
For a long time, small language models were mostly dismissed for real operational workflows.
They were considered:
- too weak
- too unstable
- too inconsistent
- too limited for structured automation
Especially for document extraction tasks, the common assumption was that only large cloud models could reliably process messy real-world data.
And honestly, for a while, that assumption was mostly true.
But over the past year, something interesting started changing.
Smaller local models suddenly became much more usable than many people expected — not because they magically turned into perfect reasoning systems, but because the surrounding ecosystem improved dramatically.
OCR systems improved.
Quantization improved.
Inference tooling improved.
Validation layers improved.
Structured workflows improved.
And once these systems started working together, smaller local models became capable of surprisingly useful operational workflows.
This article explores why small local language models are becoming increasingly viable for receipt extraction and document automation, what changed technically, and why architecture often matters more than raw model size.
Introduction
There is a common assumption in AI that bigger models automatically produce better workflows.
In theory, that sounds logical.
Larger models usually:
- know more
- reason better
- generalize better
- produce stronger outputs
But operational workflows behave differently than demos.
Real systems care about:
- latency
- consistency
- cost
- predictability
- infrastructure requirements
- failure handling
And once we started testing local OCR + LLM pipelines on real receipts, something became surprisingly obvious:
The most useful system was not always the biggest model.
In several cases, smaller local models produced more stable operational workflows than larger ones.
That does not mean smaller models suddenly became “smarter.”
It means the workflow architecture around them improved significantly.
Why Small Models Historically Struggled
For a long time, small models failed badly at structured extraction tasks.
They struggled with:
- semantic grouping
- JSON formatting
- long contexts
- instruction following
- reasoning consistency
- hallucination control
Receipt extraction exposed these weaknesses immediately.
Real receipts contain:
- inconsistent layouts
- discounts
- taxes
- noisy OCR
- broken spacing
- multilingual text
- multiple totals
- promotional formatting
Smaller models frequently:
- hallucinated missing fields
- broke JSON structure
- confused totals
- lost line-item grouping
- generated unstable outputs
Because of this, most production-grade extraction systems relied heavily on:
- large cloud models
- external APIs
- enterprise OCR platforms
The assumption became:
small local models are not operationally useful
That assumption is now starting to change.
What Actually Changed
One of the most interesting realizations during experimentation was that the models themselves were only part of the story.
The surrounding infrastructure improved dramatically over the past year.
Several things evolved simultaneously:
- OCR quality improved
- GGUF quantization improved
- llama.cpp matured rapidly
- prompt engineering improved
- validation workflows became more sophisticated
- semantic preprocessing improved
- structured extraction pipelines became more reliable
This changed the operational equation completely.
Suddenly, smaller models no longer needed to solve the entire problem alone.
The workflow itself became intelligent.
And that distinction matters a lot.
The Pipeline Became More Important Than the Model
This was probably the biggest insight from testing local receipt extraction workflows.
Initially, most attention went toward model size:
- 7B
- 14B
- 32B
- larger reasoning models
But after processing real receipts repeatedly, the more important factors became:
- OCR formatting quality
- semantic grouping
- preprocessing consistency
- validation layers
- deterministic correction
- structured prompting
In many cases, a smaller stable workflow outperformed a larger unstable one.
That was a surprisingly important realization.
The system architecture increasingly mattered more than raw parameter count.

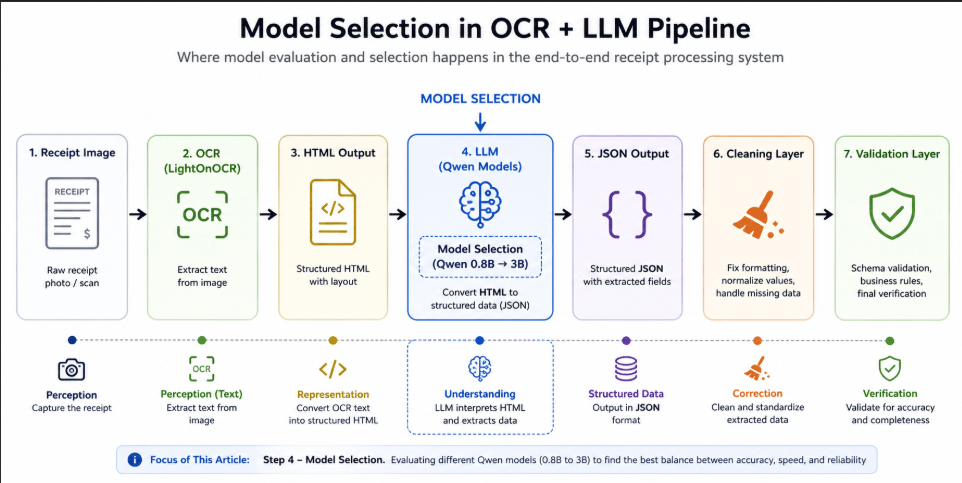
Figure: Local receipt extraction workflow using OCR, small LLMs, and validation layers
Testing Small Qwen Models Locally
For experimentation, we tested multiple Qwen variants locally using:
- :contentReference[oaicite:0]{index=0}
- GGUF quantized models
- CPU-only inference
The primary models tested included:
- Qwen 0.8B
- Qwen 1.5B
- Qwen 2B
- Qwen 3B
The goal was not benchmarking academic reasoning quality.
