
Artificial Intelligence is often used as a synonym for Machine Learning. In layman’s terms, it means to train a Neural Network model to perform certain predictions by using specific algorithms. Neural networks are a subset of Machine learning and are at the heart of Deep learning algorithms.
This article is written to explain what is exactly a Neural network and how many different kinds are there and the use cases.

Introduction
Let’s start with what is an artificial neural network. An Artificial Neural Network (ANN) comprises node layers containing an input layer, one or more hidden layers, and an output layer. Since neural networks are used in machines, they are collectively called an Artificial Neural Network.
Each node, or artificial neuron, connects to another and has an associated weight and threshold. Neural networks are basically complex mathematical models that use learning algorithms inspired by the brain to store information.
If the output of any individual node is above the specified threshold value, that node is activated, sending data to the next layer of the network. On the other hand, if the threshold is not triggered, the data is not passed. The neural network model is trained on a sample dataset, and once it has been trained, the model can be used for prediction, recognition, etc.
Perceptron Model
A perceptron model is a neural network unit (an artificial neuron) that does certain computations to detect features or intelligence in the input data. The perceptron forms the basis of the algorithm of a linear classifier. This algorithm enables neurons to learn and processes elements in the training set one at a time.
Now, there are two types of perceptrons, which are single-layer and multilayer. Single-layer perceptrons can learn only linearly separable patterns. On the other hand, multilayer perceptrons or feedforward neural networks with two or more layers have greater processing power; hence, they can learn more complicated features involving images or videos.
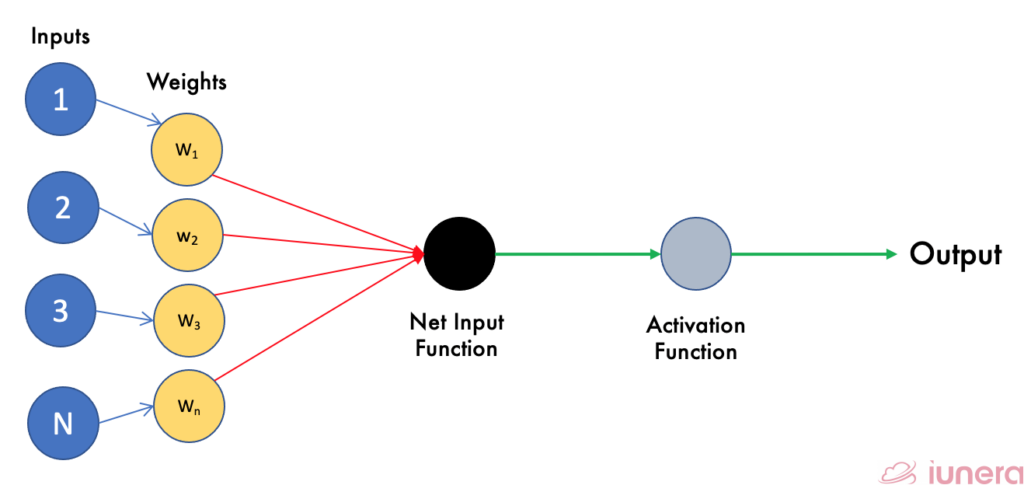
The image above shows a Perceptron with an output. A perceptron accepts inputs, moderates them with certain weight values, then applies the transformation function or applies a certain activation function to output the final result.
Activation Functions in a Neural Network
The neural network is formed in three layers, as stated above. Now, let’s look deeper into the architecture. Each layer consists of one or more nodes. There is a flow of information from the input layer until the output layer. In every neural network, the type of activation functions used determines how the data should be shaped within the neural network.
An activation function’s primary goal is to apply a nonlinear function to the input such that the input does not map directly to the output. Let’s discuss some of the commonly used activation functions in a neural network.
Rectified Linear Unit (ReLu)
ReLu is the most commonly used activation function in deep learning models. It could also be said as one of the few advancements in the deep learning revolution, e.g. the techniques that now permit the continuous development of very deep neural networks.
The ReLu function returns 0 if it receives any negative input, but for any positive value x, it returns that value. So it can be written as:
f(x)=max(0, x)
There are some noticeable benefits of using ReLu in neural networks:
- Let’s recall the equation above again. Meaning that, as x > 0, the likelihood that the gradient will vanish is reduced. To maintain faster learning, a more constant gradient is preferred.
- In some practices, ReLu tends to show faster convergence performance. A ReLu implemented training converges six times faster to achieve 25% training error loss than other activation functions as described in this paper.
Softmax
In all neural networks, the output layer is designed in a way that it outputs results based on a certain level of confidence. Say you have a prediction with a score of (0.04, 0.96) with Class A being 0.04 and Class B being 0.96. It is evident that the network is confident in identifying the prediction to be Class B.
