
One of the dimensions of data quality is availability. The data users in an organisation need to be able to search and access the data they need to work. An organisation-wide data catalog can help the users find data. Here’s how a data catalog does it.
What is a data catalog?
The definition of a data catalog is:
An organised, detailed inventory of data assets across all data sources of an organisation
where ordered, indexed and easily accessible metadata can
help data professionals quickly find the most appropriate data
for any analytical or business purpose.
Let’s get a few things clear.
- data assets
- what metadata is
- the role of a data catalog in making data easily searchable and accessible
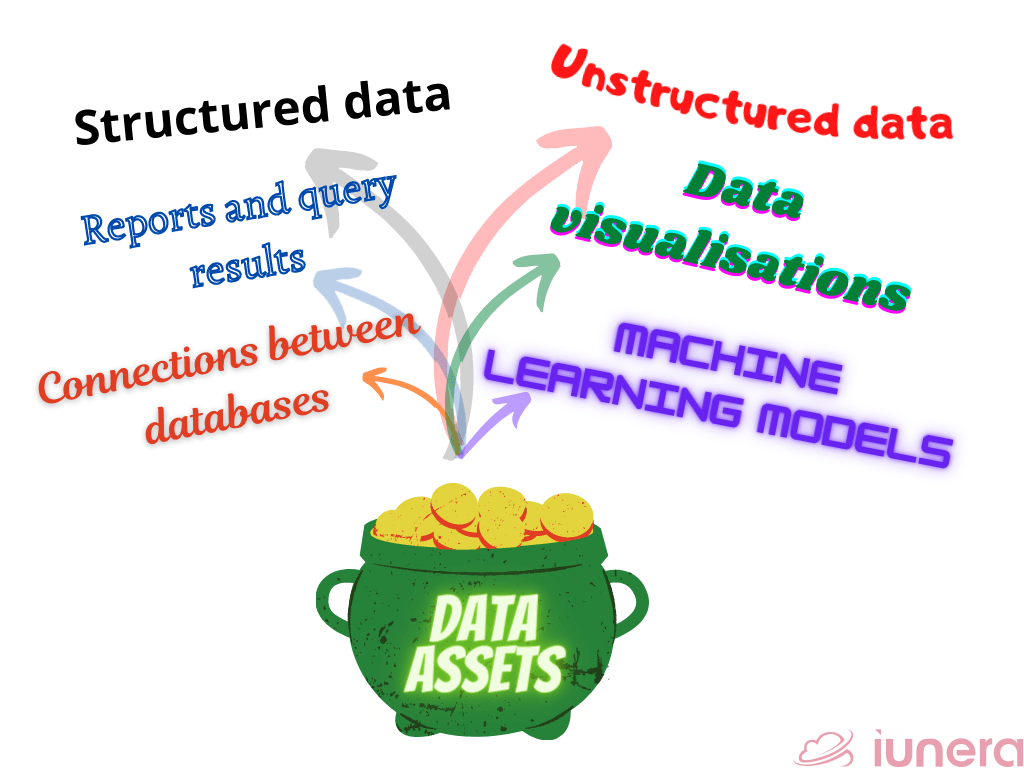
Data assets
A data asset is defined as “a system, application output file, document, database, or web page that companies use to generate revenues.”
The data assets in a data catalog include:
Metadata
Metadata is the description of a data asset that makes it easier to find and analyse.
If you guys remember browsing and borrowing books at a library, this popular example of a library catalog card might help.
The card has information about a book such as the title, author, topic, publication date, edition, summary and which section of the library it is.
Such information which acts as the metadata of the book makes it easier for a librarian or reader to find the book.
The same applies to the metadata of a data catalog.

The data catalog’s role
A data catalog has several capabilities that allow users to:
- Search the catalog and access data, which is really helpful for self-service analytics.
- Automate the evaluation and recommendation of potentially relevant data.
- Make sure the data utility complies with regulations.