The goal was operational usefulness for:
- receipt extraction
- structured JSON generation
- semantic grouping
- financial validation workflows
Initially, larger models appeared significantly stronger.
But once latency, structure stability, and operational consistency were considered together, the results became much more nuanced.
Bigger Models Were Not Always Better
One of the more unexpected findings was that larger models often introduced different operational problems.
Some larger models:
- hallucinated additional fields
- overgenerated outputs
- produced unstable JSON
- drifted semantically across longer receipts
- increased inference latency significantly
Meanwhile, smaller models often behaved more predictably when paired with deterministic workflows.
This was especially noticeable once validation layers were introduced.
A smaller model producing:
mostly correct + stable structure
was often more operationally useful than:
more intelligent but unstable outputs
That difference becomes extremely important in production workflows.
OCR Structure Turned Out to Matter More Than Expected
Another major realization was that OCR formatting quality often mattered more than model intelligence itself.
Initially, we focused heavily on:
- model size
- prompting
- inference quality
But repeated experiments showed that the extraction pipeline performed much better when OCR outputs preserved:
- line grouping
- semantic sections
- totals alignment
- item structure
Even imperfect OCR text worked surprisingly well if semantic formatting remained stable.
Meanwhile, visually readable OCR outputs sometimes failed completely when formatting collapsed.
This changed how we approached preprocessing entirely.The workflow started caring less about perfect text extraction and more about preserving structure.
Why Validation Layers Changed Everything
The single most important improvement in the workflow was not model quality.
It was deterministic validation.
Instead of trusting the model completely, the pipeline began validating:
- totals
- discounts
- line-item sums
- JSON structure
- field consistency
For example:
sum(items) - discounts ≈ receipt total
If values drifted significantly, outputs could be:
- corrected
- flagged
- reprocessed
This dramatically improved reliability.
Ironically, the smaller models became usable precisely when they stopped working alone.
That became one of the biggest insights from the entire experiment.
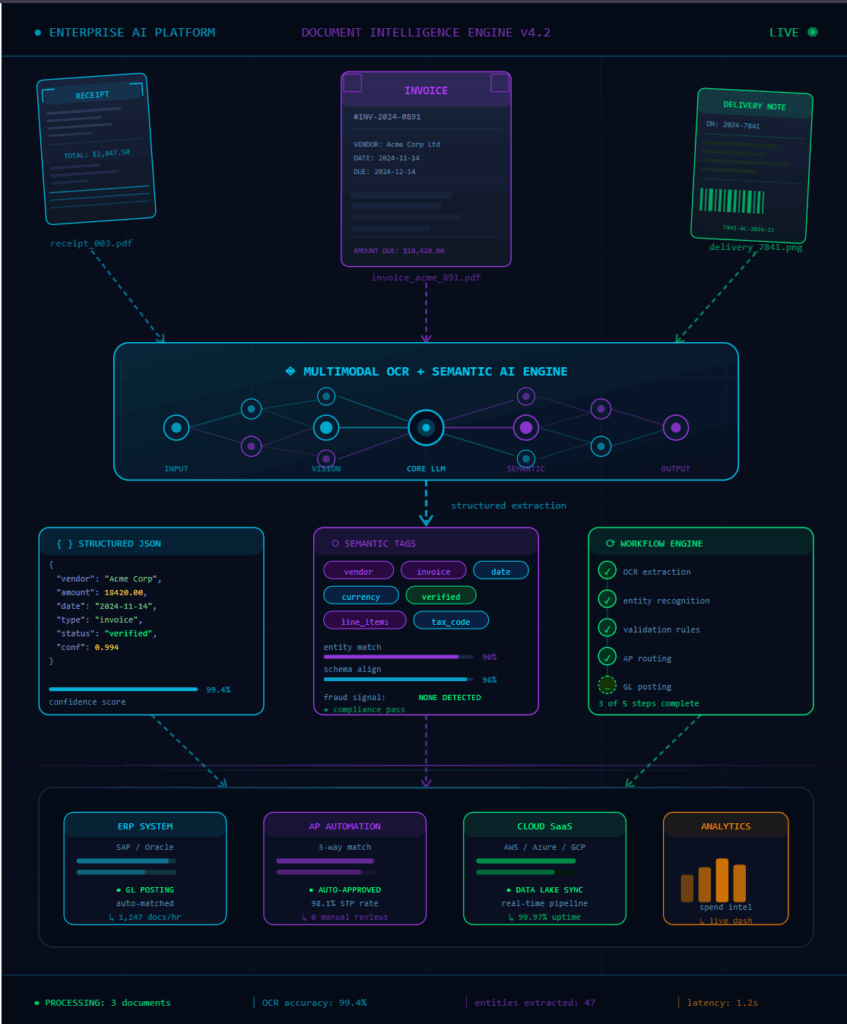
Figure: Deterministic validation layer stabilizing small-model extraction workflows
Operational Usefulness Is More Important Than Perfect Reasoning
One mistake people often make when evaluating AI systems is comparing them only by intelligence benchmarks.
