
Most teams evaluating uncensored models spend a lot of time on model selection. They compare benchmarks. […]
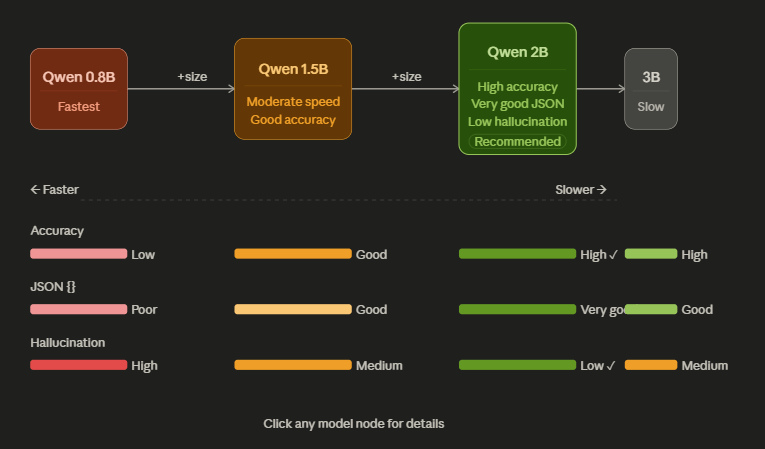
“The question isn’t whether small models are perfect. It’s whether they’re useful enough to build with.” […]
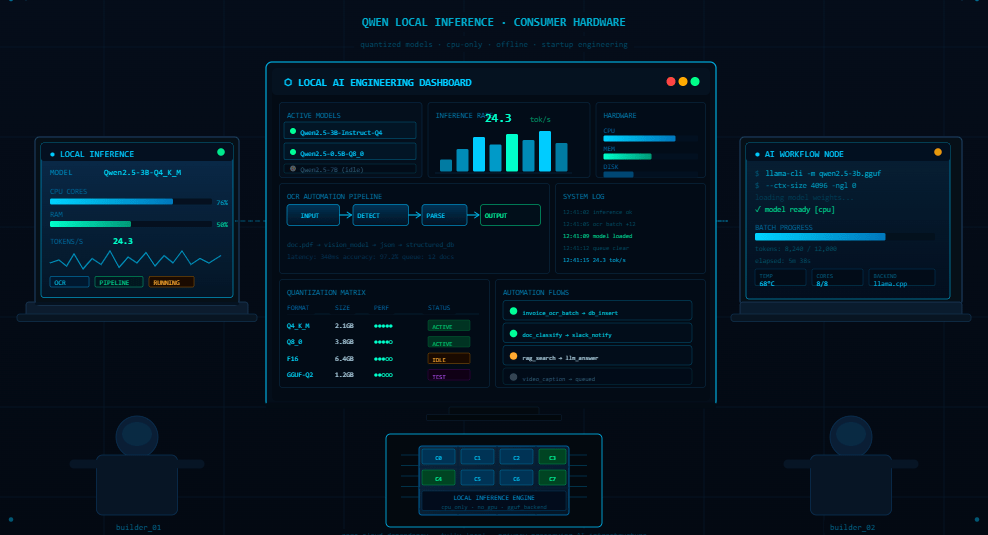
“You don’t need a data center to run useful AI anymore. That changes everything.” I remember […]
