
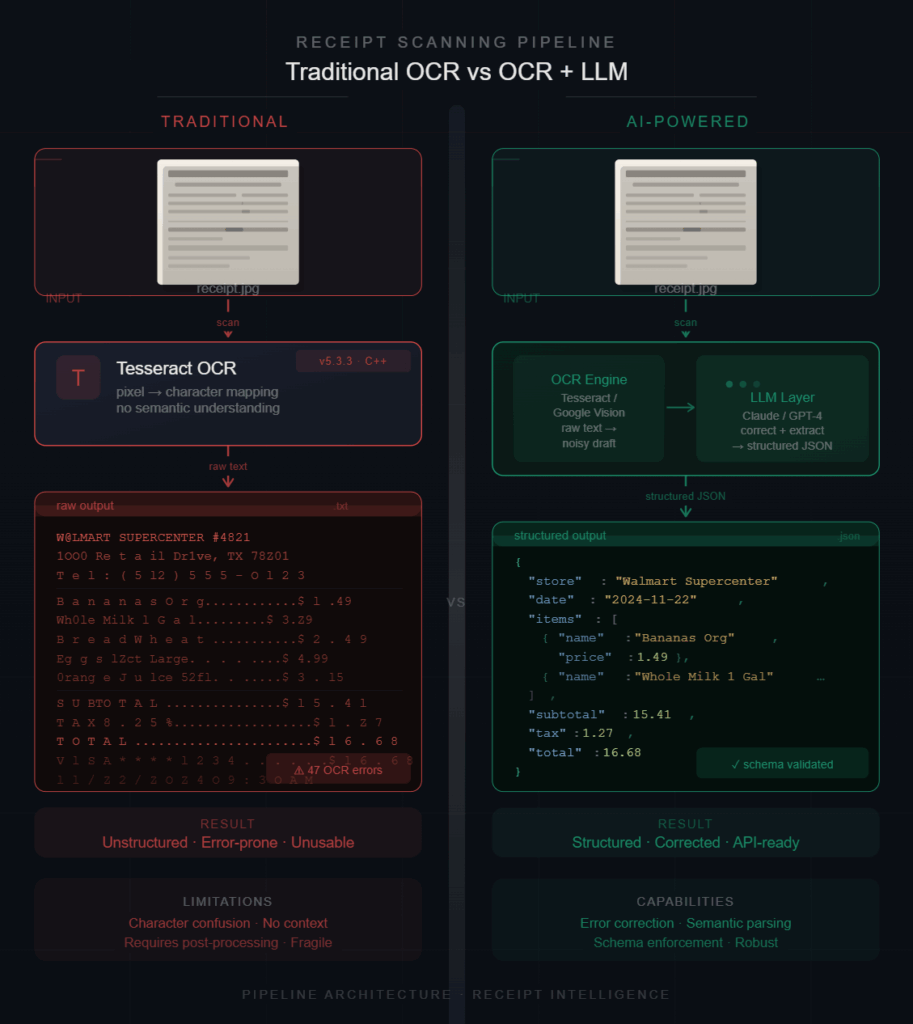
Receipt extraction initially appears to be a straightforward OCR problem.
Scan the document.
Extract the text.
Convert it into structured data.
But once real receipts enter the workflow, the problem becomes significantly more complicated.Different OCR engines behave differently. Some preserve structure well but miss characters. Others extract readable text while destroying semantic grouping entirely. Language models may reconstruct missing structure, but they also hallucinate, drift semantically, or generate unstable outputs.
This creates an important engineering question:Which combinations of OCR systems and AI models actually work reliably for structured receipt extraction?
To explore this, we tested multiple OCR and local AI model combinations across approximately 100 real receipts using local CPU-based workflows.
The goal was not creating perfect benchmarks. The goal was understanding operational behavior:
- structure quality
- semantic stability
- JSON reliability
- hallucination patterns
- runtime performance
- workflow consistency
This article explores what worked, what failed, and why receipt extraction turned out to be much more about systems engineering than OCR accuracy alone.
Introduction
One of the easiest ways to misunderstand AI document extraction is to evaluate systems only using clean examples. Clean receipts are easy. Real receipts are not.
During experimentation, the workflow encountered:
- faded thermal printing
- multilingual characters
- skewed images
- inconsistent layouts
- overlapping discounts
- broken line spacing
- malformed totals
- compressed financial sections
And once OCR structure began collapsing, the language models often struggled as well. This revealed something important very quickly: Receipt extraction is not simply about extracting text.
It is about reconstructing semantic structure from noisy operational documents.That distinction changed how we evaluated both OCR systems and AI models entirely.
Why OCR Alone Was Not Enough
Traditional OCR systems such as Tesseract OCR are extremely good at character recognition. But structured receipt extraction requires more than readable text.
Operational workflows need:
- semantic grouping
- totals identification
- product separation
- discount association
- financial consistency
- structured formatting
And surprisingly, OCR outputs that looked visually readable often became difficult for structured extraction pipelines. The problem was not always text quality itself. The problem was structure preservation.
