
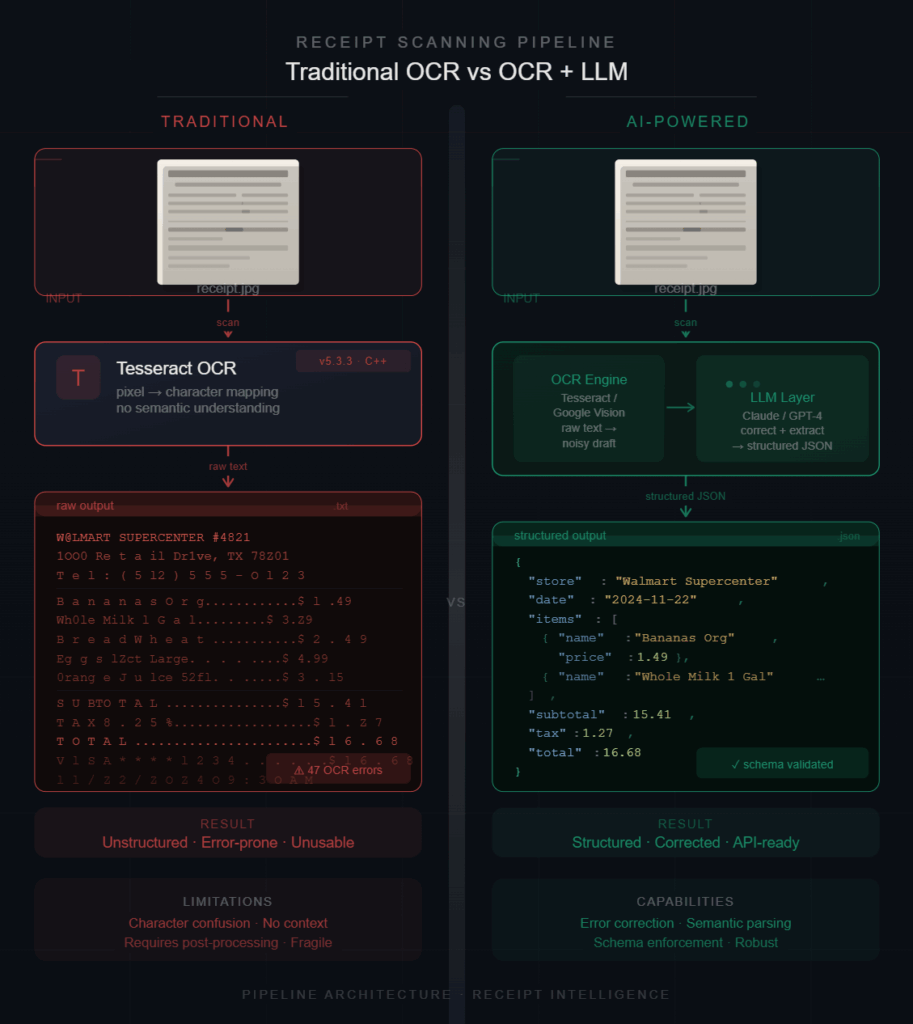
One of the biggest misconceptions around AI document automation is the idea that language models alone can reliably handle operational workflows.
In practice, they cannot. At least not consistently.
While modern OCR and LLM systems became remarkably good at extracting and interpreting receipt data, the outputs still frequently suffer from:
- hallucinated totals
- malformed JSON
- broken calculations
- duplicated fields
- semantic drift
- unstable formatting
And once these systems move beyond demos into real operational workflows, small inconsistencies quickly become expensive.
This is why validation layers became one of the most important components inside modern AI extraction systems. During experimentation with local OCR + LLM receipt extraction pipelines, we realized something surprising: The reliability of the workflow improved far more from deterministic validation than from simply using larger models.
This article explores why validation systems became critical for AI receipt extraction, the types of failures we encountered, and how deterministic correction layers transformed unstable outputs into operationally useful workflows.
Introduction
Receipt extraction initially sounds like an OCR problem. Then it starts looking like a language model problem. Eventually, it becomes a systems engineering problem. That transition happens very quickly once real receipts enter the workflow. Clean examples work well.Real receipts do not.
Thermal paper fades.
Discounts break structure.
OCR formatting collapses.
Taxes appear inconsistently.
Totals drift.
JSON breaks unexpectedly.
And even when the extracted information looks visually correct, small numerical inconsistencies can quietly make the output unusable for operational systems. This is exactly where validation layers become essential. Because operational workflows do not care whether the AI output looks “mostly right.” Operational workflows require consistency.
Why AI Alone Was Not Reliable Enough
Modern language models are surprisingly capable at:
- semantic grouping
- text interpretation
- structured extraction
- document understanding
But they still remain probabilistic systems. That becomes dangerous inside financial workflows. For example, during testing we repeatedly encountered outputs where:
- totals did not match item sums
- discounts disappeared
- taxes drifted incorrectly
- products duplicated
- JSON formatting broke
- line items merged incorrectly
Sometimes the outputs looked extremely convincing while still being mathematically wrong. That is one of the more dangerous characteristics of LLM-based extraction systems:
they often fail confidently. And inside financial automation, confident failures are still failures.
