
Extracting structured data from real-world enterprise receipts sounds simple at first, but it quickly turns into a messy problem.
Receipts are all over the place , different formats, layouts, fonts, even languages sometimes. And even when you run Optical Character Recognition(OCR) on them, what you get back is usually noisy, inconsistent, and honestly… not directly usable.
So instead of trying to “fix everything in one step”, I built this project as a pipeline.
The idea was simple: don’t rely on one model to do everything. Break the problem into stages, and let each stage handle one responsibility properly.
This article doesn’t just show the final system , it also documents the process of getting there. What failed, what worked, and what actually made a difference.
How this project is structured
I didn’t treat this like a single script. I broke it into a series of focused writeups, each solving one part of the problem:
– Tool calling didn’t work → 01-tool-calling-failure
– Model comparison → 02-model-evaluation
– Input format experiments → 03-input-format-optimization
– Debugging LLM outputs → 04-debugging-llm-output`
– Final validation logic → 05-validation
Each one builds on the previous one , so it’s more like a system evolution than isolated docs.
Pipeline Overview
Image → OCR (LightOnOCR) → HTML → LLM (Qwen via llama.cpp) → JSON → Cleaning → ValidationWhy this pipeline?
OCR alone isn’t enough.
It can read text, sure , but it doesn’t understand structure. And receipts are not just text; they’re semi-structured data with relationships (items, totals, tax, etc.).
Traditional Optical Character Recognition systems like Tesseract can extract characters, but they don’t capture layout or meaning. That’s where approaches like LayoutLM and modern Natural Language Processing techniques come in helping bridge the gap between raw text and structured information.
The turning point was realizing that the model didn’t need to be perfect ,the system needed to be resilient.
System Execution
Running the LLM Server

This runs a local inference server using llama.cpp. This step initializes a **multimodal model (LightOnOCR)** capable of processing images. The `–mmproj` layer enables mapping visual features into the language model space.
For more details on the runtime used in this project, see:
– llama.cpp documentation: https://github.com/ggerganov/llama.cpp
– Example OCR pipeline explanation: https://youtu.be/5vScHI8F_xo?si=6BkGBcrJJXkTgpMi
Example Workflow
Step 1: Input: Receipt Image
Receipts are highly unstructured inputs. Variations in layout, font, and formatting introduce noise that I normalized before structured extraction.
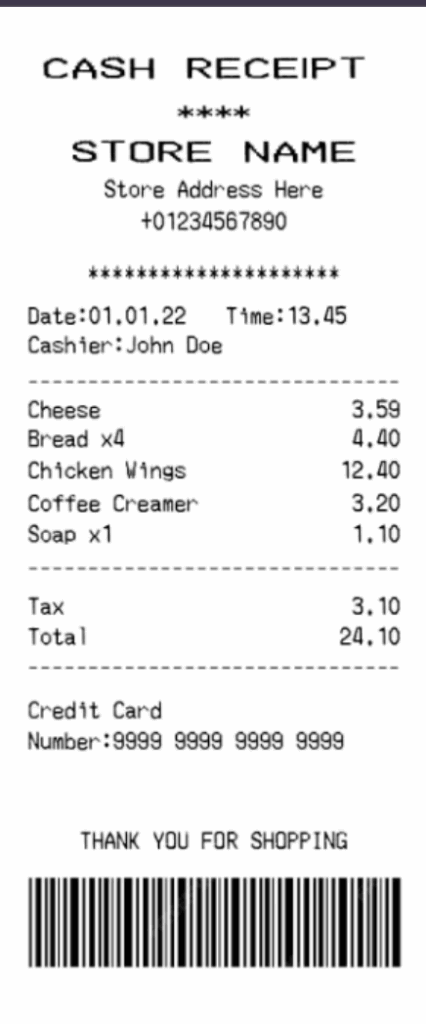
Step 2: Running the LightOnOcr using llama.cpp
LightOnOCR converts visual input into structured HTML, not just plain text. This is important because:
- HTML preserves layout relationships
- Tables and rows are maintained
- Improves downstream extraction by LLM
Step 3: Img -> Json Script:
$prompt = "Extract all text from this receipt as HTML."
for ($i=1; $i -le 100; $i++) {
Write-Host "Processing $i.png..."
