
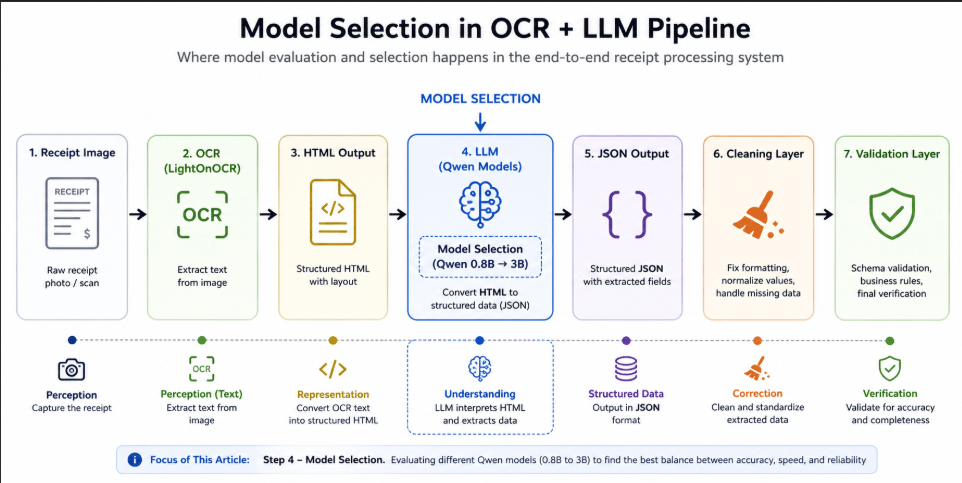
After identifying that tool calling was unreliable in a local LLM setup, the next critical step in the ReceiptFlow pipeline was selecting the right model for structured extraction. Since the system relies on converting noisy OCR output into structured JSON, model performance directly impacts accuracy, consistency, and downstream validation. This article evaluates multiple variants of Qwen (0.8B to 3B) in a local environment using llama.cpp. The goal is to understand how model size affects structured extraction performance and identify the optimal balance between accuracy, speed, and reliability.
Introduction
After identifying that tool calling was unreliable in a local LLM setup (as discussed in the previous article), the next critical step was selecting the right model for structured extraction. Since the pipeline relied on extracting structured JSON from noisy OCR output, model behavior had a direct impact on accuracy, consistency, and downstream validation. This article documents my evaluation of multiple Qwen models (0.8B → 3B) and the trade-offs observed during real-world testing.
System Setup
All experiments were conducted using:
- Runtime: llama.cpp (
llama-server) - Inference Mode: CPU
- Input: OCR-generated HTML from LightOnOCR
- Endpoint:
http://127.0.0.1:8081/v1/chat/completions
Server Command
./llama-server -m qwen-model.gguf --port 8081
Evaluation Criteria
Each model was evaluated on:
- JSON structure consistency
- Field extraction accuracy
- Hallucination frequency
- Latency (CPU inference)
- Stability across different receipts
Models Evaluates
- Qwen 0.8B
- Qwen 1.5B
- Qwen 2B
- Qwen 3B
Observations
Qwen 0.8B — Fast but Unreliable:
This model performed well in terms of speed, but struggled with missing fields (e.g., tax, date), incorrect totals, frequent hallucinations and inconsistent JSON formatting This made it unsuitable for reliable extraction.
Qwen 1.5B — Stable and Predictable:
This was the first model that showed consistent JSON structure , reasonable accuracy in item extraction and lower hallucination rate It handled structured prompts much better than 0.8B.
Qwen 2B — Best Overall Balance
This model provided improved semantic understanding, better handling of complex receipts and acceptable inference time It became the default choice for most experiments.
Qwen 3B — Overprocessing and Token Issues
While this model showed stronger reasoning:
- It often “overthought” simple inputs
- Generated unnecessary explanations
- Hit token limits when input HTML was large
- Slower inference on CPU

Example Output Comparison
Below is a cleaned output after processing:
{
"merchant_name": "ECOSPACE",
"address": "123 reet Name, City Name, ate, Country, 12345",
"phone_number": "+91 1234567890",
"date": "not present in receipt",
"time": "not present in receipt",
"invoice_number": "not present in receipt",
"tax_id": "not present in receipt",
"currency": "INR",
"items": [
{
"quantity": 1,
"item": "Cauliflower Paa",
"price": "80.20"
},
{
"quantity": 1,
"item": "ECOSPACE Canvas Tote Bag",
"price": "150.90"
},
{
"quantity": 1,
"item": "Superfood Po Card",
"price": "10.90"
},
{
"quantity": 1,
"item": "ECOSPACE Soy Chocolate Drink",
"price": "20.75"
},
{
"quantity": 2,
"item": "Vegan Gummies",
"price": "60.95"
},
{
"quantity": 1,
"item": "Organic Popping Corn",
"price": "30.95"
},
{
"quantity": 1,
"item": "ECOSPACE Cashew Butter Spread",
"price": "90.99"
}
],
"subtotal": "490.64",
"tax": "0.00",
"total": "490.64",
"payment_method": "Cash",
"change": "3.6",
"discounts": "not present in receipt"
}
This type of structured output was most consistently produced by 1.5B–2B models.
Key Patterns Identified
- Bigger Models Introduce New Problems
- Higher latency
- Token overflow
- Over-generation
- Smaller Models Lack Structure
- Poor formatting
- Missing fields
- High variability
- Mid-Sized Models Are Optimal
- Balance of structure and speed
- More predictable outputs
External Reference
For a practical overview of OCR + LLM pipelines:
https://www.youtube.com/watch?v=5vScHI8F_xo
Key Insight
Model size alone is not a reliable indicator of structured extraction performance. For this task, input quality and prompt design had a larger impact than model scaling.
Conclusion
The best performance was achieved using Qwen 1.5B–2B models. These models followed structure reliably, produced usable JSON and required minimal correction.
Next Step
Even with the right model, output quality varied significantly depending on how the input was formatted.
Which model performed best overall?
Qwen 2B provided the best balance between accuracy, consistency, and speed.
Why was 0.8B not suitable?
Why didn’t 3B perform the best?
It over-generated, faced token limitations, and was slower on CPU.
What is the key takeaway from model comparison?
Mid-sized models perform better for structured extraction than very small or very large models.
Does increasing model size always improve performance?
No. Larger models can introduce new issues like latency and overprocessing.