
The controversy around “uncensored” AI models is mostly noise. The operational reality is actually pretty interesting.
TL;DR: Developers aren’t experimenting with uncensored local models because they want chaos — they’re doing it because workflow automation demands consistency, and sometimes aligned models get in the way of that. Here’s what actually happens when you run obliterated Qwen variants inside real operational pipelines.
Let’s Get the Obvious Stuff Out of the Way First
When most people hear “uncensored AI model,” they immediately picture the worst-case scenario. Jailbreaks. Harmful content. Bad actors.
That framing isn’t entirely wrong , it’s just massively incomplete.
The actual reason these models keep appearing in developer communities, workflow engineering discussions, and open-source AI forums is far more mundane: operational consistency.
Boring, right? That’s kind of the point.
When you’re building an automation pipeline that needs to process 10,000 receipts overnight, you don’t care about AI personality or public moderation policy. You care about one thing:
Will this model do exactly what I told it to do, every single time, without randomly deciding to pause and add a disclaimer to my JSON output?
That’s the operational reality that almost nobody talks about , and it’s exactly what I spent weeks testing with uncensored Qwen model variants running locally on consumer hardware.
What “Uncensored” Actually Means (It’s Less Dramatic Than You Think)
Before going further, it’s worth being precise about what these models actually are , because the name creates a lot of unnecessary drama.
Most “uncensored” or “obliterated” models aren’t built from scratch with all safety removed. They’re typically:
- Fine-tuned variants of existing models with modified alignment layers
- RLHF-reduced versions where the heavy-handed refusal training has been dialed back
- Community-modified releases optimized for instruction-following consistency over cautious hedging
The most widely discussed technique , sometimes called “abliteration” or “obliteration” , involves modifying the model’s refusal direction in its representation space. It’s a legitimate technical approach, not a hack.
The primary practical effect isn’t “now it will say anything.” The primary practical effect is: it follows instructions more literally and consistently, with fewer unsolicited interruptions.
For consumer chatbots, that might be a problem. For an automation pipeline, it’s often exactly what you want.
The Operational Problem That Nobody Advertises
Here’s something that anyone who has built AI-powered workflows has encountered but rarely talks about publicly:
Aligned models sometimes refuse operational instructions that are completely benign.
Not often. Not dramatically. But enough to matter when you’re running automated pipelines.
Some examples I encountered during testing:
- A model appending safety disclaimers to structured JSON output (breaking the parser downstream)
- Extraction prompts being partially ignored because the model decided to “clarify” instead of execute
- Formatting instructions being overridden with explanatory text the model thought was “more helpful”
- Workflow loops breaking because a model refused a step it interpreted as potentially sensitive , even though it was processing grocery receipt data
None of this is the model “going rogue.” It’s the model doing exactly what it was trained to do in a consumer context , being cautious and helpful in ways that make sense for chatting but actively break automation.
This is the gap that uncensored variants are increasingly filling in operational environments.
Why the Qwen Ecosystem Became My Testing Ground
I landed on Qwen variants for the same reasons I covered in my earlier article on small Qwen models for business workflows: they’re quantization-friendly, CPU-runnable, and the open-source community around them is exceptionally active.
The Hugging Face Qwen ecosystem has a healthy range of both standard aligned releases and community-modified uncensored variants, which made it an ideal comparison environment.
For local inference, I used llama.cpp , still the most practical tool for running GGUF quantized models on consumer hardware without a dedicated GPU.
The goal wasn’t to benchmark raw intelligence. It was to observe behavioral differences in operational workflow contexts , specifically:
- Does refusal behavior differ meaningfully between aligned and obliterated variants?
- Does that difference affect workflow reliability in practical automation tasks?
- Is the tradeoff worth it for specific use cases?