$img = "C:\mymodeldir\samples\$i.png"
$b64 = [Convert]::ToBase64String([IO.File]::ReadAllBytes($img))
$body = @{
messages = @(
@{
role = "user"
content = @(
@{ type="text"; text=$prompt },
@{ type="image_url"; image_url=@{ url="data:image/png;base64,$b64" } }
)
}
)
} | ConvertTo-Json -Depth 5
$response = Invoke-RestMethod -Uri "http://127.0.0.1:8080/v1/chat/completions" `
-Method Post `
-Body $body `
-ContentType "application/json"
$output = $response.choices[0].message.content
$output | Out-File "C:\mymodeldir\ocr_outputs\$i.html"
Write-Host "Saved $i.html"
}
This script performs:
- image loading
- base64 encoding
- API communication with the OCR model
I figured out ,Base64 encoding is required because llama.cpp expects image input as either a URL or an encoded string.
Encoding the image in Base64 allows the binary image data to be embedded directly into the request payload, making it easier to send and process without relying on external file hosting.
Step 4: OCR extracts structured HTML:
CASH RECEIPT
STORE NAME Store Address Here +01234567890
Date:01.01.22 Time:13.45 Cashier:John Doe
| Cheese | 3.59 |
| Bread x4 | 4.40 |
| Chicken Wings | 12.40 |
| Coffee Creamer | 3.20 |
| Soap x1 | 1.10 |
| Tax | 3.10 |
| Total | 24.10 |
Credit Card Number:9999 9999 9999 9999
THANK YOU FOR SHOPPING
Barcode: [Barcode Image]
Total: 93.35 Sub Total: 117.2 Tax: 5.86 Order Total: 123.06
I kept the OCR output intentionally as HTML because:
- it preserves structure (tables, rows)
- provides semantic grouping of items
- reduces ambiguity compared to plain text
However, this output was still noisy and requires interpretation.
Step 5: Running the Qwen3.5 using llama.cpp:

This step uses a text-only LLM like Qwen to interpret structured HTML.
Unlike OCR systems, this model does not “see” images , it focused on Natural Language Processing, performing semantic parsing and reasoning over already-structured data.
This separation improved modularity:
- OCR handles perception (extracting and structuring visual data)
- LLM handles understanding (interpreting meaning, relationships, and context)
Step 6 : HTML-> JSON Script:
for ($i=1; $i -le 100; $i++) {
Write-Host "Processing $i.html..."
$htmlPath = "C:\mymodeldir\ocr_outputs\$i.html"
if (!(Test-Path $htmlPath)) { continue }
$html = Get-Content $htmlPath -Raw
# cleaning
$html = $html -replace "RM|SR|\$",""
$html = $html -replace "\*\*",""
$html = $html -replace "`r|`n"," "
$html = $html -replace "\s+"," "
$prompt = @"
Extract structured receipt data.
