
Even after selecting the right model and optimizing input format, inconsistencies in LLM outputs continued to affect the reliability of the ReceiptFlow pipeline. These inconsistencies were not random but followed identifiable patterns such as malformed JSON, missing fields, and incorrect financial values. This article focuses on systematically debugging LLM outputs in an OCR → JSON pipeline built using Qwen models running on llama.cpp. It outlines common failure patterns, debugging strategies, and practical techniques used to make outputs usable for downstream processing.
Introduction
Even after optimizing both model selection and input representation, the outputs generated by the LLM were still not consistently usable in a production pipeline. While the structure of the JSON improved, the content itself remained unreliable in many cases. At this stage, it became clear that improving prompts or switching models would not fully solve the issue. The problem was deeper: LLMs are inherently probabilistic systems, and when applied to noisy real-world data like OCR outputs, they tend to introduce subtle but critical inconsistencies. This article focuses on the practical debugging challenges encountered while working with LLM outputs and how these were systematically addressed using deterministic post-processing techniques.
What you’ll learn
- Common failure patterns in LLM outputs
- Why JSON outputs break in real pipelines
- How to debug probabilistic outputs
- How deterministic cleaning improves reliability
Common Issues
One of the most frequent issues observed was related to JSON formatting. The model often returned outputs that were almost correct but not fully valid. For example, missing brackets, trailing commas, or additional explanatory text would break downstream parsing. In some cases, the output was wrapped inside markdown blocks such as “`json, which required additional cleaning before it could be processed programmatically. Another major issue was currency noise. Receipts often contain values with prefixes such as RM, $, or ₹. While these are meaningful for human interpretation, they interfere with numeric parsing when the goal is to perform calculations or validation. The presence of these symbols caused failures in type conversion and introduced inconsistencies when summing values. A more subtle but impactful issue was item misclassification. The model frequently struggled to distinguish between actual line items and summary rows. For instance, tax values were sometimes treated as individual products, and discount lines were incorrectly classified as purchasable items. Additionally, quantities embedded in text (e.g., “Bread x4”) were not consistently parsed, leading to incorrect total calculations. These issues were not isolated edge cases , they appeared repeatedly across multiple receipts, indicating that they were systemic limitations of the approach rather than one-off errors.
Example Failure
The above example illustrates how even a seemingly structured output can contain multiple hidden issues, including formatting inconsistencies, incorrect classifications, and ambiguous numeric values.
Approach
Instead of attempting to fix these issues by re-running the LLM or further refining prompts, I shifted the approach towards building a deterministic correction layer. Re-running the model was both computationally expensive and unreliable, as it often produced different outputs for the same input. The idea was to accept that the LLM would produce an approximate result and then apply rule-based transformations to correct it. This approach aligns with a broader engineering principle: use probabilistic systems for generation, but rely on deterministic systems for validation and correction.
Cleaning Layer
- The cleaning layer was designed to systematically address the observed issues in LLM outputs. It performed multiple transformations on the raw JSON before it was passed downstream.
- Currency symbols such as RM, $, and ₹ were removed to ensure that all numeric fields could be safely converted into standard numerical types. This step alone significantly reduced parsing errors.
- Next, numeric normalization was applied. Values extracted as strings were cleaned and converted into consistent formats, ensuring that operations such as summation and comparison could be performed reliably.
- The cleaning process also handled structural issues. Markdown wrappers and extraneous text were stripped from the output, and malformed JSON was corrected wherever possible. This included fixing missing brackets and removing invalid characters. By applying these transformations, the output was converted from a loosely structured representation into a deterministic and machine-readable format.
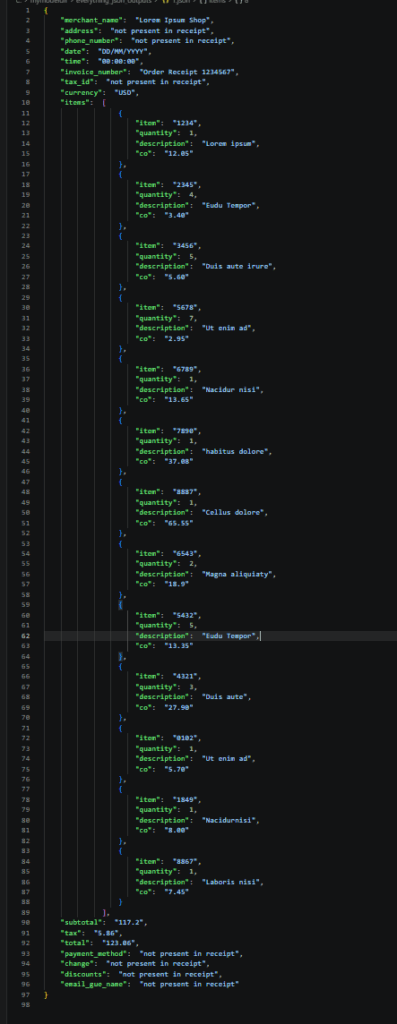
Clean Output
After applying the cleaning layer, the output became significantly more consistent and easier to process programmatically.
Strategy
LLM generates → cleaning layer fixes
This approach proved to be far more effective than repeatedly invoking the model. Instead of relying on the LLM to be perfect, the system was designed to tolerate imperfections and correct them systematically. From an engineering perspective, this separation of concerns is critical. The LLM is responsible for extracting approximate structure and meaning, while the cleaning layer ensures that the output adheres to strict formatting and consistency requirements.
Result
After introducing the cleaning layer, there was a noticeable reduction in parsing errors across the dataset. Outputs became more consistent, and the system was able to handle a wider variety of receipt formats without failing. More importantly, this step enabled reliable downstream validation. Without cleaning, validation would frequently fail due to formatting issues rather than actual logical inconsistencies.
Key Insight
The most important takeaway from this stage is that LLM output is inherently probabilistic, while production systems must be deterministic. Expecting the model to produce perfectly structured and correct output in every case is unrealistic, especially when dealing with noisy real-world data. Instead, a robust system should be designed to handle imperfect outputs and progressively refine them.
Conclusion
Debugging LLM output is not just about improving prompts or selecting better models. It requires building supporting systems that can correct and stabilize the output. By introducing a deterministic cleaning layer, the pipeline became significantly more robust and reliable, bridging the gap between probabilistic generation and production-grade requirements.
Next Step
Even after cleaning, one critical challenge remained: ensuring that the extracted values were numerically correct.
Q&A Section
Q1. Why is debugging LLM output difficult?
Because outputs are non-deterministic and often partially correct.
Q2. What is the first step in debugging?
Separate formatting issues from data correctness.
Q3. How are hallucinations handled?
By validating outputs against input and applying logical checks.
Q4. Can LLM outputs be trusted directly?
No. They must always be validated and cleaned.
Q5. What is the most important layer in this stage?
The validation layer.
References
OpenAI (2023). Function Calling in LLMs
https://platform.openai.com/docs/guides/function-calling
llama.cpp (local inference runtime):
https://github.com/ggerganov/llama.cpp
Qwen models (LLM used in this pipeline):
https://huggingface.co/Qwen
OCR + LLM pipeline explanation:
https://www.youtube.com/watch?v=5vScHI8F_xo
Brown, T. B., et al. (2020). Language Models are Few-Shot Learners, NeurIPS
Kiela, D., et al. (2021). Hallucinations in Neural Models, ACL