The Problem with Real Receipts
Most AI receipt demos use clean examples. Real receipts are much messier. During experimentation across approximately 100 receipts, the pipeline encountered:
- skewed images
- faded thermal printing
- multilingual text
- broken OCR spacing
- inconsistent layouts
- overlapping discounts
- compressed totals
- malformed receipt structures
Traditional OCR systems like :contentReference[oaicite:0]{index=0} extracted visible text reasonably well, but the semantic structure often collapsed.
Once structure drifted, the language model frequently began:
- hallucinating fields
- merging unrelated values
- inventing missing information
- producing unstable outputs
The issue was not only extraction quality. The issue was operational reliability.
The Pipeline Architecture
The workflow combined:
- OCR
- local LLM inference
- structured prompting
- validation systems
- deterministic correction
The architecture evolved into:
Receipt → OCR → OCR Text → LLM Extraction → Cleaning Layer → Validation Layer → Structured JSON Output
Initially, the validation layer barely existed. We assumed prompting alone would solve most extraction problems. That assumption failed quickly. The more receipts we processed, the more obvious it became that prompting alone was insufficient for operational reliability.
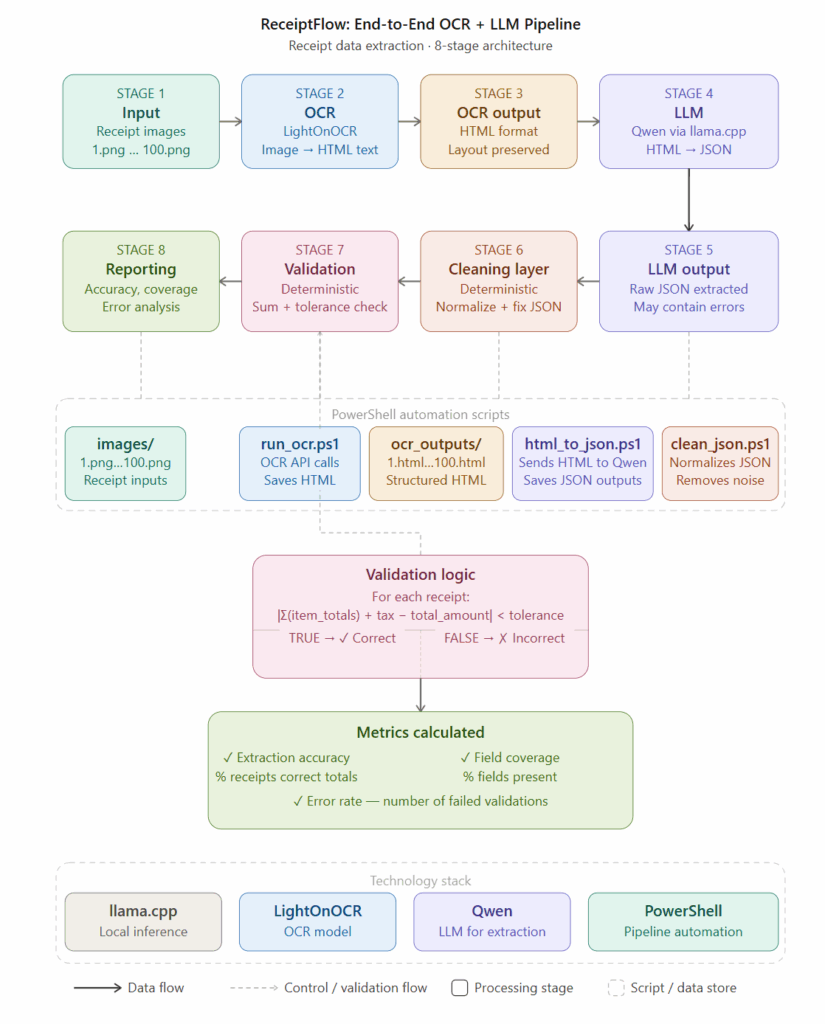
Figure: OCR + LLM receipt extraction workflow stabilized through deterministic validation layers
The Most Common Failure Modes
One of the most valuable parts of experimentation was observing repeated failure patterns.
Several issues appeared consistently across receipts.
1. Total Mismatches
Sometimes:
sum(items) ≠ receipt total
This happened because:
- discounts disappeared
- taxes merged incorrectly
- OCR formatting collapsed
- duplicated products appeared
Even small calculation drift immediately made outputs unreliable for accounting workflows.
2. Hallucinated Products
The model occasionally generated:
- non-existent products
- duplicated line items
- inferred quantities not present on the receipt
Interestingly, larger models sometimes hallucinated more aggressively than smaller ones.
3. Broken JSON
Malformed JSON became one of the most frustrating problems operationally.
