
What can the union of Machine Learning and Big Data Curation offer?
The rise of Artificial Intelligence (AI) and new advancements in Machine Learning (ML) in diverse applications has accelerated their growth. For every ML model, the quality of data that it is learned on is essential. On the other hand, curation of information is a necessary process to ensure accurate data handling.
This article will introduce the concepts of ML and Big Data curation and why the curation process is necessary for ML.
Let’s Talk Data
In every business or organization, Data is fundamental to its decisions. A company’s ability to gather the right data, interpret it, and act on those insights is often what will decide its success level.
Business data can come from many different sources such as IoT, media, tweets, financial data, documents, etc.
Moreover, data can be generated in many ways. The data sources can originate from first, second, or third-party data.
- First-party data is the data you collect directly from your audience.
- Second-party data is the data you buy from a partner company that collects from its audience.
- Third-party data is mainly data collected from various data owners by an aggregator and sold as a packaged data set.
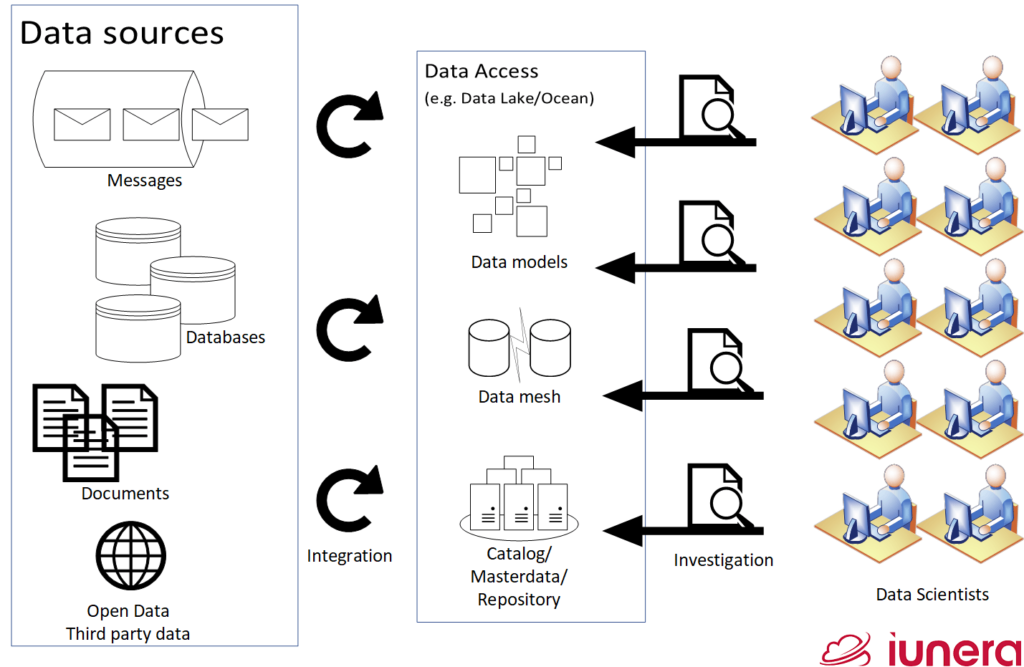
Data is becoming an essential asset for many companies, but studies show that most organisations use only a small part of the information they manage.
With data volumes growing exponentially, and the increasing variety and heterogeneity of data sources, how can enterprises leverage more of their data?
Machine Learning
The interest and the breakthroughs in AI, especially in ML, have multiplied and bloomed exponentially since the 2000s. ML is a method of data analysis that automates analytical model building.
It is a technology branch that allows computer systems to learn from vast amounts of data, identify patterns within images and text, and make statistical decisions with minimal human intervention.
ML powers almost all the social media applications nowadays from YouTube, Google, Facebook, Instagram, Baidu, Twitter, etc. Even voice assistants like Siri, Google Assistant, and Alexa are powered through ML, particularly in NLP and Speech Recognition.
Later on, in the article, we will look at how ML can be applied to the whole data curation process to improve efficiency and possibly automate specific tasks.
Meaning of Big Data Curation?
As the number of AI companies grows worldwide and its subsequent applications become even more pervasive, engineers everywhere are confronted with a grim reality.
Once stakeholders overcome biases or scepticism, the fundamental of developing an application is often neglected, and that is Big Data curation.
Data curation in ML is the organization and integration of data collected from various sources. Big Data curation involves annotation, publication and presentation of the data such that the value of the data is maintained over time, and the data remains available for reuse and preservation.
Data curation was much more manageable when organisations only had a few data sources to extract data from. But the world has changed. Far too many data are being produced daily from multiple sources.
To add on, with the proliferation of Big Data, enterprises have many more disparate data sources to extract data from, making it much more difficult to maintain a consistent method to curate data.