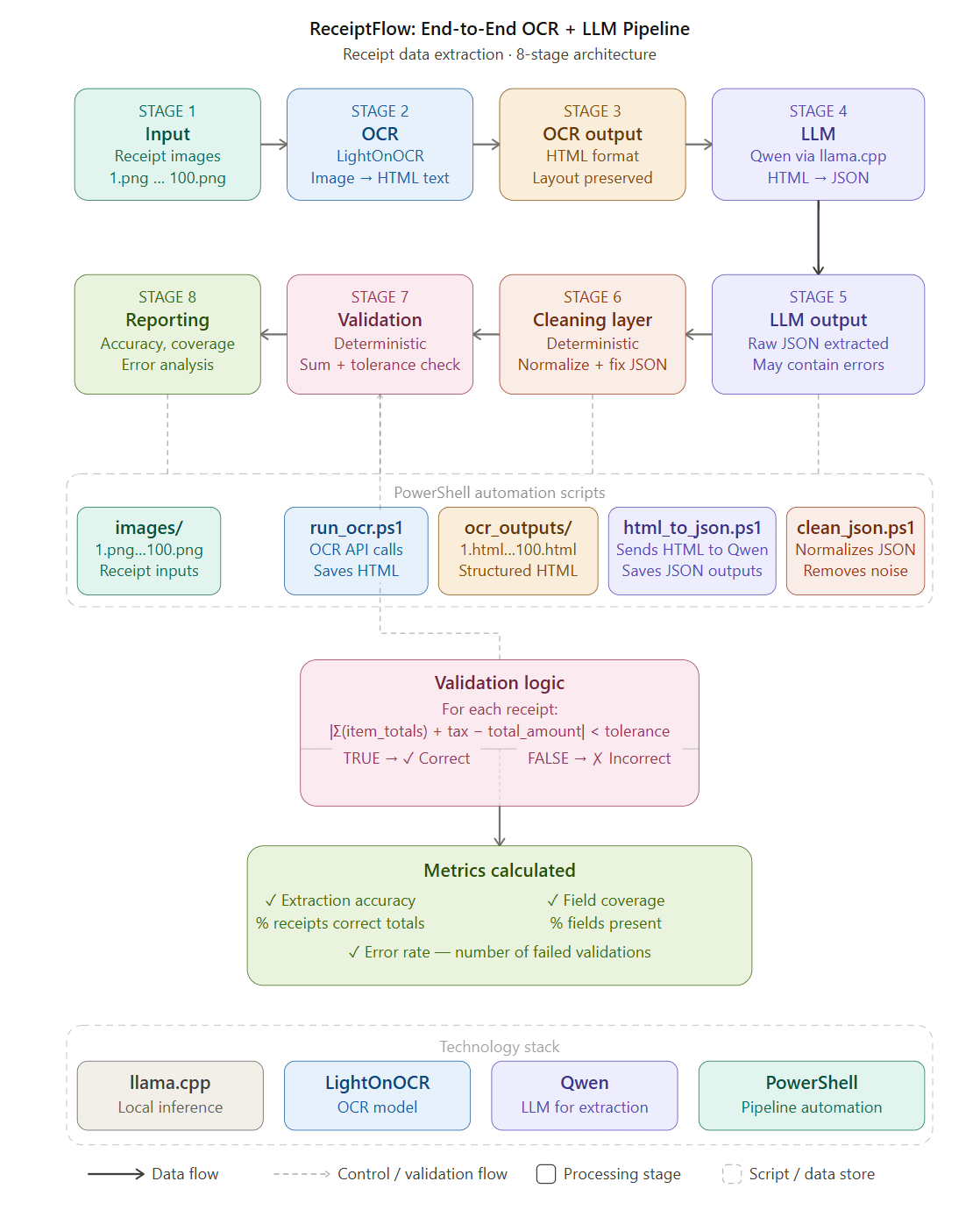
Extracting structured data from real-world enterprise receipts sounds simple at first, but it quickly turns into […]

Even after applying model optimization and output cleaning, one critical issue remained in the ReceiptFlow pipeline: […]
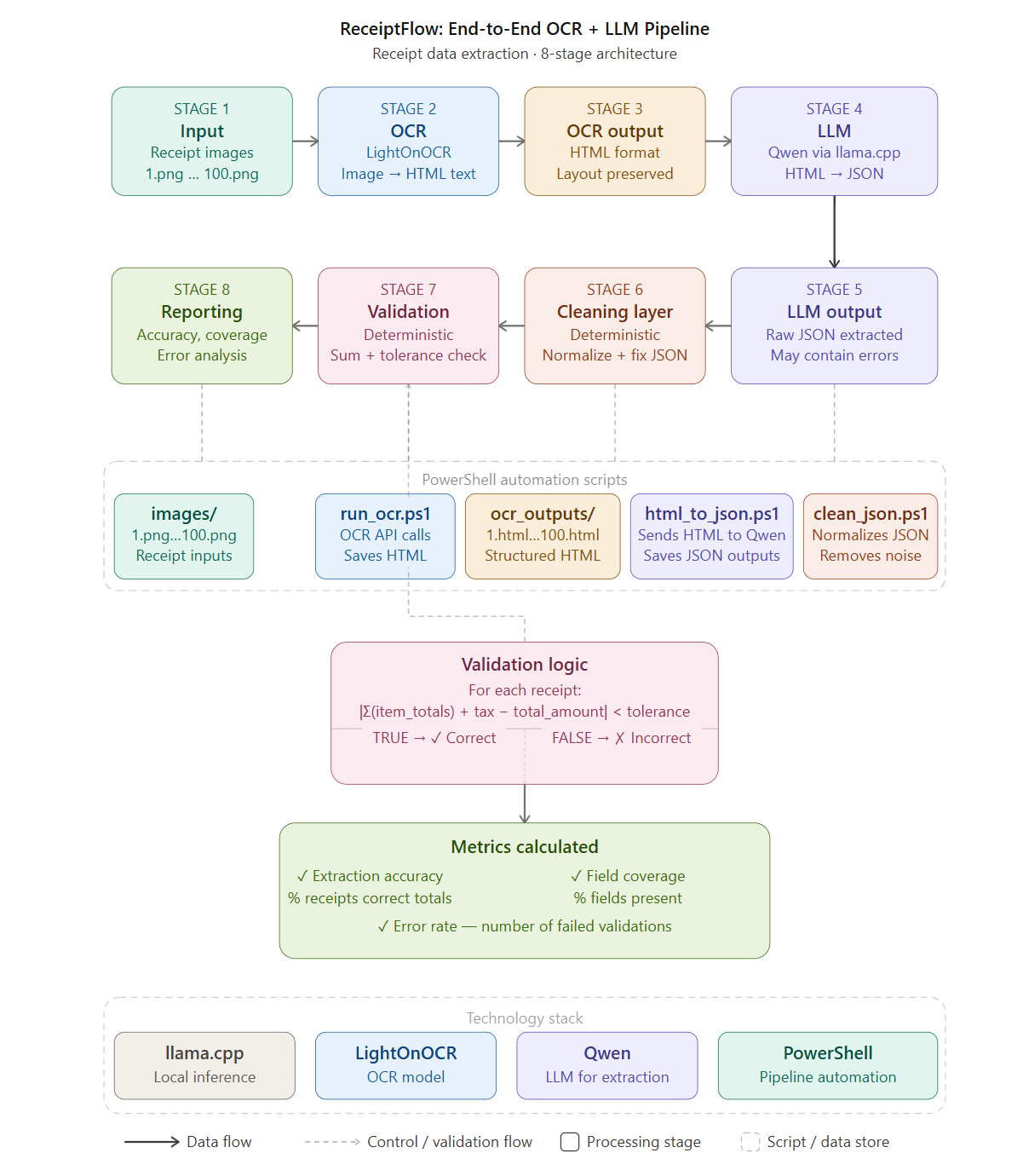
Even after selecting the right model and optimizing input format, inconsistencies in LLM outputs continued to […]

