

Even after applying model optimization and output cleaning, one critical issue remained in the ReceiptFlow pipeline: numerical correctness. While the LLM could generate structured JSON, the extracted financial values, such as totals, taxes, and item sums, were not always accurate. For a system dealing with financial data, even small inconsistencies can break trust and usability. This article explains how a validation layer was introduced to enforce correctness in the pipeline. Instead of relying on the model to be perfectly accurate, a deterministic validation step ensures that outputs are not only structured but mathematically consistent.
Introduction
After cleaning the LLM outputs, the pipeline appeared stable at a structural level. JSON formatting issues were resolved, unnecessary tokens were removed, and fields were normalized. However, a deeper problem still remained: the numbers didn’t always add up. In many cases, the extracted totals did not match the sum of item values. Taxes were sometimes incorrect or missing, and quantities were inconsistently interpreted. While these issues might seem small individually, they are critical in financial applications where precision is non-negotiable. At this stage, it became clear that relying solely on the LLM, even with cleaning, was not enough. A separate validation layer was required to enforce correctness and ensure that the output could be trusted.
What you’ll learn
- Why LLM outputs are not numerically reliable
- How to validate financial data programmatically
- How to design a deterministic validation layer
- Why validation is critical for production systems
Problem
Even after cleaning, the following inconsistencies were observed:
- Item totals not matching the final total
- Missing or incorrect quantities
- Incorrect or inconsistent tax values These errors were not always obvious at first glance because the structure looked correct. However, when validated mathematically, the inconsistencies became clear. This highlighted a key limitation: LLMs can generate plausible outputs, but not necessarily correct ones.
Approach
To solve this, a validation pipeline was introduced as a final step in the system. The process followed a deterministic sequence:
- Extract item-level totals
- Compute the sum of all items
- Add tax (if present)
- Compare with the extracted final total

This allowed the system to verify whether the generated output was logically consistent.
Tolerance : A small threshold (typically 1–2 units), Used to account for rounding differences
Example Validation Output
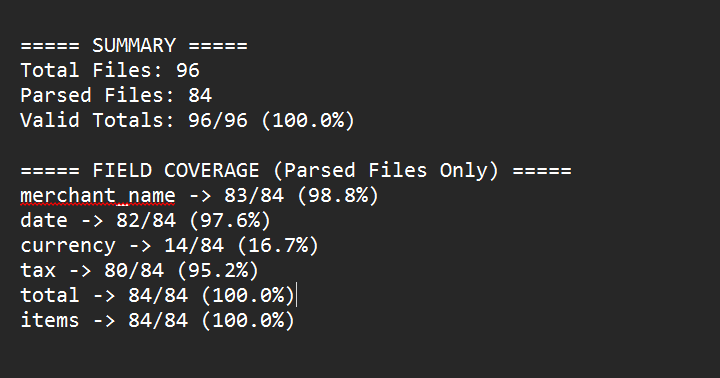
Implementation Details
The validation layer also handled several real-world edge cases to improve robustness:
- Missing quantities → Defaulted to 1 when not specified
- String to numeric conversion → Ensured all values were converted to usable numbers
- Currency normalization → Removed symbols like ₹, $, RM before calculations
- Rounding differences → Allowed small tolerance to avoid false failures These adjustments ensured that validation worked reliably across different receipt formats.
Result
After introducing validation:
Before validation:
- Outputs were structured but not always correct
- Approximate accuracy: Not specified
After validation:
- Outputs became mathematically consistent
- Incorrect totals were detected and corrected This significantly improved the reliability of the pipeline.
Why This Matters
LLMs are not designed for numerical precision. Their strength lies in pattern recognition and language understanding, not exact arithmetic.
