
“You don’t need a data center to run useful AI anymore. That changes everything.”
I remember the first time I ran a language model locally on my laptop. It was slow, the output was barely coherent, and I spent more time debugging than actually building anything. That was maybe three years ago.
Fast forward to today, and I ran a Qwen 1.5B model on the same machine — old, no GPU, nothing fancy , and it extracted structured data from receipts faster than I could blink.
Something has genuinely changed. And if you’re a developer, student, or startup builder, you need to pay attention.
Table of Content
- The Old Assumption That’s Falling Apart
- Why Small Models Are Having a Renaissance
- What Makes Qwen Different
- Real Hardware, Real Results
- Why Quantization Was the Real Unlock
- Who’s Actually Building With This
- Local AI Feels Different (And That Matters)
- Where Workflows Beat Benchmarks
- The OCR and Automation Connection
- The Open-Source Ecosystem Fueling All of This
- The Shift Nobody’s Talking About
- This Space Is Still Early — That’s the Point
- Final Thoughts
The Old Assumption That’s Falling Apart {#the-old-assumption}
For years, the unspoken rule in AI was simple: if you want something actually useful, you need cloud infrastructure.
And honestly? That was fair. Early large language models needed:
- Expensive GPUs just to run inference
- Cloud API access with rate limits baked in
- High latency that made real-time workflows painful
- Enormous memory budgets that ruled out consumer hardware
- Ongoing subscription costs that added up fast
For students, indie developers, and small teams, this created a very real wall. You could experiment with AI , but only on someone else’s terms.
You were renting intelligence.
That’s starting to change, and the change is happening faster than most people realize.
Why Small Models Are Having a Renaissance {#small-model-renaissance}
The AI industry spent years in an arms race of scale. Bigger models, more parameters, better benchmarks. And that race produced genuinely incredible things.
But somewhere along the way, a different conversation started happening , mostly in forums, GitHub repos, and Discord servers:
“What’s the smallest model that’s still operationally useful?”
That question sounds boring. It isn’t.
It completely flips the optimization target. Instead of asking how smart a model can get, you’re asking how deployable, fast, and cheap it can be while still doing real work.
And real work, it turns out, doesn’t always require frontier intelligence. A lot of it just requires:
- Stable, predictable outputs
- Decent reasoning over structured inputs
- Low enough latency that the workflow doesn’t feel painful
- Enough flexibility to integrate with other tools
Smaller models are increasingly hitting that bar. And when they do, the infrastructure advantages are enormous.
What Makes Qwen Different {#what-makes-qwen-different}
There are plenty of open-source model families out there. So why are so many developers gravitating toward Qwen specifically?
A few things stand out:
1. The size-to-performance ratio is genuinely surprising. Qwen models at the 0.5B–3B parameter range punch above their weight class for structured tasks. They’re not GPT-4. But for extraction, summarization, and workflow orchestration? Often more than good enough.
2. Quantization-friendly architecture. The models compress well. Running a GGUF-quantized Qwen variant at Q4 or Q5 doesn’t feel like you’re losing half the model. The core reasoning ability stays surprisingly intact.
3. Open accessibility. The weights are available. The community is active. You’re not waiting on an API key or worrying about a provider changing their pricing structure overnight.
4. Breadth of task support. Coding assistance, summarization, semantic grouping, structured JSON generation — these models have been trained broadly enough to be genuinely multi-purpose.
5. Active ecosystem. The Qwen organization on Hugging Face is one of the most active model repositories right now. New variants, fine-tunes, and community experiments appear regularly.
Real Hardware, Real Results {#real-hardware-real-results}
Let me give you some actual numbers from local testing, because this is where it gets interesting.
| Model | Approximate RAM Usage | CPU Performance | Practical Use |
|---|---|---|---|
| Qwen 0.5B (Q4) | ~1.5–2 GB | Very smooth | Simple extraction, classification |
| Qwen 1.5B (Q4) | ~3–4 GB | Smooth | Summarization, structured output |
| Qwen 3B (Q4) | ~6–8 GB | Usable | Reasoning tasks, complex prompts |
| Larger variants | 10+ GB | More demanding | Better quality, needs more RAM |
These aren’t theoretical numbers. They’re what you’ll actually see on a laptop with 16GB of RAM, running llama.cpp on CPU.
The Qwen 0.5B model running on a machine with no GPU at all. Doing real work. That’s the shift.
The important word there isn’t perfect. It’s operationally useful. There’s a massive difference between a model being impressive in a demo and a model being reliable enough to build a workflow around.
Small Qwen models are crossing that line.
Why Quantization Was the Real Unlock {#why-quantization}
You can’t talk about local AI without talking about quantization, because quantization is honestly what made all of this possible.
The short version: quantization compresses a model’s weights from 32-bit or 16-bit floating point numbers down to 4-bit or 5-bit integers. This dramatically shrinks memory requirements with surprisingly modest quality loss for many tasks.
