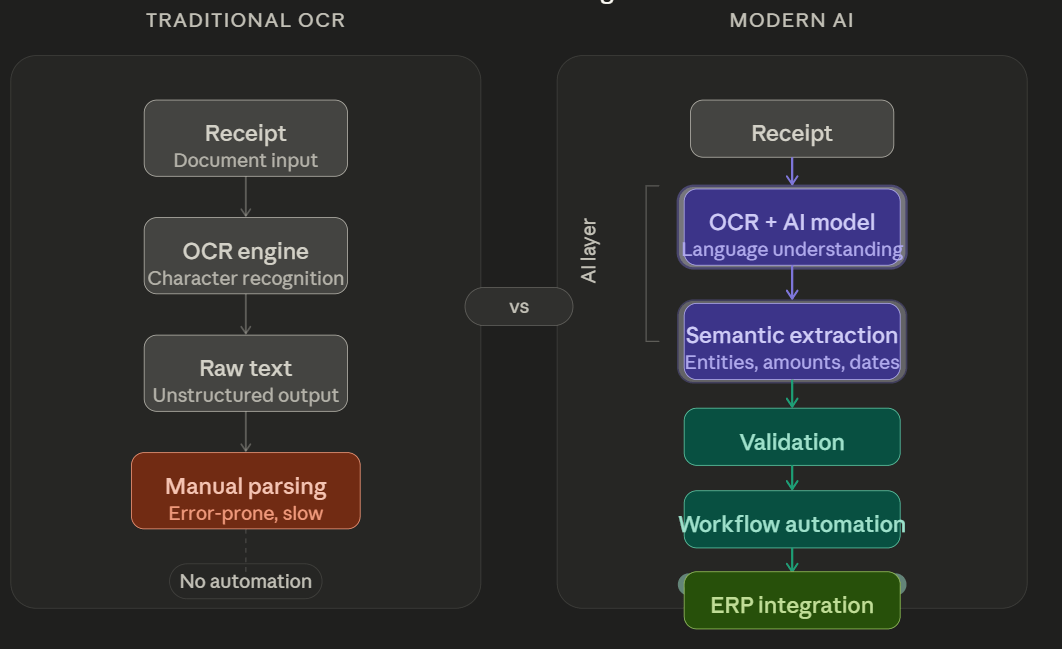
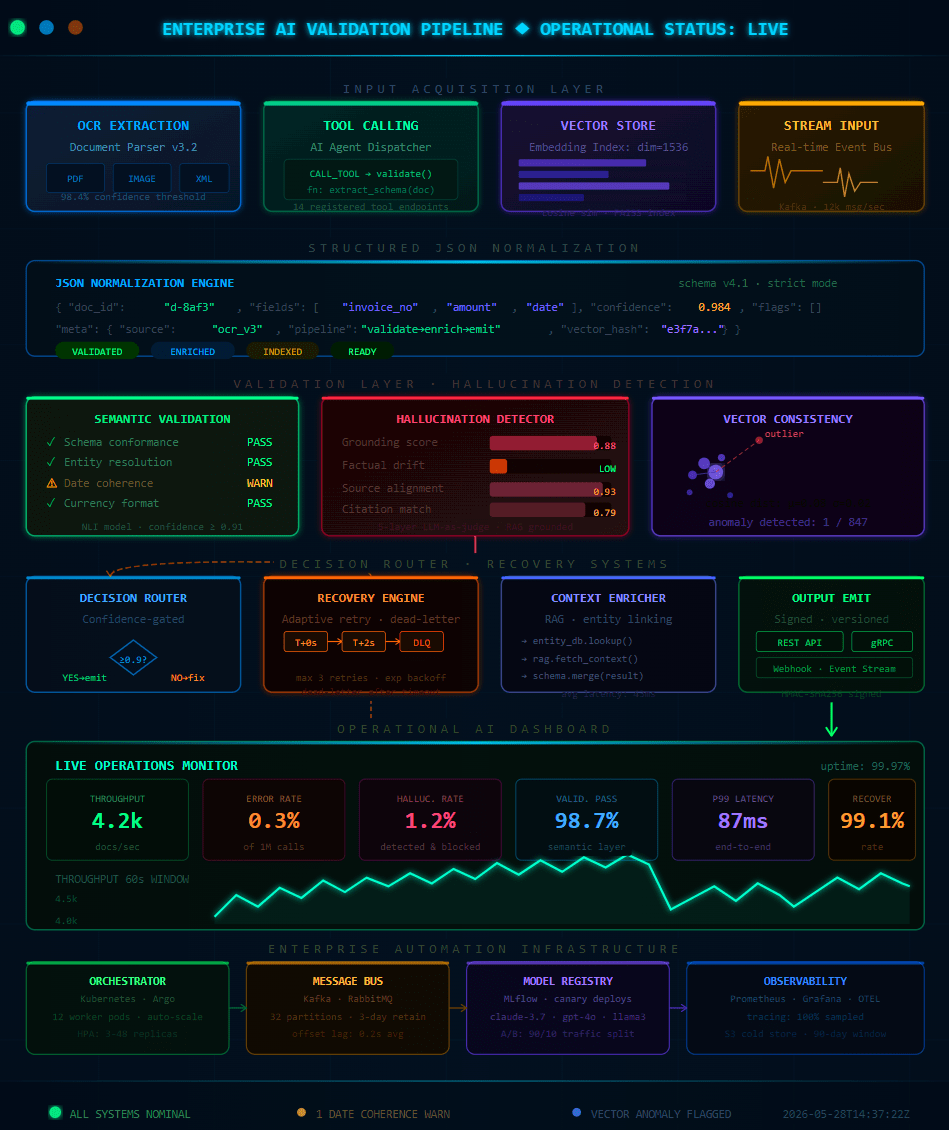
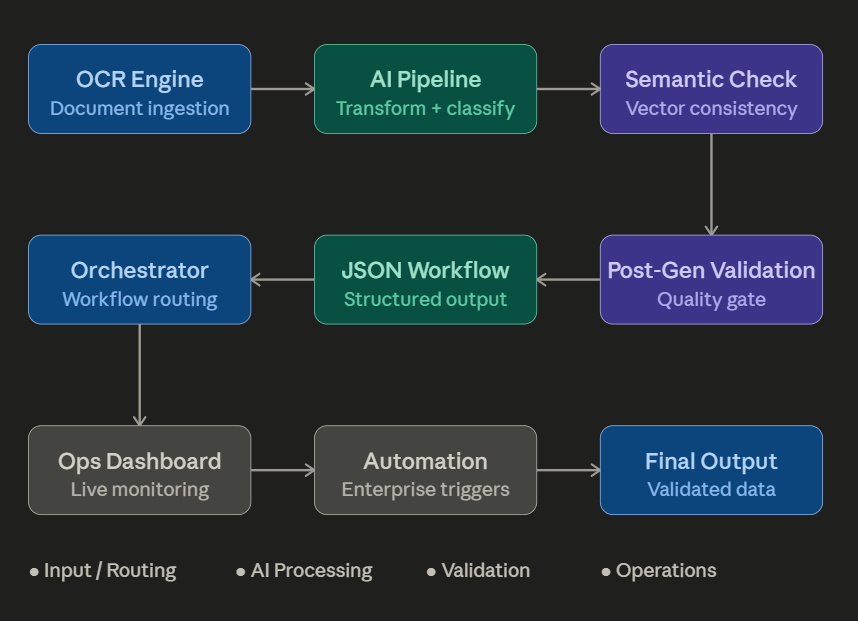