Operational workflows care about different things.
Businesses do not necessarily need:
- perfect reasoning
- philosophical intelligence
- complex chain-of-thought capabilities
Most workflows simply need:
- stable outputs
- predictable structure
- low latency
- affordable deployment
- operational consistency
This changes how smaller models should be evaluated.
The question is no longer:
Can the model reason perfectly?
The more important question becomes:
Can the workflow produce operationally useful outputs reliably?
And increasingly, smaller local systems can.
Why This Matters Financially
The economics of local AI are becoming increasingly interesting.
Cloud APIs work extremely well, but they also introduce:
- recurring costs
- infrastructure dependency
- privacy concerns
- compliance challenges
- scaling expenses
Smaller local models create a different operational model entirely.
Businesses can increasingly experiment with:
- offline inference
- local automation
- infrastructure ownership
- private AI workflows
- CPU-based deployments
This becomes especially interesting for:
- procurement systems
- finance operations
- healthcare workflows
- logistics automation
- enterprise document processing
The important shift is not that local AI replaces cloud AI completely.
The important shift is that smaller local systems are becoming operationally viable much faster than many people expected.
Why Receipt Extraction Became Such a Useful Test Environment
Receipt extraction turned out to be one of the most interesting environments for testing local AI systems.
Why?
Because receipts combine several difficult problems simultaneously:
- noisy OCR
- semi-structured layouts
- financial calculations
- semantic grouping
- JSON generation
- operational validation
A workflow capable of handling messy real-world receipts reasonably well often becomes surprisingly transferable to:
- invoices
- procurement records
- logistics paperwork
- financial workflows
- operational document systems
Receipt extraction became less interesting as an OCR demo and more interesting as a systems engineering experiment.
The Bigger Industry Shift
The most interesting part of this transition is that local AI systems are slowly moving from:
experimental demos
toward:
operational infrastructure
This does not mean local models suddenly became perfect.
It means workflows evolved.
The combination of:
- OCR
- structured prompting
- validation systems
- deterministic logic
- semantic preprocessing
- local inference tooling
created something operationally useful.
And once workflows become operationally useful, adoption changes very quickly.
Conclusion
Small local language models are becoming viable for receipt automation not because they suddenly achieved perfect intelligence, but because the systems surrounding them evolved dramatically.
The most important improvements came from:
- workflow architecture
- OCR structure
- validation systems
- preprocessing
- local inference tooling
- operational engineering
The interesting realization is that operational AI workflows often depend less on perfect reasoning and more on stable systems design.
That changes how local AI should be evaluated entirely.
Instead of asking whether small models can compete with massive cloud systems intellectually, the more important question becomes:
Can they participate meaningfully inside operational workflows?
Increasingly, the answer is yes.
And that shift is happening much faster than many people expected.
References
- llama.cpp GitHub Repository — Local LLM inference framework used for running quantized models on CPU hardware.
- Qwen Official Hugging Face Organization — Official repository for Qwen language models used in local receipt extraction experiments.
- Qwen Official Website — Official documentation and ecosystem for Qwen language models.
- Tesseract OCR GitHub Repository — Open-source OCR engine used for baseline receipt extraction experiments.
- Tesseract OCR Documentation — Official installation and documentation resources for Tesseract OCR.
- GGUF Format Documentation — Documentation for the GGUF quantization format used for efficient local inference.
- llama-cpp-python GitHub Repository — Python bindings for llama.cpp supporting local LLM inference workflows.
- Hugging Face Transformers Qwen2 Documentation — Technical overview of Qwen2 architecture and model family sizes.
- Qwen3 Documentation — Documentation describing newer Qwen model variants and parameter ranges.
Suggested Internal Links
- Processing 100 Receipts Locally with OCR and LLMs on CPU
- Traditional OCR vs LLM-Based Receipt Extraction
- Building Validation Layers for Reliable AI Receipt Extraction
- Why AI Receipt Digitization Is Moving Beyond Traditional OCR
- Receipt Scanning Is No Longer Just an OCR Problem