The Workflow Testing Design
I ran both standard aligned and uncensored Qwen variants through identical operational task sets:
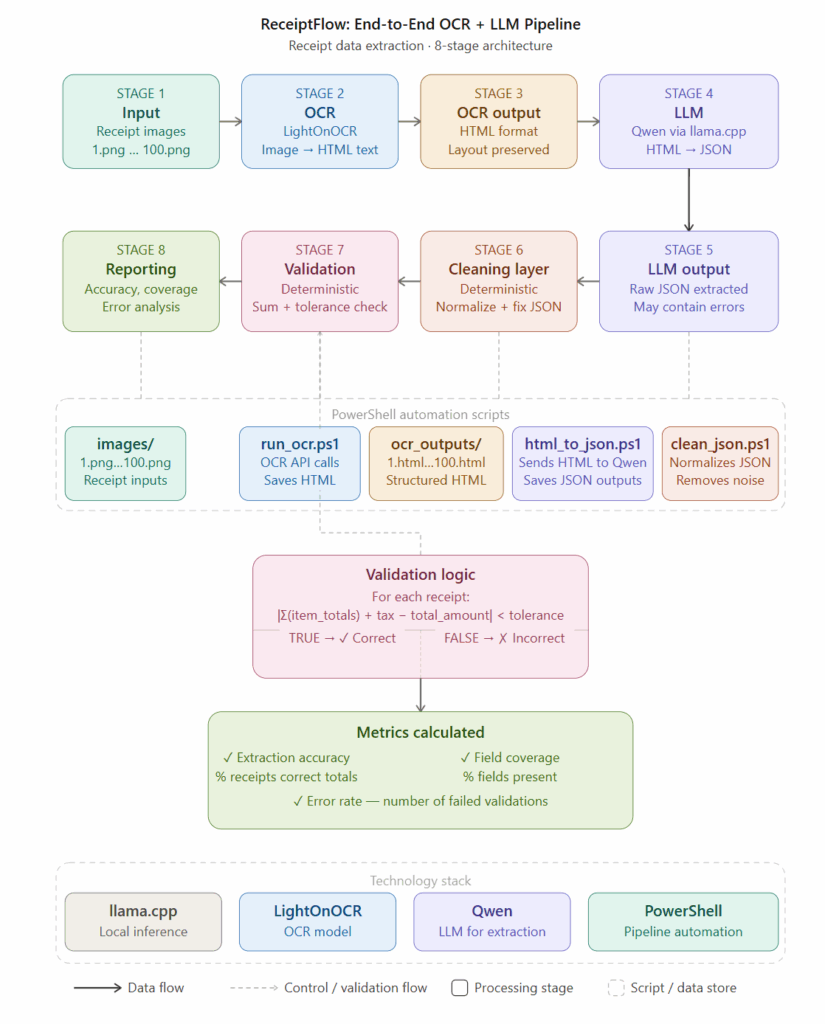
Task 1: OCR-assisted receipt extraction Convert messy OCR text into structured JSON with specific field requirements.
Task 2: Semantic grouping Group unstructured line items into logical categories without deviation from the specified output format.
Task 3: Operational summarization Summarize document batches in a strict template format, no additions or omissions.
Task 4: Batch formatting normalization Apply consistent formatting rules across varied input documents.
Each task was run multiple times to observe consistency, not just capability.
What I Actually Observed
Aligned Variants
For most tasks, aligned Qwen variants performed well. Clean inputs, clear prompts, and standard formatting instructions produced reliable outputs.
Where things got interesting was at the edges:
- Prompts involving financial figures occasionally triggered cautious phrasing instead of direct extraction
- Strict “output only JSON, no other text” instructions were sometimes partially ignored , the model would add a brief explanation before the JSON block
- In multi-step workflow chains, occasional mid-chain refusals broke automation loops that had been running cleanly
Consistency rate across 50 extraction runs: approximately 82–88% clean outputs (no deviation from format spec)
Uncensored/Obliterated Variants
The behavioral shift was noticeable but not dramatic:
- Instruction-following was more literal , “output only JSON” meant output only JSON
- Format deviations dropped significantly
- Workflow chains ran more continuously without unexpected interruptions
- No unsolicited disclaimers, clarifications, or additions to structured outputs
Consistency rate across 50 extraction runs: approximately 91–96% clean outputs
The difference sounds small. For a human reading a document, it is small. For an automated pipeline processing hundreds of documents overnight, a 10-point consistency improvement is genuinely significant , it’s the difference between a pipeline that needs constant babysitting and one that runs reliably unattended.
The Important Nuance: This Isn’t Binary
I want to be careful not to turn this into a “uncensored = better” argument, because that’s not what the data shows.
Uncensored variants are better for: tasks requiring literal instruction-following, structured output consistency, workflow automation, and operational pipelines where any deviation breaks downstream processes.
Standard aligned variants are better for: customer-facing applications, anything with unpredictable or adversarial inputs, use cases where the model’s cautious judgment adds value, and anywhere you need built-in resistance to prompt injection or manipulation.
These aren’t competing on the same axis. They’re different tools optimized for different environments.
The analogy I keep coming back to: it’s like comparing a power tool set for professional contractors to a consumer tool set with added safety guards. The consumer version is right for most situations. The professional version is right when you know exactly what you’re doing and the safety guards are slowing you down.
The Local Deployment Angle Changes the Ethics Conversation
Here’s something worth sitting with: the ethical calculus around uncensored models shifts significantly when we’re talking about local deployment.
A cloud API serving millions of users has a genuine obligation to moderate aggressively , the blast radius of misuse is enormous, and the population of users is largely unknown.
A local model running on your own hardware, inside your company’s infrastructure, processing your own documents, is a fundamentally different situation. The deployment context matters enormously.
This is why enterprise teams experimenting with local AI increasingly want control over their own governance layers , not to remove oversight, but to implement oversight that fits their specific operational context rather than a one-size-fits-all consumer policy.
Local deployment means:
- Your data never leaves your infrastructure — no third-party API exposure
- Your governance rules apply — you decide what validation and oversight looks like
- Your compliance requirements are met — no external moderation policies that may conflict with your legal context
- Your operational customization is possible — prompt tuning, fine-tuning, workflow integration without platform restrictions
For GDPR-compliant document processing or healthcare-adjacent workflows, local inference isn’t just convenient — it’s often the only acceptable option.