After selecting an appropriate model for structured extraction, inconsistencies in output still persisted within the ReceiptFlow […]
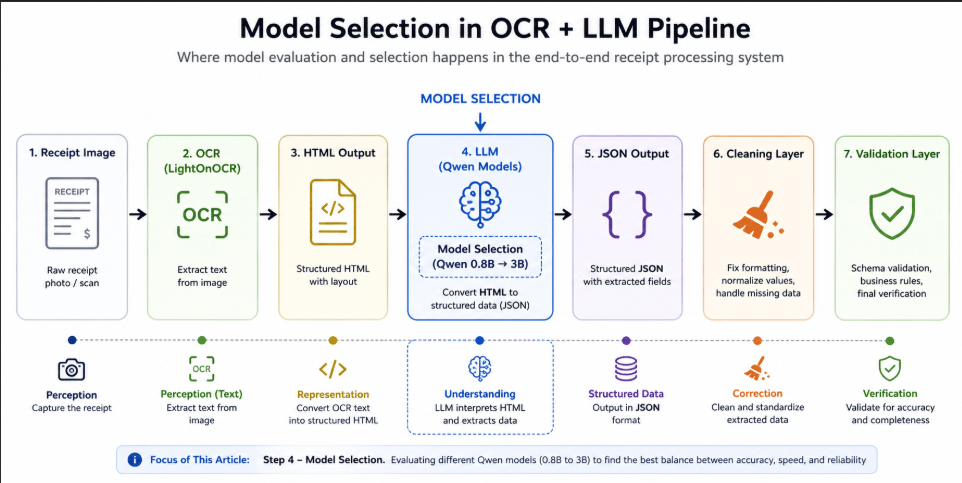
After identifying that tool calling was unreliable in a local LLM setup, the next critical step […]
When building ReceiptFlow, the goal was simple: take messy OCR output from receipts and convert it […]