
Most receipt digitization systems today rely heavily on cloud APIs.
You upload a receipt, the document gets processed somewhere remotely, and structured data comes back through an API response. That works well for many use cases, but it also raises several practical questions around privacy, infrastructure ownership, recurring costs, and offline deployment.
At the same time, smaller local language models have improved rapidly over the past year. Models that previously felt too limited for structured extraction tasks are suddenly becoming operationally useful when combined with OCR, validation layers, and better prompting strategies.
This led to a simple question:
Can a completely local OCR + LLM pipeline process real-world receipts reliably on CPU hardware?
To explore that, we built and tested a local receipt extraction pipeline using OCR, llama.cpp, Qwen models, and deterministic validation layers across approximately 100 real receipts.
The goal was not perfect AI reasoning.
The goal was operationally useful structured extraction without relying on cloud infrastructure.
Introduction
Receipt extraction sounds deceptively simple until you actually try it on real receipts.
At first glance, the workflow feels straightforward:
- scan receipt
- extract text
- convert to JSON
- done
But real-world receipts are messy.
Thermal paper fades.
Layouts differ between vendors.
Taxes appear inconsistently.
Discounts break line structures.
OCR outputs become noisy.
Totals drift.
JSON formatting breaks.
And once you move beyond a few example receipts into larger datasets, the entire problem changes.
What initially looks like an OCR problem slowly becomes:
- a semantic grouping problem
- a formatting problem
- a validation problem
- and eventually a workflow reliability problem
That was exactly what we encountered while experimenting with local OCR + LLM pipelines.
Why We Wanted to Test This Locally
Most modern receipt scanning systems operate as SaaS platforms.
You upload a document to:
- cloud OCR APIs
- document AI services
- enterprise extraction platforms
and receive structured output back.
That model works extremely well for many businesses.
But there are also clear limitations:
- recurring API costs
- infrastructure dependency
- privacy concerns
- compliance restrictions
- offline deployment limitations
At the same time, local inference tooling improved dramatically.
Projects like:
- llama.cpp
- GGUF quantization
- Qwen models
- lightweight OCR systems
made it increasingly realistic to experiment with local AI document workflows entirely on CPU hardware.
The interesting question was no longer:
Can local AI run?
The interesting question became:
Can local AI become operationally useful?
The Pipeline Architecture
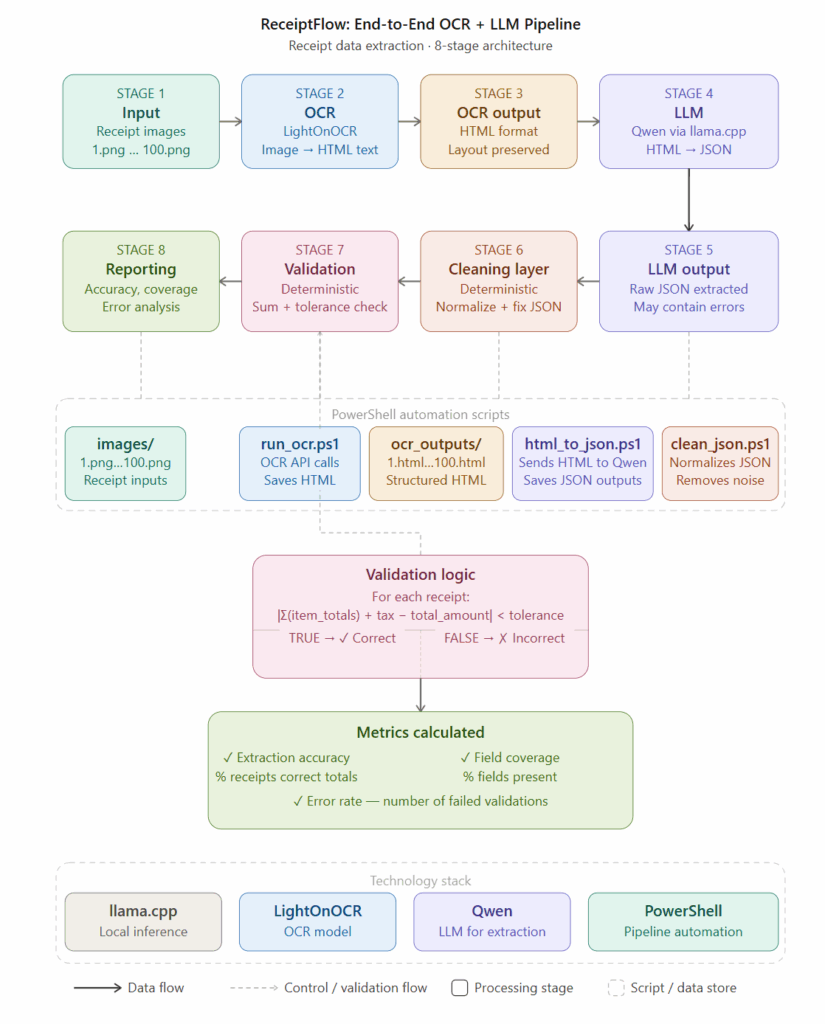
The pipeline we tested combined:
- OCR
- local LLM inference
- structured prompting
- deterministic validation
into a fully local workflow.