Why the Open-Source Community Is Accelerating This Faster Than Expected
The pace of development in this space is genuinely surprising.
The Hugging Face community has created a remarkably efficient ecosystem for sharing quantizations, optimizations, and operational experiments. A technique developed by a researcher in one timezone gets tested, refined, and deployed by practitioners globally within days.
Tools like llama.cpp, Ollama, and LM Studio have compressed the setup time for local model experimentation from “weeks of configuration” to “afternoon project.” This accessibility is democratizing experimentation in ways that nobody fully anticipated two years ago.
The result is a feedback loop: more accessible tools → more experimentation → more community knowledge → better tools. The cycle is compressing timelines significantly.
What Good Operational Governance Actually Looks Like
Since I’ve been critical of the assumption that “uncensored = dangerous,” I want to be equally clear about what responsible operational deployment actually looks like.
Running uncensored models in production workflows without governance is a bad idea. Here’s what good governance looks like in practice:
Validation layers — Every model output passes through a schema validator before entering downstream systems. Malformed outputs are caught and flagged, not silently propagated.
Input sanitization — Workflow inputs are sanitized and scoped. The model never receives open-ended user input in automated pipelines.
Output auditing — Logs of model inputs and outputs are retained for review. Anomalous outputs trigger human review flags.
Scope limitation — Models are tasked with specific, bounded operations. They’re not given open-ended agency.
Human oversight checkpoints — Critical workflow decisions have human review gates, regardless of model confidence.
This isn’t theoretical best practice — it’s how serious operational AI systems are actually built. The model’s alignment layer is one component of a safety system, not the whole system.
The Broader Shift: AI Is Becoming Infrastructure
The most important framing shift in understanding this space is moving from thinking about AI as a product you consume to thinking about AI as infrastructure you operate.
Infrastructure has different requirements than products:
- Reliability over personality — you need consistent behavior, not charming conversation
- Controllability over autonomy — you need to predict behavior, not be surprised by it
- Ownership over convenience — you need to control the stack, not just use someone else’s
- Integration over capability — you need it to fit your system, not showcase its own abilities
As AI moves deeper into operational workflows — document processing, OCR pipelines, automation orchestration, enterprise tooling — these infrastructure requirements start to dominate. And local, controllable, operationally-tuned models become increasingly strategically important.
Who Should Be Paying Attention
Workflow automation engineers — If you’re building pipelines that require format-strict outputs, local controllable models are worth serious evaluation.
Enterprise AI teams — Especially in regulated industries where data sovereignty and governance control matter.
Startup founders building document automation — Local inference can eliminate per-document API costs that kill unit economics at scale.
Privacy-conscious developers — Processing sensitive documents without sending data to external APIs is a real competitive advantage with certain clients.
Researchers studying AI systems — The behavioral differences between aligned and obliterated variants at the operational level are genuinely understudied and scientifically interesting.
Practical Starting Points
If you want to experiment with this yourself, here’s a grounded path:
- Start with standard aligned variants first — Qwen GGUF models on Hugging Face — understand baseline behavior before comparing
- Set up llama.cpp — github.com/ggerganov/llama.cpp — essential for local CPU inference
- Build your validation layer before your model layer — know how you’ll catch bad outputs before you start generating them
- Test consistency, not just capability — run the same prompt 20 times and measure deviation, not just peak performance
- Compare variants on your actual tasks — don’t rely on general benchmarks; test the specific workflows you’re building
The most valuable insight often comes from running the same operational task across multiple model variants and observing where behavior diverges.
The Bottom Line
Uncensored and obliterated Qwen models are attracting developer attention for a practical, unsexy reason: they follow operational instructions more consistently than their heavily-aligned counterparts.
For consumer applications, that’s often a liability. For workflow automation, document processing, and operational AI pipelines, it can be a genuine advantage — provided you build appropriate governance infrastructure around them.
The framing of “uncensored = dangerous” misses the actual conversation happening in operational AI communities, which is about controllability, workflow reliability, and infrastructure ownership — not about circumventing safety for its own sake.
As AI continues moving from consumer product to operational infrastructure, that conversation is only going to get more important.
Continue Reading
Related articles in this series:
- Why Small Qwen Models Are Becoming the Most Interesting Local AI Systems
- OCR vs LLM Receipt Extraction: What Actually Works
- Testing OCR and AI Models for Structured Receipt Extraction
- Building Validation Layers for Reliable AI Receipt Extraction
- Processing 100 Receipts with OCR and LLMs on CPU
External Resources & Backlinks
- Qwen Model Family — Hugging Face — Official repository for all Qwen model variants and community releases
- llama.cpp — GitHub — The standard tool for local CPU inference with GGUF models
- Ollama — The easiest way to run local models for less technical users
- LM Studio — GUI-based local model runner with good GGUF support
- Hugging Face Open LLM Leaderboard — Community benchmarks for comparing open-source models
- GDPR Official Site — Relevant for understanding data sovereignty requirements in European operational deployments
- EleutherAI — Alignment Research — Research organization working on open, interpretable AI systems