
In the 21st century, as data grows and diversifies, many organizations are finding that traditional methods of managing information are becoming outdated. According to recent research, the average company sees the volume of their data grow at a rate that exceeds 50% per year. Companies are finding new ways to organize their immense amount of data accordingly.
In this article, we will dive deep into understanding what exactly a Data Lake is and its benefits to an organization.
Introduction to Data Lake
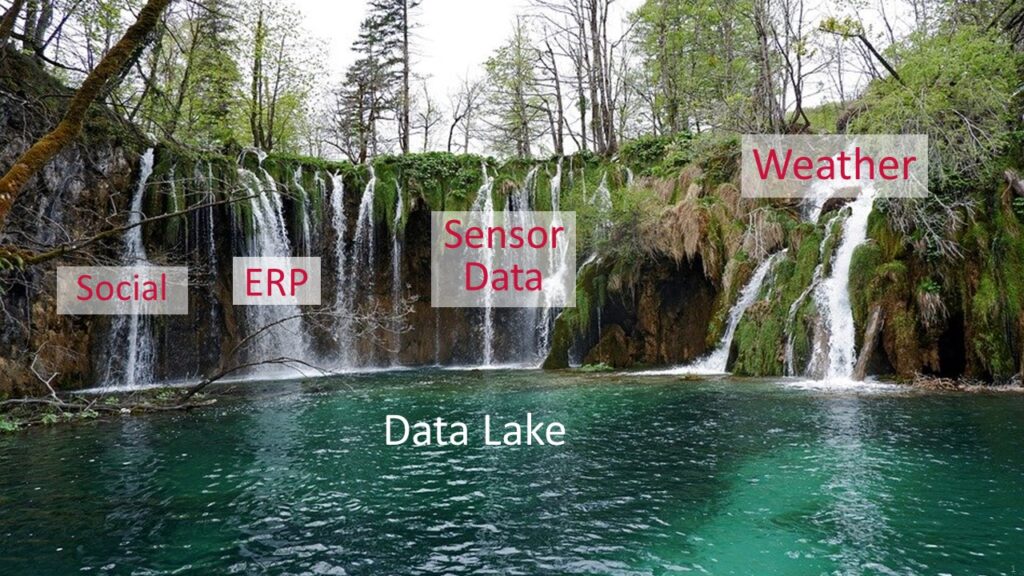
A data lake is a centralized Data storage that can store different data types from structured data to unstructured data. As the amount of data in a company or business grows exponentially, the data must be stored somewhere.
Data Lake is an approach to Big Data architecture that focuses on storing unstructured, structured, and semi-structured data in a single repository.
Data lakes can store the data in a native format, without the need for limits or storage restrictions. It can store relational data from business applications while also able to store non-relational data from mobile apps, IoT devices, and social media.
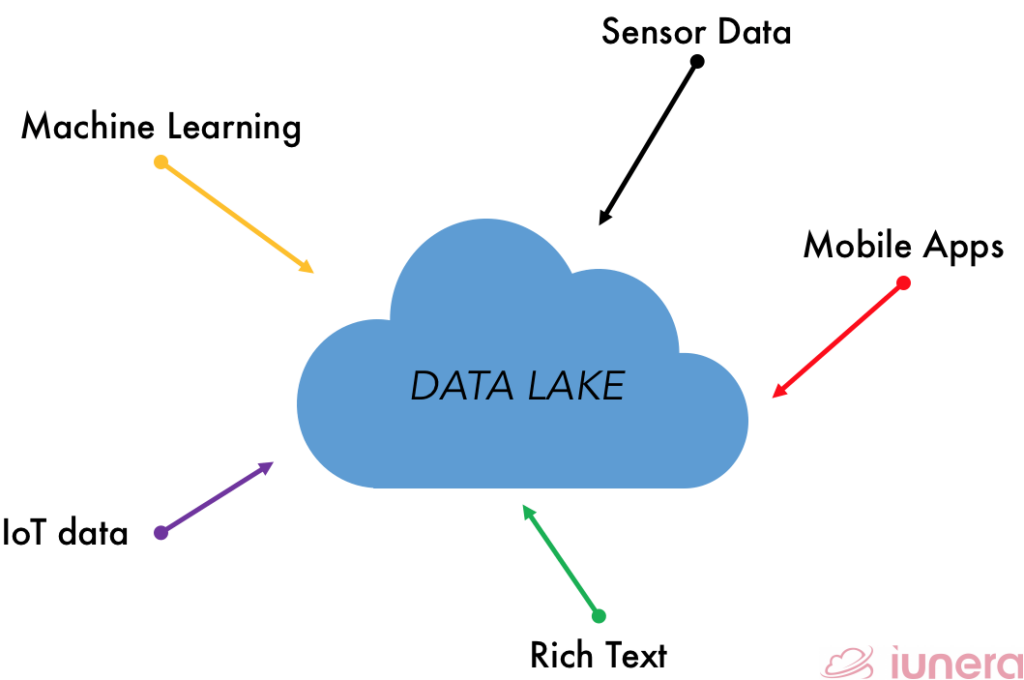
The bigger aim of a Data lake is to bundle data in a cost-effective way to store all various types of data of an organization for processing.
Why is Data Lake important?
There are a couple of reasons why incorporating a Data lake storage is important to organizations. Listed below are some of the reasons why a Data lake is important and useful.
1. Building a PROPER data storage
With the recent increase of unstructured and structured data, analyzing data becomes a mess without a standardized system or model. A Data lake can transform the business by providing a singular repository of all the organization’s data.
2. Organise data EFFECTIVELY
Data lake analogy will help bring a common understanding of the benefits of distributed computing systems that can handle multiple types of data, in their native formats, with a high degree of flexibility and scalability. All of this starts with organizing the data effectively.