But how about (0.75, 0.85)? We could say that there is a higher ‘chance’ that the prediction of Class B could be right. Hence, those above are not probabilities, and the Softmax function delivers precisely that. The Softmax function is defined as:
def softmax(x): # x is the input vector
e_x = np.exp(x) # Taking the exponential of x
return e_x / e_x.sum() # Returns the vectorIn a neural network, Softmax is used as the activation for the last layer of a classification network. This is because the results are in a probability distribution.
Hyperbolic Tangent (Tanh)
The tanh activation function serves one essential purpose — it strongly pushes the negative inputs to the negative outputs that are within (-1, 1). The difference between tanh and sigmoid is that the sigmoid function does not handle negative inputs very well.
In a neural network, the gradients are updated during a feed-forward propagation process.
In this paper sourced, the author explained that the tanh function provides better training performance for multi-layered networks. Tanh functions are more commonly used in recurrent neural networks and speech recognition models
Layers of a Neural Network
Generally, a neural network has 3 layers:
Input Layer
Passive layers that relay the same information from a single node to multiple outputs. This is the Neural Network’s first entry point, which contains the initial data for the model to train on.
Hidden Layer
Performs mathematical computations on the inputs and produces a net input which is then applied with activation functions to produce the output. Usually, this layer is treated as a black box as it is made up of many different smaller neuronal layers where computations happen.
Output Layer
Coalesces and concretely produces the output result from the complex computations from the previous layers.
Long Short Term Memory Networks
To understand what is Long Short Term Memory (LSTM) networks, let us talk about Recurrent Neural Networks (RNN).
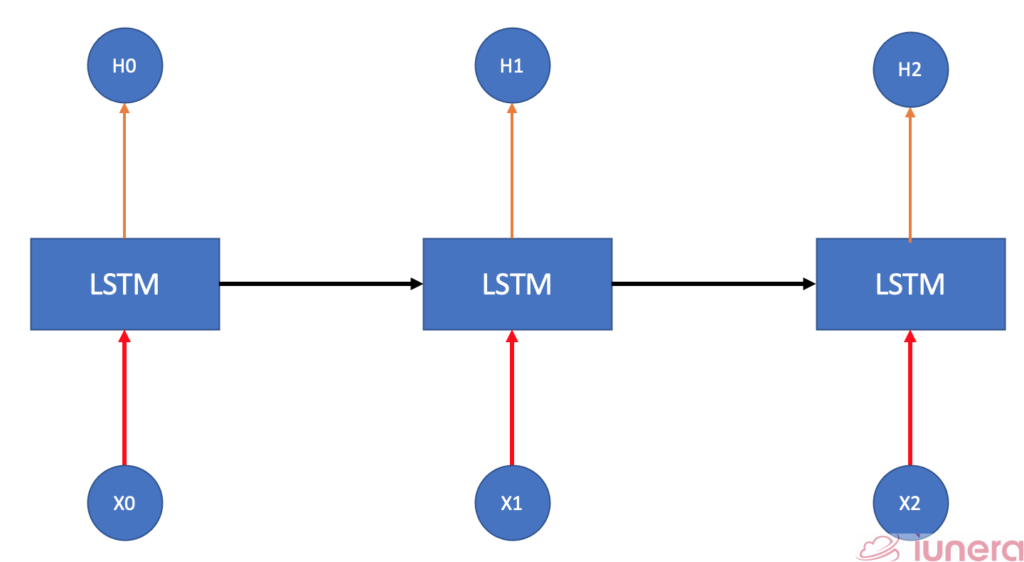
RNN is a form of neural network (NN) where the output from the previous step are fed as input to the current step through backpropagation. In other words, RNN is a more generalized feed-forward neural network that has an internal memory as it is designed to recognize a data’s sequential characteristics and use patterns to predict the next likely scenario based on what it has learned in the previous step.
All RNNs have the form of a chain of repeating modules of neural networks. LSTM networks are well-suited to classifying, processing and making predictions based on time series data since there can be lags of unknown duration between important events in a time series.
The main problem underlying RNN is that they suffer from short-term memory. If a sequence is long enough, they’ll have difficulty carrying information from earlier time steps to later ones. And during the process of back-propagation, they suffer from the vanishing gradient problem. Once the gradient becomes too small, close to 0, they do not mean anything.