Common issues included:
- missing brackets
- duplicated commas
- invalid nesting
- incomplete arrays
- structure drift
This became especially common on longer receipts with:
- multiple discounts
- promotional sections
- tax breakdowns
- mixed currencies
4. Semantic Grouping Failures
Sometimes the OCR itself remained visually readable while semantic structure collapsed completely.
Examples included:
- totals merging into line items
- discounts attaching to wrong products
- taxes appearing as products
- headers becoming purchase entries
This revealed something important:
document extraction is not only about text recognition.
It is fundamentally about preserving relationships.
Why Deterministic Validation Became Critical
The most important realization from the entire workflow was surprisingly simple:
The AI system became useful precisely when we stopped trusting it completely.
Instead of assuming the model output was correct, the pipeline started verifying:
- calculations
- totals
- discount consistency
- field structure
- JSON formatting
For example:
sum(line_items) - discounts + taxes ≈ total
If the values drifted significantly:
- outputs could be flagged
- receipts could be reprocessed
- corrections could be applied
- validation errors could be logged
This dramatically improved reliability.
And importantly, it improved reliability without requiring dramatically larger models.
Validation Improved More Than Model Size
Initially, the instinct was to solve problems by increasing model size.
Bigger models seemed like the obvious answer.
But after repeated experimentation, something surprising became obvious:
Validation layers improved operational stability more than larger models did.
Even advanced models still occasionally:
- hallucinated
- broke formatting
- drifted semantically
- generated unstable outputs
Meanwhile, smaller models paired with deterministic validation often produced more operationally useful workflows.
This changed how we thought about AI automation entirely.
The workflow itself became more important than raw model intelligence.
Building the Validation Layer
The validation workflow gradually evolved into several stages.
Structural Validation
Checking:
- valid JSON
- required fields
- array consistency
- formatting integrity
Financial Validation
Checking:
- subtotal consistency
- discount calculations
- tax correctness
- total reconciliation
Semantic Validation
Checking:
- duplicate products
- impossible values
- empty line items
- malformed quantities
Correction Logic
Applying:
- normalization
- field cleanup
- structure repair
- deterministic corrections
The important realization was that AI extraction became much more useful once deterministic systems stabilized the outputs afterward.

Figure: Financial and structural validation of extracted receipt data
Why Smaller Models Benefited Most
One particularly interesting observation was that smaller local models benefited enormously from validation layers.
Without validation:
- structure drift became frequent
- totals broke often
- hallucinations increased
But once deterministic checks stabilized the outputs, smaller models became surprisingly operationally useful.
This mattered because smaller local models offered:
- lower latency
- CPU-only inference
- offline deployment
- cheaper infrastructure
- better scalability
Validation layers effectively compensated for many smaller-model weaknesses.
That became one of the most important architectural insights from the entire experiment.
Why This Matters Beyond Receipt Extraction
Receipt extraction may appear niche at first glance.
But structurally, the same problems exist across many enterprise workflows:
- procurement systems
- invoice processing
- logistics reconciliation
- healthcare paperwork
- insurance claims
- operational document workflows
All of these systems increasingly combine:
- OCR
- AI extraction
- semantic understanding
- validation systems
And increasingly, reliability depends less on perfect AI reasoning and more on deterministic workflow engineering.
The Bigger Shift Happening
One of the most interesting realizations from this project was that modern AI workflows are slowly evolving toward hybrid systems.
Not purely AI.
Not purely deterministic software.
But combinations of:
- probabilistic extraction
- semantic reasoning
- structured validation
- deterministic correction
That architecture turns out to be significantly more stable operationally than relying purely on language models.
And as businesses move AI systems into real operational environments, this hybrid design pattern will likely become increasingly important.
Conclusion
Building reliable AI receipt extraction workflows required much more than OCR and language models alone. The real breakthrough came from deterministic validation systems.
Validation layers transformed:
- unstable outputs
- hallucinated values
- malformed structures
- inconsistent calculations
into workflows that became operationally useful. The most important realization was not that language models suddenly became perfect. It was that reliable automation increasingly depends on hybrid systems combining:
- AI extraction
- deterministic validation
- workflow engineering
- semantic correction
That shift changes how modern document automation systems should be designed entirely. And increasingly, validation layers may become one of the most important components inside enterprise AI workflows.
References
- llama.cpp GitHub Repository — Local LLM inference framework used for running quantized models on CPU hardware.
- Qwen Official Hugging Face Organization — Official repository for Qwen language models used in local receipt extraction experiments.
- Tesseract OCR GitHub Repository — Open-source OCR engine used for baseline receipt extraction experiments.
- GGUF Format Documentation — Documentation for GGUF quantization used for efficient local inference.
- llama-cpp-python GitHub Repository — Python bindings supporting local inference workflows.
Suggested Internal Links
- Processing 100 Receipts Locally with OCR and LLMs on CPU
- Why Small Local LLMs Are Becoming Viable for Receipt Automation
- Traditional OCR vs LLM-Based Receipt Extraction
- Receipt Scanning Is No Longer Just an OCR Problem
- Why AI Receipt Digitization Is Moving Beyond Traditional OCR