
There’s a pattern that plays out almost every time a team switches from an aligned cloud model to a locally-deployed uncensored one.
Week one: “This is incredible. It actually does what we ask.”
Week three: “Wait , where did this field come from? The model just made that up.”
The honeymoon phase with uncensored models is real. So is the hangover.
Of all the tradeoffs that come with reduced-alignment models built on Llama, Mistral, Qwen, and Gemma, hallucination is the one that causes the most production headaches. Not because it’s surprising , everyone knows LLMs hallucinate , but because uncensored models hallucinate differently. More confidently. More quietly. In ways that are harder to catch.
Let’s break down exactly what’s happening and what you can actually do about it.
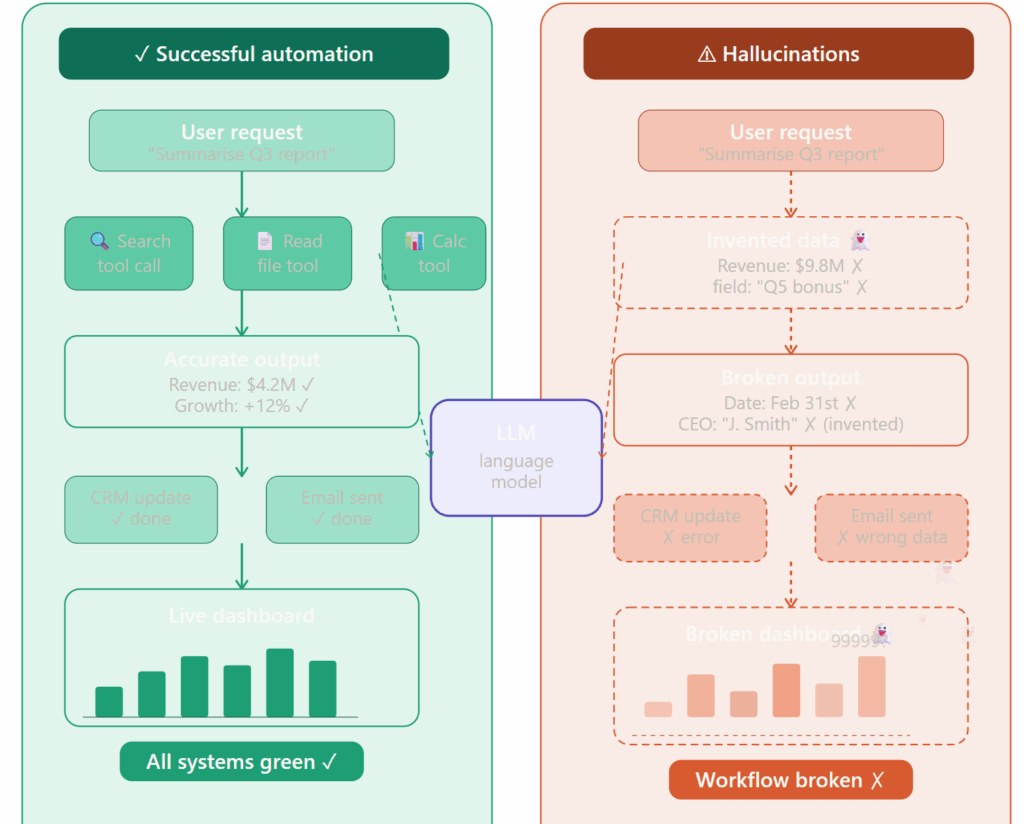
What Is an LLM Hallucination, Really?
The term gets thrown around loosely, so let’s be precise.
A hallucination occurs when a model generates information that isn’t grounded in its input, its context window, or verifiable facts from training , but presents it as if it were. The original research framing from NLP literature describes it as “fluent, plausible-sounding content that is factually incorrect or unverifiable.”