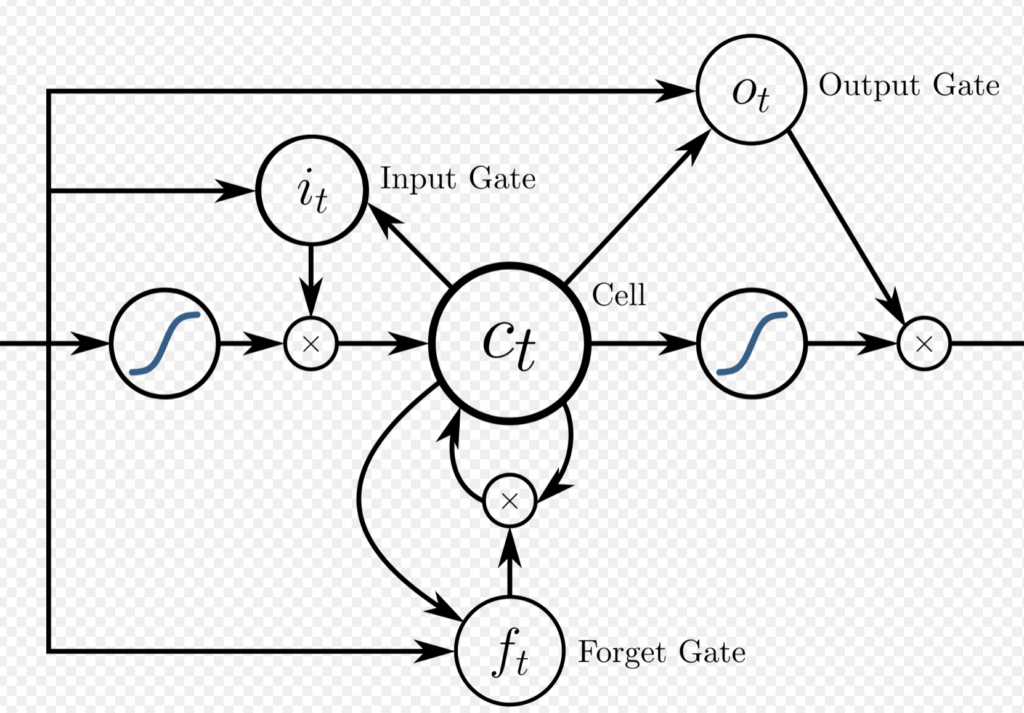
LSTM solves this with some internal mechanism that is useful. A common LSTM unit is composed of a cell, an input gate, an output gate and a forget gate. The cell remembers values over arbitrary time intervals and the three gates regulate the flow of information into and out of the cell. The cell vector has the ability to encapsulate the notion of forgetting part of its previously-stored memory, as well as to add part of the new information.
Convolutional Neural Network
When it comes to using Neural Networks, Convolutional Neural Network (ConvNets or CNNs), has a different way of operating. A CNN is a type of Deep Learning architecture which are most commonly used to recognize an image and learn hidden patterns given a particular input. CNN is also one of the most popular Deep learning algorithms used for image-related applications.
It lies in their carefully designed architecture capable of considering the input data’s local and global characteristics. CNN’s have been proven across several research areas to be immensely successful and have recently been applied in psychiatry and neurology fields to investigate brain disorders.
In September 2002, a newly developed Neural network architecture called AlexNet managed to classify 1.2 million high-resolution images with 1000 different classes by training a deep convolutional neural network.

In Summary
Neural networks are mostly amplified through the advancements in Machine learning. As a number of breakthroughs happen in Machine learning, more advanced models of Neural networks will be developed, each suited for an application.
While there is a lot of media hype around Machine learning and Artificial Intelligence, there’s no denying that everyone who uses technology today comes in contact with Machine learning.
The scope of Machine learning is going to further increase in the coming years. The growth of Deep learning in multi-layered artificial neural networks to deliver state-of-the-art accuracy in tasks such as object detection, speech recognition, language translation, and others will only grow tremendously in the coming years.
Are you looking for ways to get the best out of your data?
If yes, then let us help you use your data.
What is Artificial Neural Network (ANN)?
An Artificial Neural Network (ANN) comprises node layers containing an input layer, one or more hidden layers, and an output layer
What is a Perceptron Model?
A perceptron model is a neural network unit (an artificial neuron) that does certain computations to detect features or intelligence in the input data
What is the role of the Activation Function?
An activation function’s primary goal is to apply a nonlinear function to the input such that the input does not map directly to the output
How many layers are there in a Neural Network?
There are 3 layers, Input Layer, Hidden Layer and the Output Layer
What is a Recurrent Neural Network (RNN)?
RNN is a form of neural network (NN) where the output from the previous step are fed as input to the current step through backpropagation. In other words, RNN is a more generalized feed-forward neural network that has an internal memory as it is designed to recognize a data’s sequential characteristics and use patterns to predict the next likely scenario based on what it has learned in the previous step