The project that made this practical for regular hardware is llama.cpp : a C++ inference engine optimized specifically for running quantized models on CPUs. It’s one of the most important open-source projects in the local AI ecosystem right now.
The file format that made distribution easy is GGUF : a single-file format that packages quantized weights in a way that’s easy to share, download, and run.
Together, these two things changed the economics completely. A model that would’ve required a $3,000 GPU now runs on a $500 laptop. Not perfectly, but well enough.
Who’s Actually Building With This {#whos-building}
Here’s something I find genuinely exciting about this moment: the people experimenting with local models are increasingly not researchers at big companies.
They’re:
- Students building AI-powered projects without needing cloud credits
- Indie developers prototyping products they can actually ship without ongoing API costs
- Startup teams testing internal automation before committing to infrastructure
- Enterprise developers exploring private, offline deployments where data can’t leave the building
- Automation engineers building document processing pipelines that need to run reliably at scale
Each of these groups has a slightly different reason for caring about local inference. But the common thread is ownership. They want to control the stack.
Cloud APIs are great. But they create dependencies : on pricing, on availability, on rate limits, on a company’s continued goodwill. Local models don’t have those dependencies.
Local AI Feels Different (And That Matters) {#local-ai-feels-different}
This might sound soft, but bear with me: there’s a meaningful psychological difference between using a cloud API and running a model locally.
With a cloud API, you’re a consumer. You send a request, you get a response, and everything in between is a black box. You optimize your prompts and hope for the best.
With a local model, you’re an engineer. You can:
- Swap quantization levels and benchmark the difference
- Modify inference parameters directly
- Test different model variants without worrying about cost
- Build workflows that run offline, permanently
- Integrate with local tools, file systems, and databases without sending data anywhere
That control changes how you build. You start thinking about AI less like a service and more like a tool you actually own.
For developers who want to go deep : who want to understand the systems they’re building with , that difference matters a lot.
Where Workflows Beat Benchmarks {#workflows-vs-benchmarks}
Most public discourse about AI models focuses on benchmarks: MMLU scores, coding competitions, reasoning tests. And those things matter for some applications.
But for operational workflows, a different set of metrics takes over:
- Throughput: How many requests can it handle per minute?
- Latency: How long does each inference take?
- Reliability: Does it consistently produce structured, parseable output?
- Cost per operation: What does it actually cost to run this in production?
- Integration flexibility: Can I plug this into my existing pipeline?
On these metrics, smaller local models often look surprisingly competitive , especially when the alternative is cloud API calls with network latency, rate limits, and per-token costs.
For tasks like:
- Extracting structured fields from documents
- Classifying text into predefined categories
- Summarizing content within a known template
- Generating JSON for downstream processing
- Lightweight orchestration in multi-step pipelines
…you don’t need frontier intelligence. You need something fast, cheap, reliable, and controllable. Small Qwen models increasingly deliver exactly that.
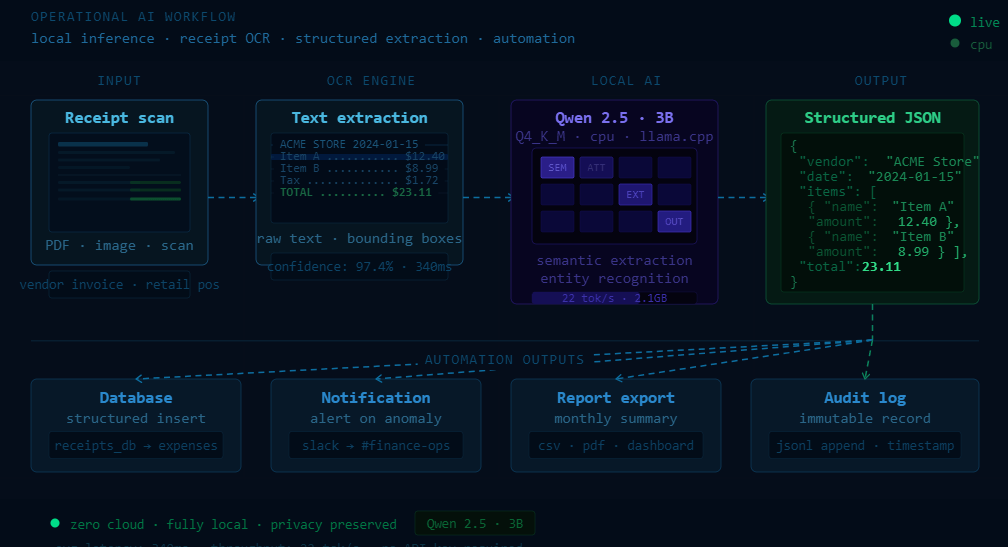
The OCR and Automation Connection {#ocr-and-automation}
One of the places where this becomes most practically useful is in document automation pipelines — particularly when combined with OCR.