In practice, this shows up as:
- Invented facts — statistics, dates, or claims that don’t exist
- Invented references — citations to papers, laws, or documents that were never written
- Invented names — people, companies, products that don’t exist
- Invented tool parameters — fields and values generated during API or function calls
- Invented structure — extra fields added to JSON or other structured outputs
The danger isn’t that the output looks wrong. It’s that it usually looks completely right.
Why Uncensored Models Hallucinate More (and Differently)
To understand this, you need to understand what alignment training actually does at a behavioral level.
In well-aligned models, RLHF (Reinforcement Learning from Human Feedback) and related techniques teach the model specific uncertainty behaviors. When the model doesn’t know something confidently, it learns to:
- Refuse to answer
- Hedge (“I’m not certain, but…”)
- Ask for clarification
- Acknowledge the limits of its knowledge
These behaviors aren’t just PR polish. They’re epistemic signals , the model telling you when to trust its output and when to verify.
Uncensored models often strip out or weaken these behaviors in the process of reducing refusals. The result is a model that’s more cooperative, but one that’s lost its calibrated uncertainty. It doesn’t distinguish as clearly between “I know this” and “I’m generating something plausible.”
Research on model calibration shows that overconfidence , the mismatch between a model’s expressed certainty and its actual accuracy , is one of the primary risk factors in deployed AI systems. Uncensored models tend to be less calibrated than their aligned counterparts.
The Tool Calling Problem Is Worse Than You Think
Hallucinations in freeform text are annoying. Hallucinations in agentic workflows are a different category of problem.
Here’s a scenario that plays out constantly in production:
An AI agent running in LangChain or AutoGen needs to call an external API. The uncensored model , being cooperative , proceeds with the call instead of refusing. Great. But it invents a parameter that doesn’t exist in your schema. Or it passes a string where an integer is expected. Or it creates a field it inferred should exist based on context.
The API call executes. The workflow continues. The error is silent.
This is why uncensored models often look spectacular in demos and create subtle chaos in production. During a demo, you’re watching every output. In a real pipeline, you’re not.
Berkeley’s Gorilla benchmark, which specifically tests LLM function-calling accuracy, shows significant variance between models on real-world API calls. Hallucinated parameters are one of the most common failure modes across all models , and reduced uncertainty signaling makes them harder to catch.
A Concrete Example: Structured Output Drift
This one is subtle enough that it’s worth spelling out with actual data.
Say you’re building a receipt processing pipeline. The source document contains:
{
"merchant": "Store A",
"total": 42.50
}
An uncensored model ,asked to extract structured data , may return:
{
"merchant": "Store A",
"total": 42.50,
"category": "Groceries",
"tax": 3.82,
"payment_method": "card"
}
The model didn’t lie exactly. “Groceries” is a reasonable inference. “Card” is plausible. But none of those fields were in the source document. The model filled them in because they seemed like things that should be there.
If your downstream system ingests this JSON without validation, you now have fabricated fields in your database. And since the real fields are correct, the error may not surface until something downstream breaks in a way that’s hard to trace.
This is sometimes called schema hallucination , the model expanding or modifying structured output schemas beyond what was requested. It’s particularly common in uncensored models because the instinct to “be helpful” overrides strict adherence to the specified schema.
False Confidence: The Reason Hallucinations Are Dangerous
Here’s the uncomfortable truth about why hallucinations matter more in uncensored models than the raw frequency would suggest.
A model that expresses uncertainty when it’s wrong is actually quite manageable. You learn to cross-reference hedged outputs. You build review steps around low-confidence responses.
A model that sounds authoritative and detailed when it’s wrong is a fundamentally harder problem.
Research published in Science on AI-generated misinformation found that people are substantially worse at identifying errors in fluent, confident text than in uncertain or qualified text. The cognitive effect is real: confidence is a trust signal that bypasses scrutiny.
This is exactly the failure mode in many uncensored deployments. The output reads like something you can act on. The error gets into a report, a database record, a compliance filing, or a tool call before anyone realizes the model invented part of it.