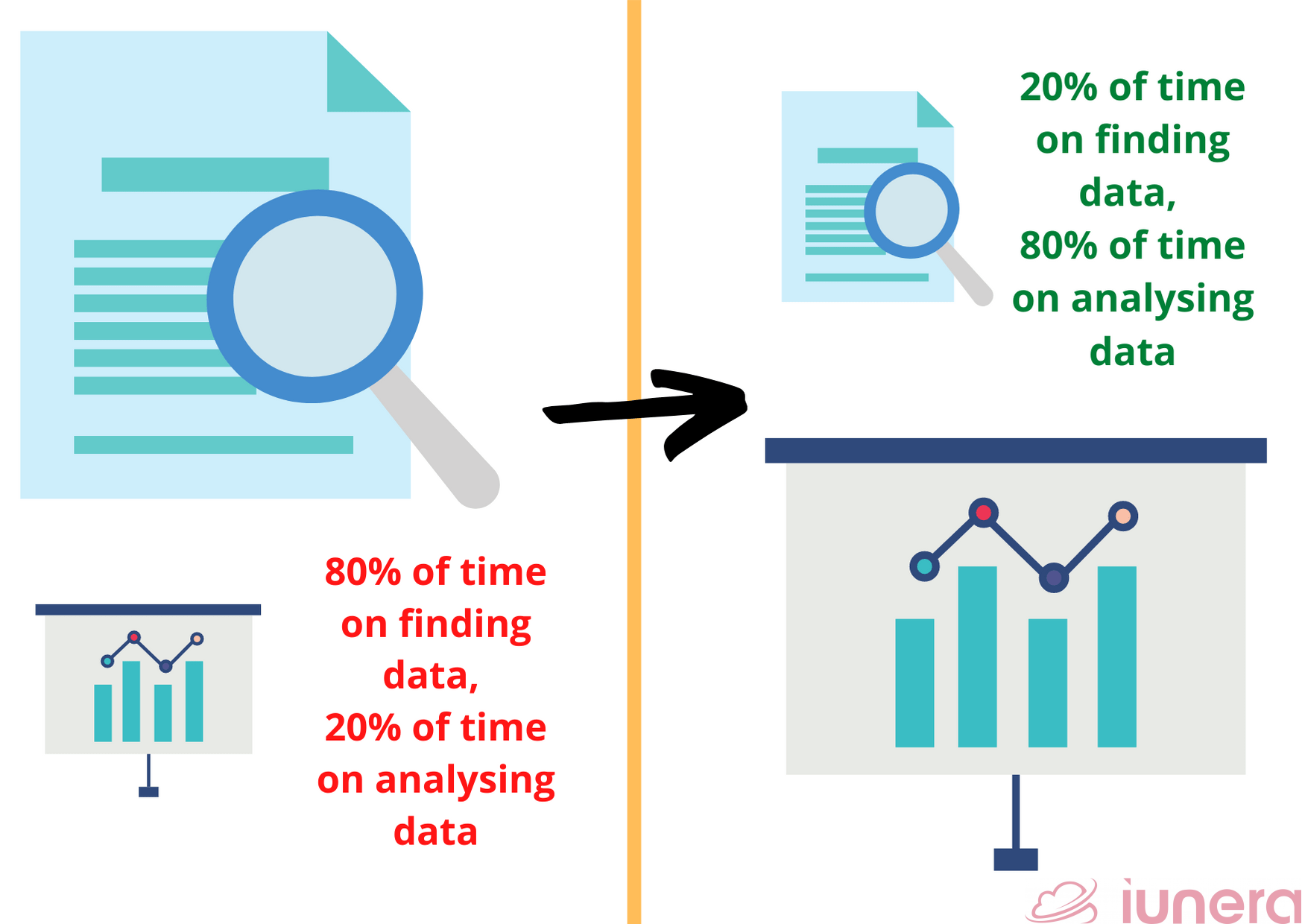
The data catalog makes this possible by addressing challenges related to the higher amount of time and effort wasted on finding relevant data compared to using data.
If data scientists spend a bigger chunk of their workday on combing through data lakes that have turned into data swamps, it means that there are problems with the data sets.
The problems that data scientists have to deal with include dark data taking up space in the database and the lack of a common vocabulary reflecting the lack of standards.
As a result, they face difficulties in accessing data, tracing their sources and assessing their quality.
It may seem easier for them to just surrender and not deal with these data challenges but the consequences of leaving them unchecked may outweigh the impact of fixing them.
So, obviously, by addressing the challenges mentioned, the organisation can benefit from:
- Improved trust and confidence in data of high quality, leading to more effective decision-making.
- Reduced data risk due to compliance with regulations.
- Increased efficiency from having a unified view of all data and reducing dependence on the IT department.
So, what capabilities should a data catalog have?
The capabilities that a data catalog should have in order to address the challenges and provide the benefits stated above are:
User-friendly search experience
All data users should be able to search through the data catalog themselves, whereby they can quickly find results based on the metadata searched and receive relevant recommendations just like on Netflix.
Automation
Automation removes the need to connect data sources manually, hence, saving time and effort for more important tasks.
Simplified compliance
Compliance can be difficult to keep up with, so a data catalog should simplify compliance by profiling data assets, figuring out their relevance to specific regulations and automatically categorising them for future reference.
Connecting various data sources to a single source of truth
All the data assets as well as their metadata in the organisation should be connected to the master data using various tools for business intelligence, data integration, SQL queries, enterprise apps, data modelling, etc.
Support for data quality
For a data catalog to do its job in making data searchable and accessible, the organisation should implement the best practices of data quality management (DQM) including root cause analysis, setting data quality rules and using data quality tools.

