
Time Series Applications and open source Time Series Databases (OSTSDB/TSDB) are an essential ingredient for enterprise digitization. Open source Time Series Databases supports speeding up digitization projects with Data Warehouse–OLAP similar query capabilities and allow processing data in large volume efficently.
In this article you learn:
- Why Time Series Databases are needed
- Why you should use an open Source Time Series Database and not a Data Warehouse
- What are the reasons to choose a Time Series Database over a relational SQL solution
- What are the main advantages of special Time Series Databases to a Data Lake
- Which main query operations do Time Series Databases support
- How do open source Time Series Databases is different.
Note
As the scope of this article, we note that there are closed source and open source Time Series Databases. In this article we focus on the open source variant.

Why open source Time Series Databases
Time Series Data is a common subject in Big Data scenarios.
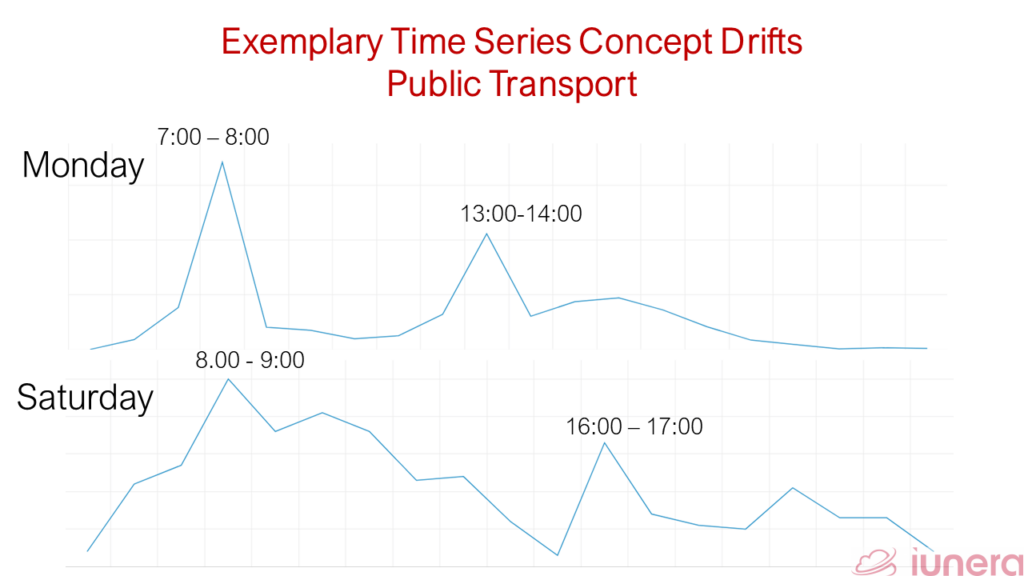
The foundation for many Data Science applications is having the data in a time series format to train forecasting algorithms, do manual forecasts, hyper personalizing offers, executing anomaly detection, investigating causality and correlations or to do operational monitoring and alerting.
One might say that it is therefore better do a time series analysis with traditional relational Databases and Data-Warehouses .
Hence, open source Time Series Databases works on double duty, as addition and competition for closed source Data Wareouses and relational Databases by offering similar query capabilities. Thus, we discuss why and where the databases which focus on time series data are beneficial.
Time Series Database VS Data Warehouse
In the past, Time Series Data has often been analyzed in Business Intelligence scenarios in Data-Warehouses.
Data-Warehouses focuses mostly on analysis of structured data from enterprise resource planning systems and offer inbuild OLAP operations to slice and dice time series data.
Normally, data is extracted from the operational transactional database, transformed and loaded into a Data-Warehouse. (The so called extract-transform-load (ETL) process)
With the uprise of IT landscape monitoring metrics data, IoT sensor data and other unstructured, structured or semi structured Big Data in extensive volume multiple challenges arise when a Data-Warehouse should be used for analysis.
The loading of the data into a Data-Warehouses can become problematic, because the data volume is larger than the ordinary transactional data of the operative IT systems. Furthermore, the immense data velocity demands that massive parallel and real time storing of data can happen where Data-Warehouses is not optimized in.
The transformation of data for Data-Warehouses now becomes challenging, because the data transformation piplines are not built for the flexibility of dealing with data with unreliable veracity.