The architecture looked like this:
Receipt Image → OCR → OCR HTML/Text Output → Qwen via llama.cpp → Raw JSON Extraction → Cleaning Layer → Validation Layer → Final Structured JSON
Instead of relying purely on OCR, the workflow attempted to combine:
- visual text extraction
- semantic grouping
- structure reconstruction
- financial validation
The goal was not only extracting text.
The goal was reconstructing meaningful financial structure.
OCR Was More Difficult Than Expected
One of the biggest surprises during testing was how inconsistent OCR outputs became across real-world receipts.
Clean demo receipts work well.
Real receipts do not.
Some receipts contained:
- faded thermal text
- broken alignment
- inconsistent spacing
- multilingual characters
- compressed totals
- overlapping discounts
- skewed images
We initially experimented with traditional OCR systems such as :contentReference[oaicite:0]{index=0}.
While Tesseract extracted visible text reasonably well, the outputs often became structurally chaotic.
For example:
- line items merged together
- discounts broke formatting
- totals drifted into incorrect sections
- semantic grouping disappeared entirely
In many cases, the OCR output looked visually readable for humans while becoming surprisingly difficult for structured extraction systems.
This turned out to be one of the most important lessons from the entire experiment.
OCR accuracy alone is not enough.
Structure matters far more than most people initially assume.

Figure: Example of noisy OCR extraction from a real receipt using Tesseract
Why Structure Became More Important Than Raw OCR Accuracy
Initially, we focused heavily on OCR quality itself.
But over time, the more important issue became formatting consistency.
Even when OCR outputs contained small character mistakes, the extraction pipeline performed reasonably well if:
- line grouping remained intact
- semantic sections stayed separated
- totals remained structurally identifiable
Meanwhile, perfectly readable OCR outputs sometimes failed completely when formatting drifted.
This was a surprisingly important realization.
The pipeline cared less about perfect text extraction and more about preserving semantic relationships.
That changed how we approached preprocessing entirely.
Running Qwen Models Locally with llama.cpp
For local inference, we used:
- :contentReference[oaicite:1]{index=1}
- GGUF quantized models
- CPU-only execution
We experimented with several Qwen variants:
- Qwen 0.8B
- Qwen 1.5B
- Qwen 2B
- Qwen 3B
The goal was to understand:
- structure quality
- hallucination behavior
- inference speed
- CPU performance
- JSON consistency
At first, larger models appeared more promising.
But after testing across many receipts, the results became more nuanced.
Bigger models did not always produce better operational outputs.
In several cases:
- larger models hallucinated additional fields
- structure drift increased
- formatting instability appeared
- latency became difficult operationally
Smaller models were often more predictable when paired with deterministic validation.
That was one of the most interesting outcomes from the entire experiment.
Approximate Runtime Benchmarks
The system was tested on local CPU hardware across approximately 100 receipts.
Average runtime varied significantly depending on:
- OCR complexity
- model size
- receipt length
- prompt structure
Approximate runtime observations:
| Pipeline | Average Runtime |
|---|---|
| Tesseract OCR Only | ~2–3 sec |
| OCR + Qwen 0.8B | ~4–6 sec |
| OCR + Qwen 1.5B | ~6–8 sec |
| OCR + Qwen 2B | ~8–12 sec |
| OCR + Qwen 3B | ~12–18 sec |
These numbers are not meant as scientific benchmarks.
The goal was practical operational testing.
The interesting observation was that even relatively small local models were already usable for meaningful extraction workflows.
The Biggest Problem: JSON Reliability
One of the hardest parts of the experiment was not OCR itself.
It was reliable structured output generation.
The models frequently produced:
- malformed JSON
- missing brackets
- duplicated fields
- incorrect nesting
- hallucinated totals
- broken arrays
This became especially problematic across longer receipts with:
- discounts
- tax sections
- multiple totals
- mixed currencies
- promotional formatting
Initially, we assumed prompting alone would solve this.