So far, we found these different data catalog products…
Examples of data catalog tools made by big companies to build their own data catalogs are:
- Google Cloud’s Data Catalog
- LinkedIn’s DataHub
- Facebook’s Nemo
- Shopify’s Artifact
- Lyft’s Amundsen
- WeWork’s Marquez
- IBM’s Watson Knowledge Catalog
- Microsoft Azure’s Data Catalog
To show what a data catalog looks like, let’s use the US Geological Survey (USGS) Science Data Catalog (SDC) as an example. Look at the screenshots below.
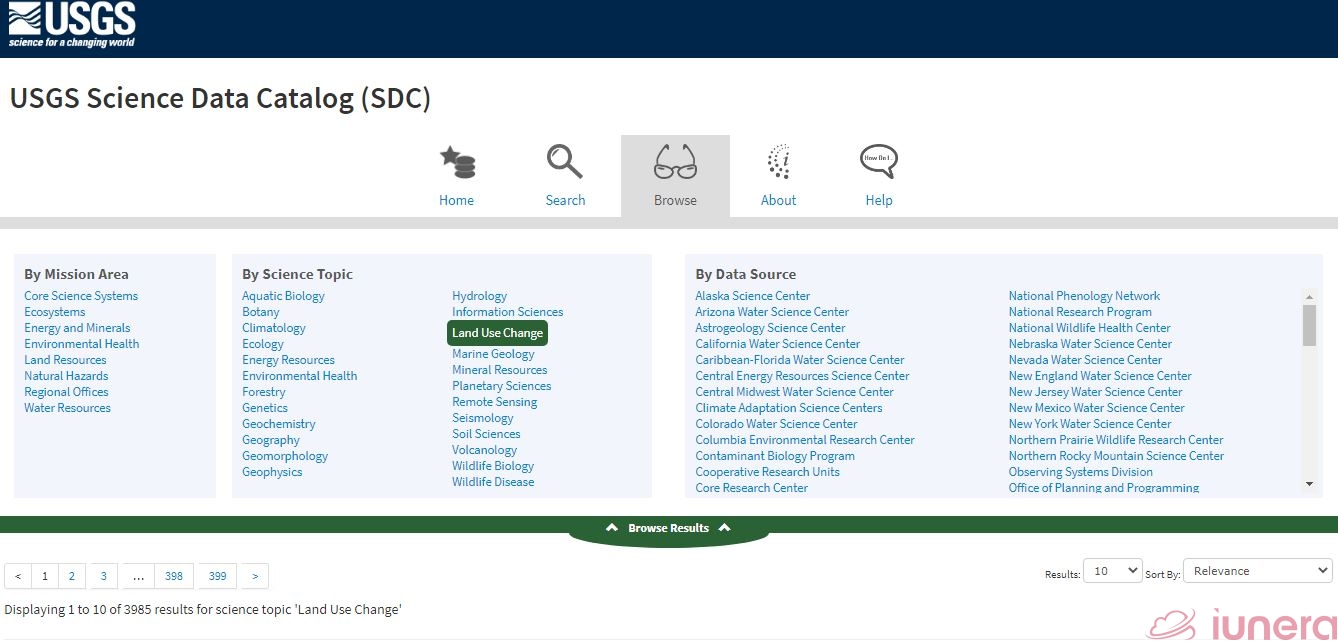
On the USGS SDC page, users can either search using the keywords they have in mind or browse through the categories set by USGS.
These categories are Mission Area, Science Topic and Data Source, each of which contains sub-categories.
If a user chooses to browse and clicks on the subcategory Land Use Change under the category Science Topic, the user will receive the list of data set results as shown below.