3. IMPROVE data handling and analytics
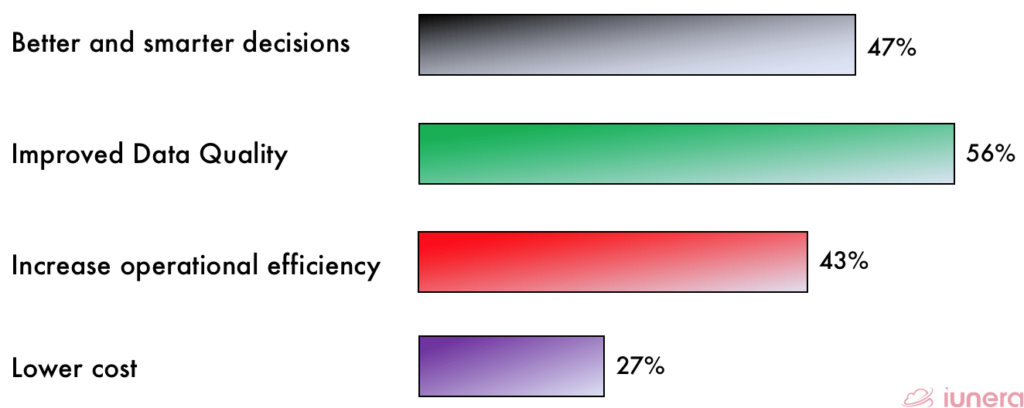
If an organization does analytics with IoT or sensor data, a Data lake will definitely make it easy to store and run analytics on machine-generated data to discover ways to reduce operational costs, increase analytical intelligence with Machine Learning and overall quality. The usage of Machine Learning and Artificial Intelligence can be used to make profitable predictions.
However, the main shortcoming of a Data Lake is that its main focus is batch processing with scheduled jobs (map-reduce, Spark, Python) and the delay that comes out of its batch legacy.
The Data Lake Architecture
A Data lake is a simple, large storage repository that holds a vast amount of raw data in its native format until it is needed. Data lake fits a familiar technology pattern where a new concept emerges, and it is adopted by organizations and businesses to harness the power of the data.
The changing and dynamic economics, architecture, and optimization of business practices allow teams to amend and mold these solutions into their enterprise data stacks in a manner that fits their use case.
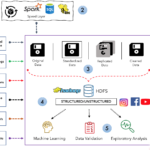
The diagram below will summarise what is called the Data lake architecture and explain each block in the architecture and what it contains.
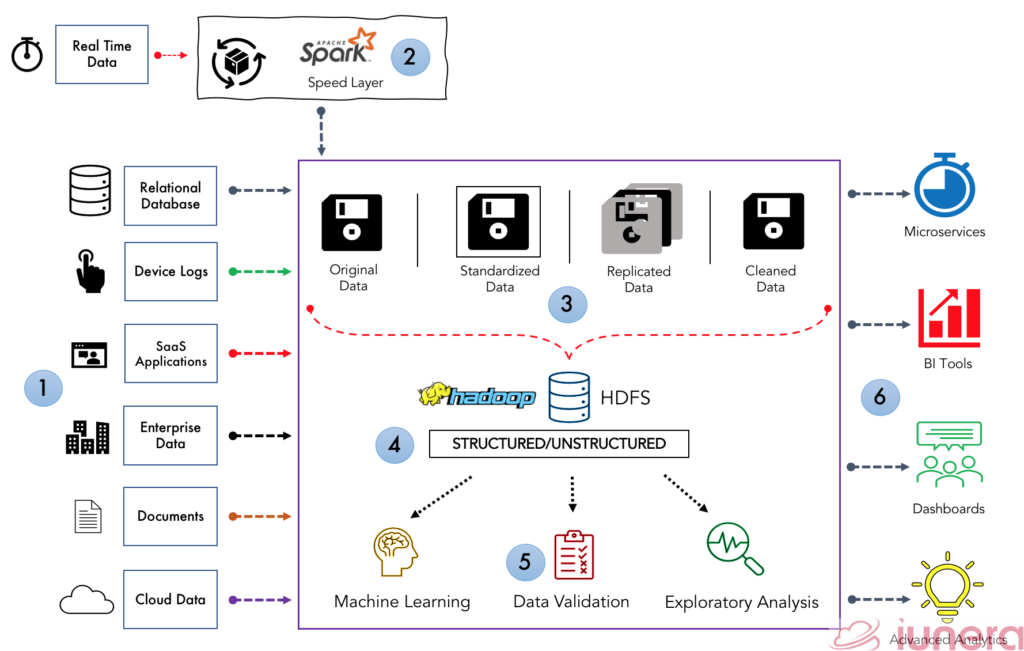
(1) Data Sources
The data lake always has a data source where different data types will be fed into the data lake.
These data sources can range from structured data such as from a relational database or unstructured data such as from social media as well as Big Data.
(2) Batch Data Processing
In most cases, the data ingested by the data lake are not real-time – most data into the data lake are in a batch format. Real-time data frameworks such as lambda architecture are used since they would need to handle stream processing before being placed in the data lake.
Frameworks including Kafka Streams, Spark streaming is particularly used here for stream processing.
(3) Data Ingestion
A data lake isn’t a single repository where data can just be placed without any processing or cleansing.