Receipt extraction initially appears to be a straightforward OCR problem. Scan the document.Extract the text.Convert it […]
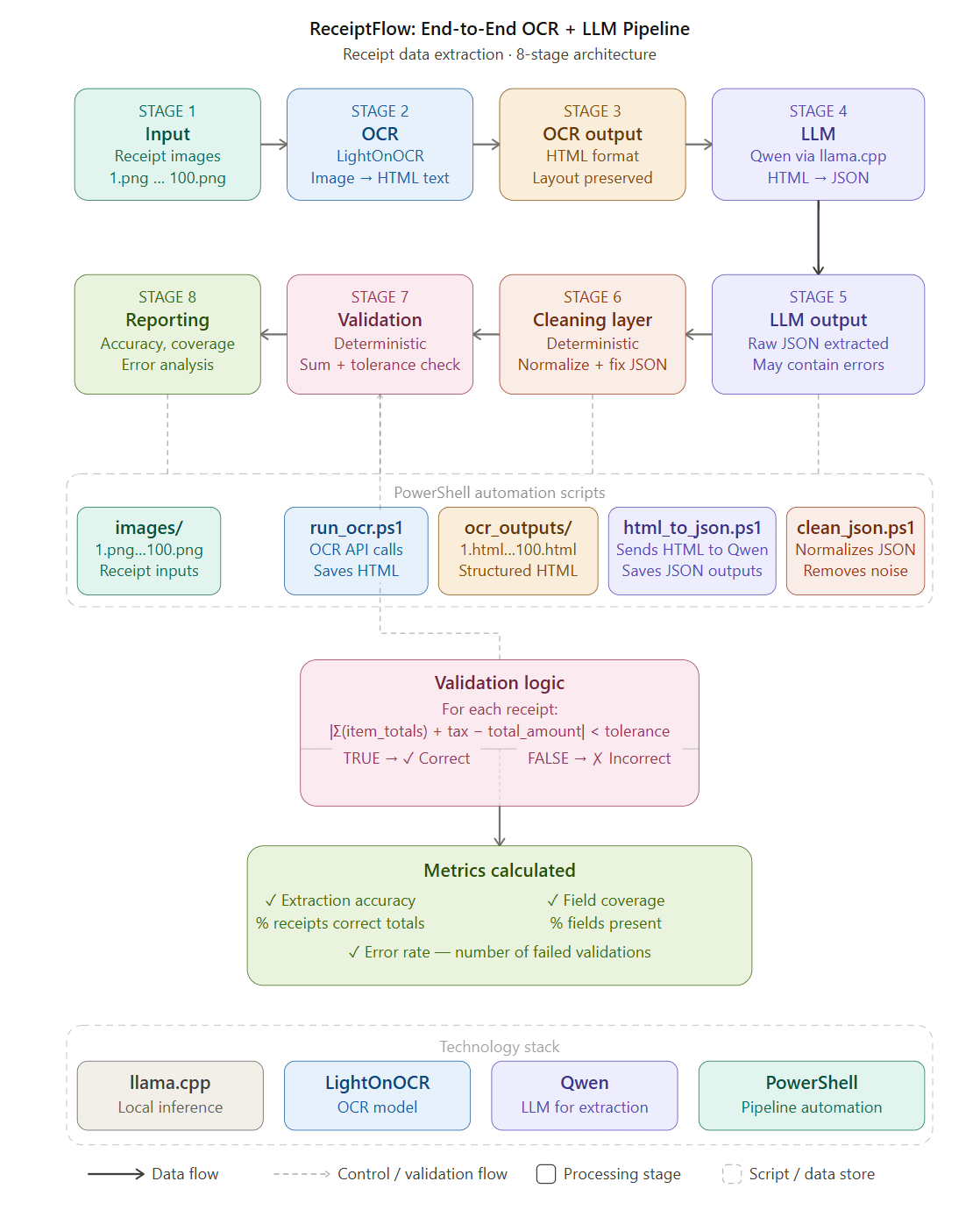
One of the biggest misconceptions around AI document automation is the idea that language models alone […]