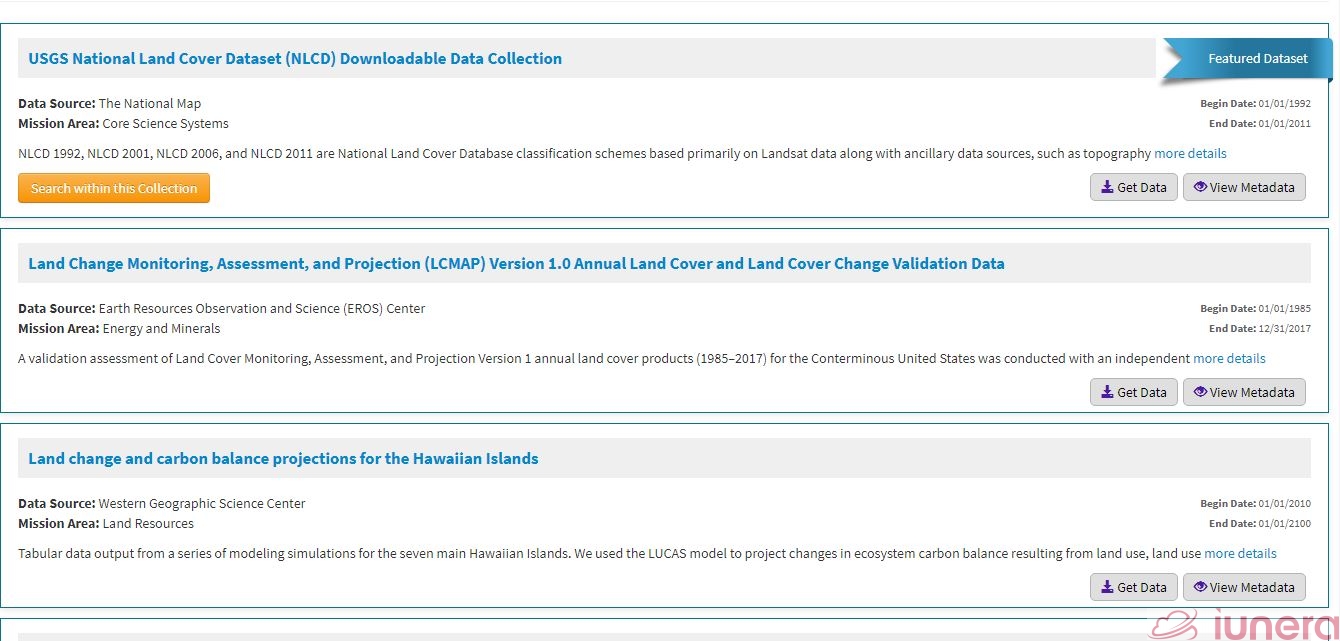
In this list, the user can see what the data sets are and view the metadata of the data sets by clicking on the “View Metadata” button on the right side of the screen.
When the user clicks on the “View Metadata” button for the data set “USGS National Land Cover Dataset (NLCD) Downloadable Data Collection”, the user will see the metadata of that data set as shown below.
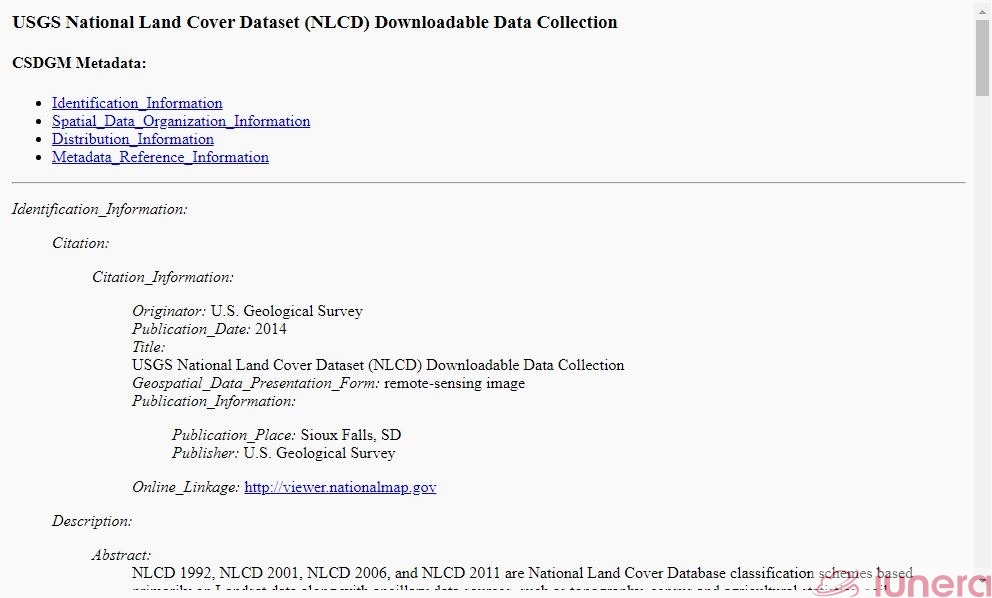
In this way, the user can identify the data set’s citation information, description, spatial information, metadata reference, and so on to effectively decide whether this data set meets the user’s data needs.
Conclusion about data catalogs
A data catalog is defined by the various data assets it holds, the metadata describing these data assets and its capabilities in making relevant data more available for any analytical or business use.
Companies use metadata to find and identify data assets with the aim of generating revenues out of the data analysis.
Data catalogs are able to optimise the company’s returns on data by optimising efficiency in terms of the time and effort spent on finding and preparing data compared to analysing data.
In a recent online conference, I’ve witnessed data scientists having a discussion about how data preparation is an integral part of a typical workday for data scientists.
Perhaps, using data catalogs might help minimise data prep time so that data scientists can focus more of their time and energy on analysis instead.