There is abundant processing done to ensure the data is in proper shape before moving it to the next pipeline.
- In most data lakes, the injected data is standardized, improving performance in data transfer from raw to curated. Even if the raw data is stored in its native format, standardized, we choose the format that best fits cleansing.
- Cleaning of data is important as it allows a better structure for analysis. Also, data is transformed into proper and consumable size data sets, stored in files or tables.
(4) Data Storage
The data lake can store the mass different types of data (structured data, unstructured data, log files, real-time data, images, medical scans, social media and etc) to correlate many different data types. The key thing here is that business is moving to modern tools like Hadoop, Cassandra for storage purposes.

While Hadoop technologies are most common in many data lakes, they do not reflect the architecture. It is essential to recognize that a data lake should reflect an approach, strategy, and architecture, not technology.
(5) Data Analysis
The presence of a data lake allows various functions in the organization for example – data scientists, data developers, data engineers, and business analysts to access data with their choice of analytic tools and frameworks.
This includes open-source frameworks such as Hadoop, Apache Spark, and commercial offerings. It allows analytics such as Machine learning, Data Validation, Data Analysis, etc. to be performed without moving the data to separate storage.

The power of Machine learning directly integrated within the data lake will allow forecasting likely outcomes and suggest actions to achieve the best result.
Data Scientists use the data from the data lake to perform Data Science activities on it. Those Data Science activities can be to process, analyze, clean, refine, or transform the data.
(6) Reporting and Applications
A modern data lake nowadays is connected to business intelligence (BI) tools such as Tableau, Metabase, Apache Superset and help prepare data for analysis to build reports and dashboards
Microservices can also help make the development, deployment, and maintenance of the data lake more flexible and agile. The essence that it is directly connected to the data lake enables it to run different independent services for different applications, all from a single data source.
5 Advantages of using Data Lake
Listed below are some of the major advantages that a data lake will offer:
Scalable System
Similar to a data system, a data lake has the potential to be enlarged to accommodate that data grows exponentially without changing the whole system. Also, the computations are exponentially scalable by using frameworks such as Map-Reduce or Spark.
Accepts all Data Sources
From handling structured, unstructured, or real-time data, data lake can process accordingly with Hadoop’s help to store the multi-structured data from a diverse set of sources. In simple words, the data lake has the ability to store logs, XML, multimedia, sensor data, binary, social data, and many more
Advanced Analytics
A data lake can harness the power of Machine learning and Artificial Intelligence to recognize items of interest that will power decision analytics with high accuracy and robustness
Native Format
The Data lake eliminates the need for data to be processed before being fed into the data lake; it provides iterative and immediate access to the raw data in the native format.
Variable Structure
Data lake creates a unique platform where we have the ability to apply a structure on varied datasets in the same repository enabling processing the combined data in advanced analytic scenarios.
In Summary
Building an efficient data lake system is not just about the data – it’s about what the data lake can offer to other parties. Data lake creates a unique platform where we have the ability to apply a structure on varied datasets in the same repository.
Important paradigms of how data should be handled are discovered through implementing a data lake system from data Ingestion, data storage, data quality, data Auditing, data exploration are some important components of a data lake model.
Are you looking for ways to get the best out of your data?
If yes, then let us help you use your data.
Quick FAQ
What is a Data Lake?

A data lake is a centralized repository or database that can store different data types from structured data to unstructured data
What kind of data can a Data Lake store?

It can store relational data from business applications to non-relational data from mobile apps, IoT devices, and social media and offer high data quantity to increase analytical performance and integration
Why is Data Lake so important for every organization?

1. Building a PROPER data storage
2. Organise data EFFECTIVELY
3. IMPROVE data handling and analytics
4. INCREASE operational efficiency
What is Data Lake architecture?
A Data lake is a simple, large storage repository that holds a vast amount of raw data in its native format until it is needed
What are the 6 important blocks of a Data Lake architecture
1. Data Sources
2. Batch Data Processing
3. Data Ingestion
4. Data Storage
5. Data Analysis
6. Reporting and Applications
Top 5 Advantages of a Data Lake

1. It is a very scalable system
2. It accepts all Data sources
3. Can perform advanced analytics
4. Accepts data in its native format
5. Can hold data in a variable structure