Without validation:
Incorrect totals can propagate through the system, Financial data becomes unreliable and Trust in the system breaks
With validation:
Errors are detected early,Outputs become dependable,The system becomes production-ready
Key Insight
Validation is not optional in financial data pipelines : it is mandatory
Final Pipeline
The complete pipeline now looks like:
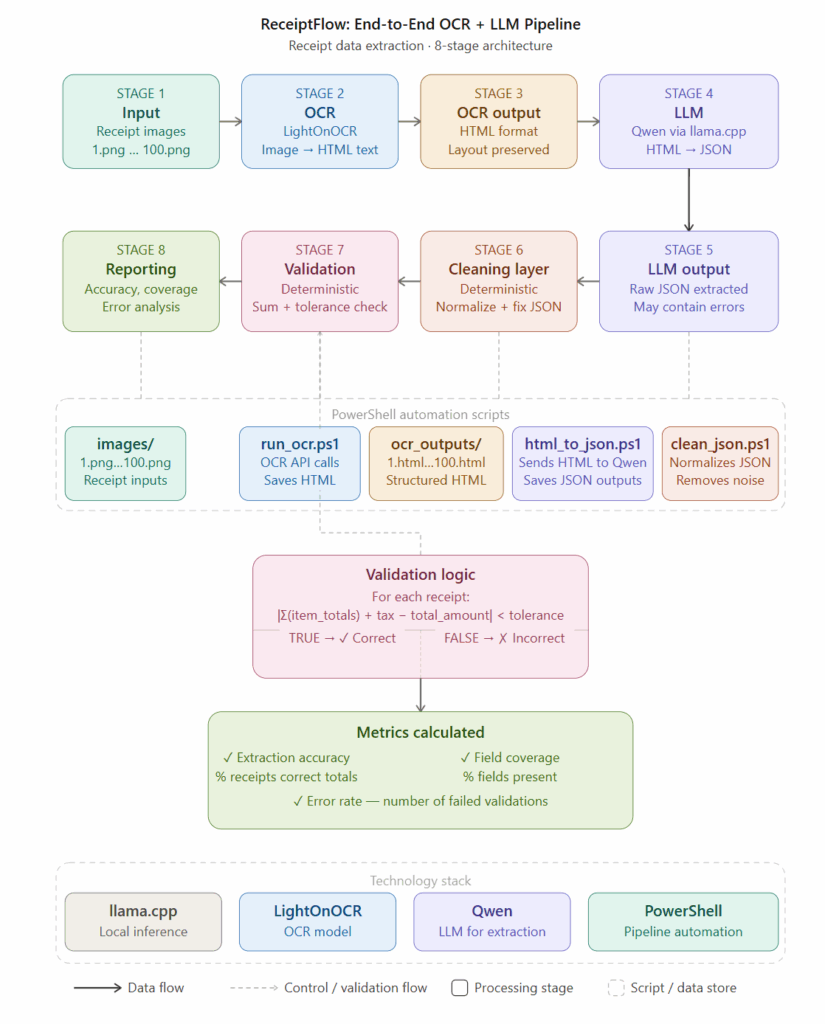
Image → OCR → LLM → Cleaning → Validation
Each stage solves a specific problem: OCR → extracts raw text LLM → structures the data Cleaning → fixes formatting issues Validation → ensures correctness
Conclusion
A reliable system is not defined by generation alone, but by verification. While LLMs enable powerful extraction capabilities, they cannot be trusted to produce perfectly accurate numerical data. The validation layer completes the pipeline by ensuring that outputs are not only structured, but correct. This transforms the system from a prototype into something that can be realistically used in production scenarios.
Q&A Section
Q1. Why is validation necessary if the LLM already extracts data?
Because LLM outputs are not guaranteed to be numerically correct.
Q2. What is the main purpose of the validation layer?
To ensure mathematical consistency between extracted values.
Q3. Can cleaning alone solve these issues?
No. Cleaning fixes format, not correctness.
Q4. What happens if validation fails?
The system detects inconsistency and can trigger correction logic.
Q5. Is validation required for all LLM pipelines?
Not always, but it is essential for financial or critical data systems.
References
Brown, T. B., et al. Language Models are Few-Shot Learners, NeurIPS, 2020 Kiela, D., et al. Hallucinations in Neural Models, ACL, 2021 Smith, R. Tesseract OCR Engine, ICDAR, 2007 llama.cpp Documentation Qwen Model Documentation