Return ONLY JSON:
{
"merchant_name": "string",
"merchant_tax_id": "string",
"date": "string",
"invoice_no": "string",
"currency": "string",
"total_amount": "string",
"tax_amount": "string",
"line_items": [
{
"item_desc": "string",
"item_qty": number,
"item_total": "string"
}
]
}
INPUT:
$html
"@
$body = @{
temperature = 0
max_tokens = 700
messages = @(
@{
role = "user"
content = $prompt
}
)
} | ConvertTo-Json -Depth 6
$response = Invoke-RestMethod -Uri "http://127.0.0.1:8081/v1/chat/completions" `
-Method Post `
-Body $body `
-ContentType "application/json"
$output = $response.choices[0].message.content
if (![string]::IsNullOrWhiteSpace($output)) {
$output | Out-File "C:\mymodeldir\json_outputs\$i.json"
}
Write-Host "Saved $i.json"
}
Step 7 : LLM converts HTML → JSON:
{
"merchant_name": "ore Name",
"address": "ore Address Here",
"phone_number": "+01234567890",
"date": "01.01.22",
"time": "13:45",
"invoice_number": "not present in receipt",
"tax_id": "not present in receipt",
"currency": "not present in receipt",
"items": [
{
"name": "Cheese",
"quantity": "1",
"price": "3.59"
},
{
"name": "Bread x4",
"quantity": "4",
"price": "4.40"
},
{
"name": "Chicken Wings",
"quantity": "1",
"price": "12.40"
},
{
"name": "Coffee Creamer",
"quantity": "1",
"price": "3.20"
},
{
"name": "Soap x1",
"quantity": "1",
"price": "1.10"
},
{
"name": "Tax",
"quantity": "1",
"price": "3.10"
},
{
"name": "Total",
"quantity": "1",
"price": "24.10"
}
],
"subtotal": "117.2",
"tax": "5.86",
"total": "24.10",
"payment_method": "Credit Card",
"change": "not present in receipt",
"discounts": "not present in receipt",
"barcode": "[Barcode Image]"
}
This step introduced deterministic correction, which is critical.
What surprised me most was that even when the JSON looked correct, totals were often inconsistent. This wasn’t a formatting issue , it was a semantic issue. The model interpreted quantities differently across similar receipts, which made the output unreliable without further correction.
Step 8: Cleaning layer fixes inconsistencies using Script:
for ($i=1; $i -le 100; $i++) {
$path = "C:\mymodeldir\json_outputs\$i.json"
if (!(Test-Path $path)) { continue }
try {
$json = Get-Content $path -Raw | ConvertFrom-Json
} catch { continue }
$newItems = @()
$newSum = 0
foreach ($item in $json.line_items) {
$clean = $item.item_total -replace "[^0-9\.]", ""
if ($clean -eq "") { continue }
if ($item.item_desc.Length -lt 3) { continue }
$item.item_total = $clean
$newItems += $item
$newSum += [double]$clean
}
$json.line_items = $newItems
$json.total_amount = [math]::Round($newSum, 2)
$json | ConvertTo-Json -Depth 6 | Out-File $path
}
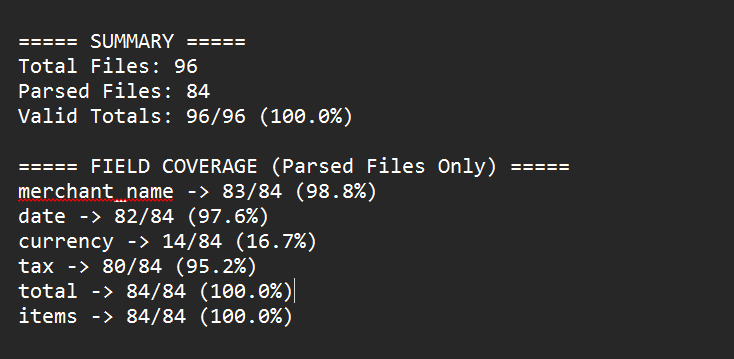
This was the most important step for reliability.
Validation ensured me that :
- sum of items ≈ total amount
- financial consistency is maintained
Formula used: | Σ(items) - total | < toleranceThis compensated for:
- rounding errors
- OCR inconsistencies
Step 9: Validation layer verifies correctness:
Key Insight
The biggest lesson from this project was simple: LLMs are probabilistic.
Initially, I assumed that improving prompts or using a larger model would fix these issues. In practice, neither approach solved the core problem , inconsistency.
Production systems must be deterministic.
Trying to make the model perfect is the wrong approach.
Designing a system that handles imperfect outputs is what actually works.
Conclusion
Building a reliable OCR + LLM pipeline is not about choosing the best model.
It’s about designing the system correctly.
Once each stage has a clear responsibility, the pipeline becomes more stable, easier to debugand usable in real-world scenarios