Further complicating the problem is the fact that much of today’s data is created in an ad hoc way that can’t be anticipated by the people intended to use data for analysis, and when the information is lost or not applicable anymore, it is then left out forming what is called a data swamp. This is why Big Data curation is important.
Common Big Data Curation Activities
The core meaning of data curation can vary among roles. From academic researchers to Data Scientist, the activities they perform for the Big Data curation process can differ. In this section, we have highlighted some of the most common data curation activities.
Citing the Data
Display of a citation for a data set to enable
appropriate attribution by third-party users in order to formally incorporate data reuse
De Identification
Redacting or removing personally identifiable or protected information
(e.g., sensitive geographic locations) from a data set
Adding Metadata
Information about a data set that is structured (often in machine-readable
format) for purposes of search and retrieval. Metadata elements may
include the basic information that you want to communicate include the meaning of column headings, the units in which a measurement value is reported, value type and parameters, and the methods of data collection and analysis
Validation of Data
The review of a data set by an expert with similar credentials and subject
knowledge as the data creator to validate the accuracy of the data
Importance of Data Curation
As we move towards a more digital future, organisations are forced to either adopt the digital-driven path or lose the chance to fit in with the digitally advanced companies out there.
Studies have shown that most organizations use only about 10% of their collected data, data that remains scattered in silos and varied sources across the organization. Hence this is why Big Data curation is important.
Big Data curation also acts as a bridge between many different departments and teams in an organisation. Big Data curation facilitates the process of collecting and managing the data that all these stakeholders can make use of it in their respective ways.
In other ways, a proper Big Data curation pipeline organises the data that keeps piling up every moment. No matter how large the datasets may be, Big Data curation techniques can help us systematically manage so that the data analysts and scientists can access it in a most suitable format.
With data volumes growing exponentially and the increasing variety and heterogeneity of data sources, getting the data you need ready for analysis has become a costly and time-consuming process for Big data curation.
Goals of Data Curation
Big Data curation also means managing data that makes it more useful for users engaging in data discovery and analysis.
The whole Big Data curation meaning is to complete specific requirements individually set by organisations or businesses.
Let’s take a look at some of the goals that a proper Big Data curation pipeline can achieve.
- Provide a better linkage between data of different types so that the data can be searched when needed
- Curation can help to make sense out of the data which might avoid data from being unused.
- Data quality can be evaluated with proper Big Data curation. The better the data curation, the higher the data quality (in most cases)
- Better curated data offers better reusability to researchers and engineers.
- Big Data curation helps to maintain and preserve the value of the data regardless of the type.
The Big Data Curation Pipeline
Let us take a look at the data curation pipeline below.
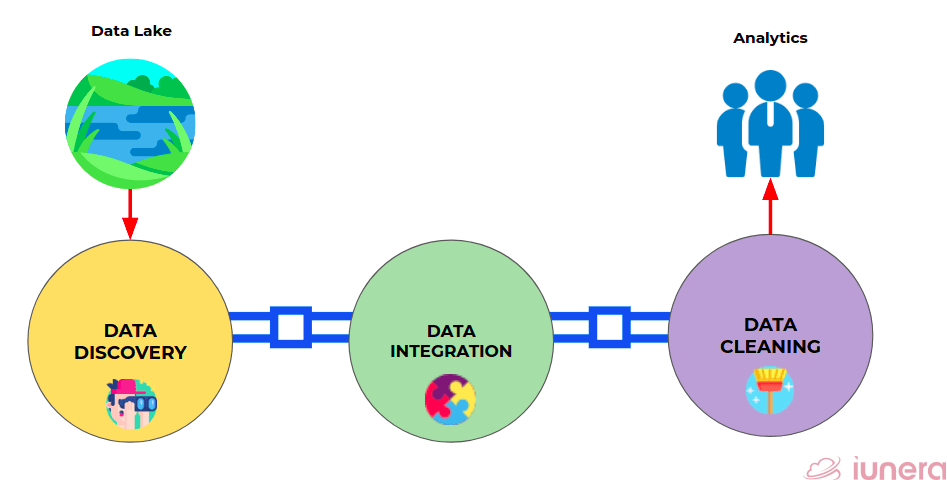
Data Lake
A data lake is a centralized data storage that can store different data types from structured data to unstructured data. As the amount of data in a company or business grows exponentially, the data must be stored somewhere. Data lakes can store the data in a native format, without the need for limits or storage restrictions. This is the first process of a Big Data curation pipeline.
Data Discovery
Data Discovery is the process of identifying relevant data for a
specific task. In most enterprises, data is often scattered across
many tables that could range in the tens of thousands.
It can be said as a process for managing data from multiple sources by identifying patterns with the help of guided advanced analytics
Data Integration
Data integration is the process of combining data from different sources into a single, unified view. Integration begins with the ingestion process and includes steps such as cleansing, ETL mapping, and transformation
Data Cleaning
Data Cleaning is the general problem of detecting errors in
a dataset and repairing them to improve the quality
of the data.