The workflow looks something like this:
- OCR layer extracts raw text from scanned documents (receipts, invoices, forms)
- Small LLM layer structures and validates that raw text into clean JSON
- Downstream system consumes the structured data
That middle layer used to require either a cloud API call (latency + cost + privacy concerns) or a heavily engineered rule-based system (brittle + maintenance-heavy).
Small local models are increasingly a third option: fast enough to be practical, smart enough to handle messy real-world inputs, and private enough to process sensitive documents without sending them anywhere.
If you’re interested in going deeper on this, check out these related reads:
- Processing 100 Receipts Locally with OCR and LLMs on CPU
- Why Small Local LLMs Are Becoming Viable for Receipt Automation
- Building Validation Layers for Reliable AI Receipt Extraction
- OCR vs LLM Receipt Extraction: What Actually Works
The Open-Source Ecosystem Fueling All of This {#open-source-ecosystem}
None of this happens without the open-source ecosystem that surrounds it.
Hugging Face has become the de facto distribution layer for local AI models. It’s where quantized variants get uploaded, where community benchmarks get shared, and where new optimizations spread from researcher to developer almost instantly.
llama.cpp provides the inference engine. GGUF provides the format. And a constantly growing community of contributors provides the optimizations, fine-tunes, and workflow integrations that make all of it more accessible.
This ecosystem accelerates everything. A new Qwen variant drops, and within days there are community-tested GGUF quantizations, benchmark comparisons, and workflow integration guides available.
That collaborative velocity is one of the biggest reasons local AI is moving faster than most people expect.
The Shift Nobody’s Talking About Enough {#the-shift}
Here’s the bigger picture underneath all of this:
AI is slowly but unmistakably shifting from being a product to being infrastructure.
When AI is a product, you use it through an interface. A chatbot, a tool, a SaaS application.
When AI is infrastructure, you build with it. You integrate it into pipelines. You deploy it as a component. You optimize it for your specific use case.
That second mode of AI , infrastructure AI ,has very different requirements than conversational AI. It needs to be:
- Deployable in diverse environments
- Reliable enough for automation
- Cheap enough to run at scale
- Controllable enough for compliance and audit
Small local models are, in many ways, better suited to this role than large cloud models. Not because they’re smarter, but because they fit the operational constraints better.
The developers building with local models today are, in a real sense, building the AI infrastructure of the next few years.
This Space Is Still Early ,That’s the Point {#still-early}
One of the most honest things I can say about the local AI ecosystem right now is that it still feels unfinished. And that’s actually a good thing.
There are rough edges everywhere:
- Tooling is evolving rapidly
- Best practices for prompt engineering in local contexts are still emerging
- Quantization strategies keep improving
- New model architectures keep changing what’s possible
But that roughness creates opportunity. In a space that’s still being figured out, a determined developer with a laptop and a few weekends can make genuine contributions.
Especially in areas like:
- Benchmarking real-world workflow performance
- Developing robust prompt templates for structured extraction
- Building open-source tooling for local AI pipelines
- Testing model performance on domain-specific tasks
The frontier isn’t only at the big labs anymore. Some of the most interesting work in AI right now is happening on ordinary hardware, by ordinary developers, building things that actually work.
Final Thoughts {#final-thoughts}
Small Qwen models aren’t going to replace GPT-4 or Claude or Gemini for complex reasoning tasks. That’s not what they’re for.
What they’re doing is something arguably more important for a lot of developers: lowering the floor.
They’re making it possible to build AI-powered systems without cloud dependencies, without ongoing costs, without rate limits, and without sending your data to someone else’s servers.
For students who can’t afford API credits, that’s everything. For startups that need to prototype fast, that’s a lifeline. For enterprise teams working with sensitive documents, that’s a compliance requirement.
The trajectory is clear: AI is moving toward the edge, toward local deployment, toward operational infrastructure. Small Qwen models are one of the clearest signals of that shift , and they’re worth paying attention to.
References & Resources
| Resource | What It Is |
|---|---|
| llama.cpp GitHub | The primary local inference engine for quantized models |
| Hugging Face | Model distribution hub; find Qwen models here |
| Qwen on Hugging Face | Official Qwen model repository |
| GGUF Format Docs | Technical documentation for the GGUF quantization format |
Related Reading
- Why Small Qwen Models Are Becoming the Most Interesting Local AI Systems
- OCR vs LLM Receipt Extraction: What Actually Works
- Testing OCR and AI Models for Structured Receipt Extraction
- Building Validation Layers for Reliable AI Receipt Extraction
- Processing 100 Receipts with OCR and LLMs on CPU
Was this useful? If you’re building something with local AI models, I’d love to hear about it. The ecosystem grows fastest when people share what they’re learning.