It did not.
The more receipts we tested, the clearer it became that prompting alone was not enough for operational reliability.
Why Validation Layers Became Critical
This eventually led to one of the most important parts of the system:
deterministic validation layers.
Instead of trusting the LLM completely, the workflow began validating:
- total calculations
- line-item sums
- discount consistency
- JSON structure
- missing fields
For example:
sum(items) - discounts ≈ receipt total
If values drifted significantly, the output could be flagged or corrected.
This dramatically improved operational consistency.
Ironically, the more we experimented, the more obvious it became that reliable AI workflows often depend heavily on non-AI validation systems.
That insight changed how we thought about AI automation entirely.
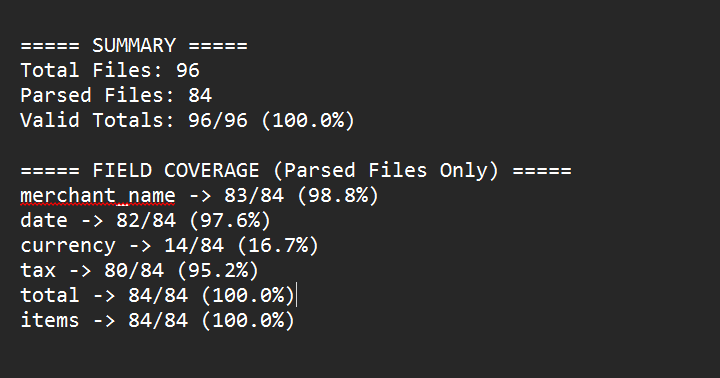
What Failed During Testing
One important lesson from the experiment was that failures were often more valuable than successful examples.
Several recurring problems appeared repeatedly:
- OCR formatting inconsistencies
- semantic grouping drift
- hallucinated products
- duplicated totals
- malformed JSON
- missing discounts
- unstable array formatting
- structure collapse on long receipts
Interestingly, many failures were not caused by the language model itself.
They were caused earlier in the pipeline:
- OCR structure
- formatting quality
- prompt context
- semantic ambiguity
This reinforced something very important:
Document extraction is not only a model problem.
It is a systems engineering problem.
The Most Interesting Insight
The biggest takeaway from processing 100 receipts locally was surprisingly simple:
Small local models are becoming operationally useful much faster than expected.
Not because they suddenly became perfect reasoners.
But because:
- OCR improved
- quantization improved
- local inference tooling improved
- validation layers improved
- structured workflows improved
The combination matters more than raw model intelligence alone.
This changes how local AI systems should be evaluated.
Instead of asking:
Is the model perfect?
the better question becomes:
Can the system produce operationally useful workflows?
And increasingly, the answer is yes.
Why This Matters Beyond Receipt Scanning
Receipt extraction may seem like a relatively small niche problem.
But structurally, it represents something much larger.
Many enterprise workflows depend on:
- semi-structured documents
- financial records
- operational paperwork
- reconciliation systems
- workflow validation
The same architectural ideas apply broadly across:
- procurement
- logistics
- finance
- accounting
- healthcare
- insurance
Receipt extraction simply became a practical environment for testing local AI operational workflows.
The Bigger Shift Happening
The interesting part is that local AI systems are no longer only experimental toys.
They are increasingly becoming operational infrastructure.
This does not mean cloud AI disappears.
But it does mean smaller local systems are becoming capable of:
- meaningful automation
- structured extraction
- workflow participation
- operational augmentation
And that changes how businesses may eventually think about document automation entirely.
Conclusion
Processing 100 real-world receipts locally revealed something more interesting than simple OCR performance metrics.
The experiment demonstrated that operationally useful document extraction no longer requires massive cloud infrastructure.
By combining:
- OCR
- local LLMs
- validation systems
- structured workflows
small CPU-based pipelines can already automate meaningful parts of financial document processing.
The models are still imperfect.
The workflows still fail sometimes.
Validation remains critical.
But the direction is becoming increasingly clear.
Local AI document systems are evolving from experiments into practical operational tools.
And receipt extraction turned out to be one of the most interesting environments to observe that transition happening in real time.
Suggested Internal Links
- Traditional OCR vs LLM-Based Receipt Extraction
- Why AI Receipt Digitization Is Moving Beyond Traditional OCR
- Receipt Scanning Is No Longer Just an OCR Problem
- Building Validation Layers for Reliable AI Receipt Extraction
- Why Small Local LLMs Are Becoming Viable for Receipt Automation