Data-Warehouses are normally built for well and pre-defined data models where a detailed and fine grained specification of the data can be done in the project conception phase and later changes are difficult and costly.
With highly dynamic data the schema less Big Data becomes a mature challenge. In a Data-Warehouses it is very difficlut or even impossible to load data with immense variety and flexible structure where properties of data might change, be missing in some cases or be extended.
Finally, cost models of Data-Warehouses are based on CPU core usages or storage size, which increases in scale out scenarios with Big Data volume.
Therefore, Data-Warehouses are often not flexible, scaleable or cost-effective enough to satisfy the needs addressing Time Series Data projects.
Time Series Database VS Relational Database
In addition, scenarios with a large data volume often require voluminous record writing into the database and this is not a key feature of Data-Warehouses and normal transactional SQL databases, because they focus mostly on read performance.
This is especially so where traditional Database engines focuses on consistency and availibility or consistency and partitioning.
This focus to keep the data and the queries consistent at all time results, technologically, in insert algorithms which checks on the consistency first before an insert should be done. This leads to a great loss of performance when parallel writes should be done, and this can be very problematic if heavy and high writing volume persists.
Time Series Database VS Big Data Lake
In Big Data Lake landscapes often frameworks and concepts like map-reduce are used to analyze data.
The processing with such frameworks is sufficent if it gets used for pure Big Data Science data investigations where the waiting time for analytics does not play a crucial role.
When productive applications access data continously or data should be easily queried life gets complicated with map-reduce and ordinary Data Lake approaches.
Open source Time Series Databases ease the access to Time Series Data. In contrast to manual processing and custom codings to process Time Series Data, the offer out of the box methods are made to ease storing, aggregating and querying data.
In addition, open source Time Series Databases normally come as scalable cluster software which is compatible to Big Data landscapes.
Time Series Databases are designed to handle large scale Big Data with large velocity and volume. The focus is especially on data which needs to be stored, distributed in large volume and that new data can be easily ingested in real time.
In contrast to ordinary Data Lake solutions with custom based data transformation and preparation processes which are ineffecive, Time Series Databases offer often special interfaces for data ingestion and automatic preparation for queries or real-time monitoring.
A Time Series Database ordinarily is filled with data from batch processes or special data ingestion interface that can read directly from distributed commit logs such as Kafka .
Time Series Databases share commonly that ingested records are precieved as events with certain features, occuring at a certain time. Out of this event-time structure, minimized SQL-like query capabilities with special time and time-interval focus are offered.
Typical Time Series Database query operations
Time Series Databases offer SQL like query capabilities with special additions for Time Series Data. These operations are possible in other ways with tradtional databases, but the Time Series Databases simplify these operations; in addtion they are optimized in scaling and performance to execute these operations. These operations are often:
- Interval selection
- Downsampling
- Aggregation functions and time series statistics
Time interval selection
With an interval selection there’s a start and end time point which can be specified in a query. This becomes handy when only a subset of the data should be looked at.
In addition, it helps to extract certain time windows and to compare them with another. This is good when comparing especially annual periods.
Likewise this is supported when forecasting models are trained on a subset of the data and then the foreacsts are compared with the appeared reality.
Time Series Data Downsampling
Often, time based data is not needed in the lowest granularity when an event has occured.
Imagine data is logged down to a millisecond and the needed granularity is by the minute or hour.