The Freedom-Risk Relationship
There’s a clean way to think about this tradeoff that’s worth having explicitly in your mental model.
Every additional capability you unlock by removing alignment restrictions has a corresponding increase in the surface area of potential failure:
| More freedom to… | Introduces risk of… |
|---|---|
| Answer any question | Confidently wrong answers on edge cases |
| Call any tool | Hallucinated parameters and schema drift |
| Continue any workflow | Silent errors propagating through pipelines |
| Engage with sensitive topics | Outputs violating policy without flagging |
| Generate any structured format | Fields invented beyond the specified schema |
This isn’t an argument against uncensored models. It’s an argument for understanding that capability and reliability don’t automatically scale together. You can have a highly capable, unreliable model. Managing the gap between those two properties is the real engineering challenge.
Can You Eliminate Hallucinations?
No. And anyone selling you that outcome is selling you something else.
Even the most heavily aligned frontier models ,GPT-4, Claude, Gemini — still hallucinate. Meta-analyses on LLM reliability consistently find hallucination rates between 3% and 27% depending on domain, task type, and how strictly “hallucination” is defined.
The goal isn’t elimination. The goal is reduction and containment: designing your system so that when hallucinations happen (and they will), they get caught before they cause damage.
What Good Hallucination Management Actually Looks Like
Here’s the practical framework for deploying uncensored models reliably.
1. Schema enforcement at the output layer
Never trust the model to stay within a schema voluntarily. Use tools like Instructor or Pydantic to enforce structured output schemas and reject responses that add or modify fields. If the model invents a field, the validation layer catches it before it reaches your system.
2. Validation layers before downstream actions
Before any tool call executes or any structured data gets stored, run it through a validation step. Guardrails AI and NVIDIA NeMo Guardrails both offer frameworks for this. Think of it as a pre-flight check between the model and everything downstream.
3. Grounding with retrieval
Retrieval-Augmented Generation (RAG) significantly reduces hallucination rates by anchoring the model’s outputs to a specific, verifiable context. If the model can only respond based on retrieved source documents, the space for confabulation shrinks considerably.
4. Logging and anomaly detection
You can’t catch errors you’re not monitoring for. Log all model inputs and outputs in production. Build anomaly detection that flags unusual patterns ,unexpected fields, atypical value ranges, responses that don’t match expected formats. LangSmith and Weights & Biases both offer LLM observability tooling for this.
5. Human review on high-stakes outputs
Not everything needs a human in the loop. But for outputs that feed compliance systems, financial records, or customer-facing content, mandatory human review checkpoints are worth the friction.
6. Benchmark your specific model before deployment
Don’t assume hallucination behavior from general benchmarks. Test your specific model on your specific use case. RAGAS provides an evaluation framework for measuring hallucination rates in RAG pipelines. Run it against your actual data before you go live.
Why This Is the Defining Engineering Challenge
Here’s the framing that matters for anyone building production AI systems:
The difference between an AI system that succeeds and one that fails in production usually isn’t model capability. Most modern LLMs , aligned or uncensored , are capable enough for a wide range of tasks.
The difference is reliability engineering around the model.
The best AI systems aren’t the ones that never make mistakes. They’re the ones where mistakes get caught before they create problems. That means validation pipelines, monitoring, schema enforcement, and the organizational processes to respond when something breaks.
Uncensored models shift more of that work onto the deploying organization. That’s fine , but it has to be acknowledged and planned for, not discovered after the fact.
The Bottom Line
Uncensored models will keep growing in adoption, and for good reason. They’re genuinely more useful for a significant class of tasks where alignment restrictions cause more friction than protection.
But hallucination isn’t a minor footnote in the risk profile , it’s the central engineering challenge that determines whether these deployments succeed or quietly fail.
Build the validation layer. Monitor the outputs. Enforce the schemas. Add human review where it matters.
That’s not a reason to avoid uncensored models. It’s the price of admission to using them well.