The Testing Workflow
The experimentation pipeline combined:
- OCR systems
- local LLM inference
- structured prompting
- deterministic validation
The architecture looked like this:
Receipt → OCR Engine → OCR Text Output → Local LLM → Structured Extraction → Validation Layer → Final JSON
The workflow was tested across approximately 100 real receipts using local CPU-based inference.
The goal was understanding:
- operational stability
- extraction consistency
- semantic preservation
- runtime behavior
- hallucination frequency
instead of purely academic accuracy scores.
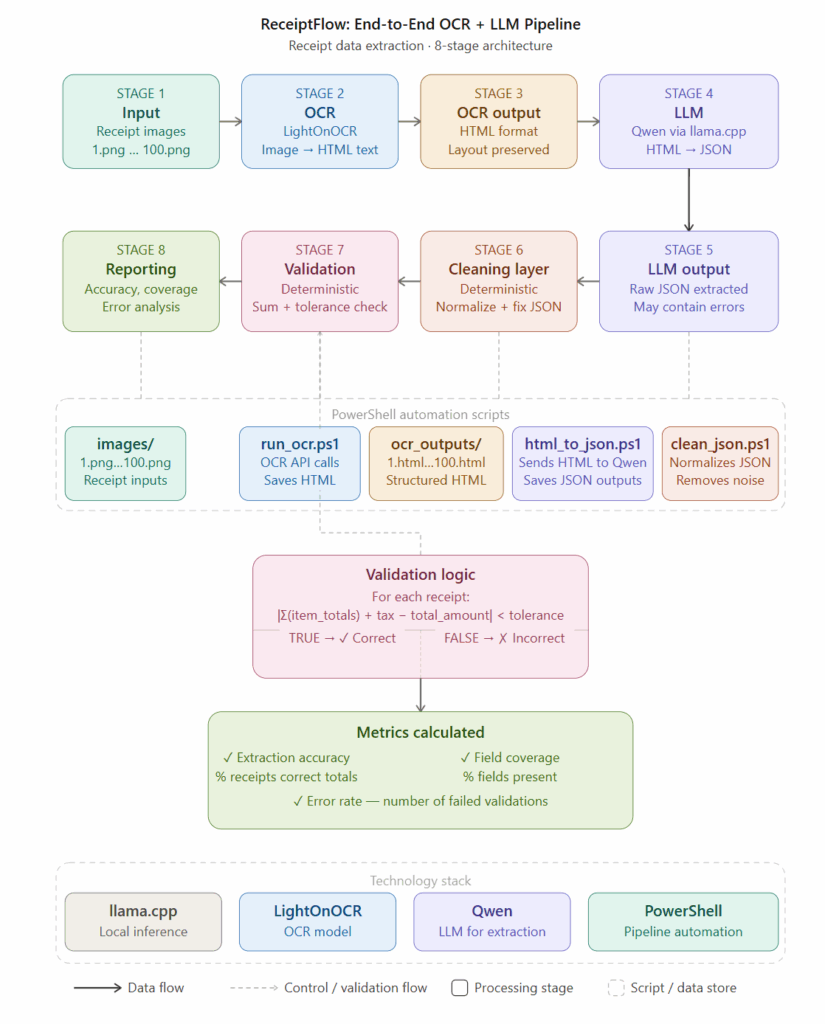
Figure: OCR + LLM benchmarking workflow for structured receipt extraction
OCR Systems Tested
Several OCR systems were evaluated during experimentation.
Tesseract OCR
Tesseract served as the primary baseline OCR engine.
Advantages:
- open-source
- lightweight
- CPU-friendly
- easy local deployment
However, real receipts exposed several limitations:
- structure collapse
- merged line items
- inconsistent spacing
- poor semantic grouping
Interestingly, many outputs remained readable for humans while becoming structurally unstable for AI extraction systems.
Why OCR Formatting Mattered More Than Accuracy
Initially, we assumed OCR accuracy would be the most important metric.
After repeated testing, that assumption changed completely.
The extraction pipeline cared less about perfect character recognition and far more about semantic structure preservation.
Examples included:
- totals remaining separated
- discounts attaching correctly
- line items staying grouped
- taxes remaining isolated
- sections maintaining hierarchy
This dramatically affected downstream AI extraction quality.
In many cases:
- worse OCR + better structure
performed better than:
- cleaner OCR + collapsed formatting
That insight changed how we evaluated OCR systems entirely.
Conclusion
Testing OCR and AI models for structured receipt extraction revealed something much larger than simple benchmarking results.
Reliable extraction workflows depended far more on:
- structure preservation
- validation systems
- semantic consistency
- workflow engineering
than raw OCR accuracy or model size alone.
The most operationally useful workflows emerged not from perfect AI reasoning, but from combining:
- OCR
- local language models
- deterministic validation
- structured preprocessing
- operational workflow design
That architectural shift is likely becoming one of the defining patterns behind modern enterprise document automation systems.