This includes qualitative data cleaning which uses
mainly integrity constraints, rules, or patterns to detect errors and
quantitative approaches are primarily based on statistical
methods.
Analytics
At the end of the Big data curation pipeline is analytics. A robust and high-quality data curation pipeline will allow business and analytics teams to produce actionable business intelligence with the store’s data.
Better Big Data Curation using Machine Learning

In an organisation, most decisions are based on the processed data or curated data taken from many different sources. But there is a flaw. Multiple transformations and calculations often manipulate a data set before it hits the desk of a business decision-maker.
Studies have shown that ML can generate a higher quality of data during the Big Data curation process. Below are some of the points:
- Create and enrich data assets in an efficient, user-friendly way
- Maintain high-quality data by supporting proactive and reactive data maintenance
- Manage the data life-cycle, especially when it comes to sensitive data
- Increase the use of data by improving data discovery by users, specifically by data scientists by using recommendations or classifications
People need to understand these nuances and how to accurately interpret and trust the data before they can rely on it to make decisions.
Machine Learning is the science of getting computers to learn and act like humans do, and improve their learning over time in an autonomous fashion, by feeding them data and information in the form of observations and real-world interactions
Data curation – and more recently, automated curation technology that relies on ML algorithms – is emerging as the key, missing ingredient to creating a culture that understands and embraces data.
Let us discuss some of the more important activities in Data Mining that can be used in Big Data curation.
Provide Reusability of Data
At the centre of data curation is the notion of a data set. Big Data sets must be created in a way that they are reusable components – anyone conducting analysis should share and expect data sets that they create to be re-used.
In the context of ML, the specific algorithm can be applied during the curation process to enable the contents of the data to be reusable.
One way is to allow the algorithm to iteratively improve the data based on certain feedbacks to allow a broader usage of the Big Data. Re-usability is key to self-service at scale.
Automated Maintenance of Data
Often times in the data curation pipeline as discussed above, data integration across multiple systems will lead to inconsistencies such as errors in data, incorrect rules, and biases.
We need some processes within the data curation pipeline to repair the patterns, associate certain rules, and even detect outliers present in the data.
ML-assisted data maintenance (reactive: data correction; proactive: business rules) and data unification (matching and deduplication) can be applied to evade this.
Accurate Classification of Data
Classification is a data curation function that assigns items
in a collection to target categories or classes. This is particularly important whereby large amounts of data are taken from a variety of sources which, by manual curation, is tough to find the hidden relations.
Let’s take a data curation process in finance, for example. Using ML, a classification model could be designed to identify loan applicants as low, medium, or high credit risks.
A more accurate decision could be made by identifying specific patterns of loan applicants using ML in the data curation process.
Similarity Matching in Data
In most data curation processes, grouping and classification is a necessary design process. Often, researchers would prefer specific data to be grouped based off on a certain similarity.
Algorithms such as Levenshtein distance or Jaccard index could find the matching words in the data useful in the outcome. This might be helpful for data curators that would like to make things a little bit easier.
In Recap
In the past few years, businesses have more or less realized the importance of big data. They know it quite well how processing and harnessing data can enhance their existing business and even open up new business avenues.
In the same way, curating data is equally valuable for the business community. A better data curation will provide valuable insights in making a decision and improving the day-to-day task’s efficiency from researching and analysing the data.
Data curation is organising and integrating data collected from various sources to recap what we have read above. It involves annotation, publication and presentation of the data such that the value of the data is maintained over time.
A fair big data curation process provides a better linkage between data of different types. Moreover, data quality can be evaluated with proper data curation, and better-curated data offers better reusability to researchers and engineers.
The 5 main stages are a data lake, data cleaning, data integration, data discovery, and analytics in a data curation pipeline.
Are you looking for ways to get the best out of your data?
If yes, then let us help you use your data.
FAQ
What is Data Curation?
Data curation is the organization and integration of data collected from various sources. Data curation involves annotation, publication and presentation of the data such that the value of the data is maintained over time, and the data remains available for reuse and preservation
Why is Big Data Curation important?

Big Data curation facilitates collecting and managing the data that all these stakeholders can use in their respective ways. Data curation techniques can help us systematically organise so that the data analysts and scientists can access it in a format most suitable to them
What can Data Curation provide to an organisation?

Provide a better linkage between data of different types. Data quality can be evaluated with proper data curation. Better curated data offers better reusability to researchers and engineers.
What are the stages in a Data Curation pipeline?
The 5 main stages of a data curation pipeline are a data lake, data cleaning, data integration, data discovery, and analytics.
How can Machine Learning help in Data Curation?

Machine learning allows the data curation process to be simplified and automated. It helps maintain high-quality data by supporting proactive and reactive data maintenance, improving data discovery, and keeping data so that it is scalable.