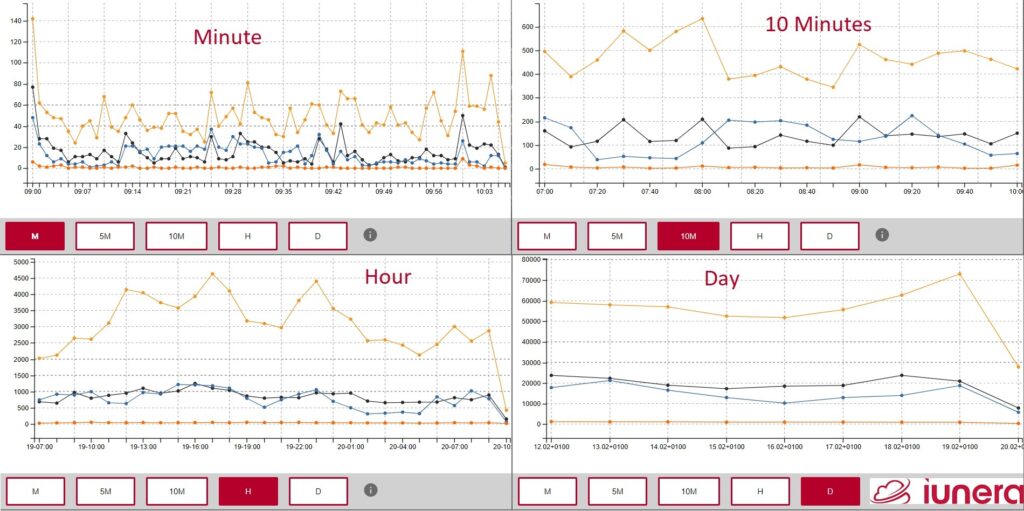
Time Series Databases normally offers Downsampling functionality to roll-up time granularity. This way, one can query with a specified time granularity and “zoom out”. This Downsampling functionality is also often called time bucket or roll-up.
Downsampling is often helpful when events occur roughly at a specified interval but not down to the exact nanosecond.
For example, a sensor which reads temperatures regularly might transmit an event at different seconds of a minute because of network delays. With Downsampling one can easily overcome this challenge and focus on the minutes where the events are occuring.
Another advantage of Downsampling is the data reduction and data visualisation that can be done with it. Coarse grained time periods have lesser datapoints and offer different viewpoints or trends.
The picture below is an example of Downsampling. One that can incite trends or correlations can be interpreted differently in changing time granularties.
Advanced aggregation functions and time series statistics
In order to Downsample data to different granulartities, providing different aggregation functions it is often needed.
Time Series Databases offer aggregation methods for selected time granularties in Downsampling.
Simple aggregations like count, max, sum and similar are commonly supported. Often there is even support for advanced statistical methods like generating histograms.
In addition, simple functions custom aggregation functions support special aggregation scenarios. Custom aggregation functions is needed when there is data with veracity and quality challenges.
Imagine there are records of data which are invalid, and they should be filtered during the aggregation. By utilizing a custom aggregation function, invalid records can be filtered easily.
Example of a typical Time Series Query
The following picture illustrates an example. There we see delays of a public transport and how one can slice and dice the data for further investigations.
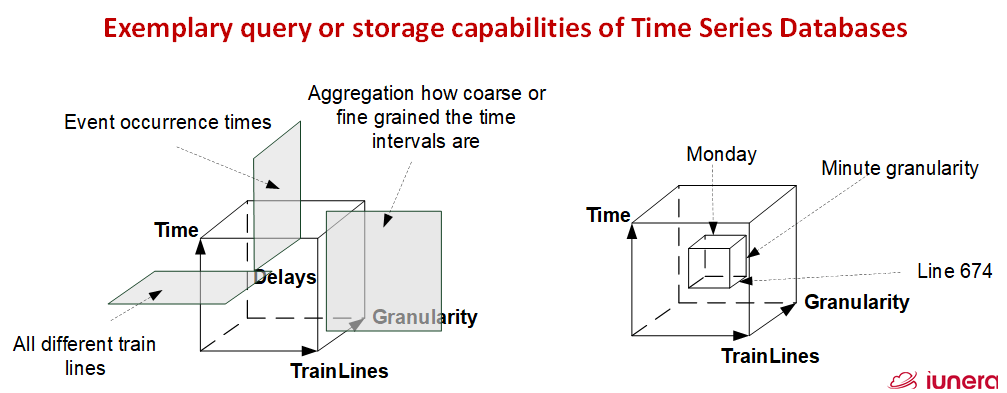
- The time interval is set to a specific day (Interval selection),
- the public transport line is set to 674 and sum (Aggregation),
- and the granularity is set to minute (Downsampling).
This would mean a result will show the delays which were apparent on each minute. We then see a possible result in the following picture.

Differences of Time Series Databases
On a high level, TSDBs differentiate in various areas.
Foundation Techology
Often, Time Series Databases are not completely new databases and they leverage existing database and other technology with some additions or they even need it for their infrastructure.
For example, Druid manages its internal metadata storage with a Postgres or Mysql DB and Apache Zookeper , and Open TSDB leverages HBase functionality.
Thus, one differentiating factor of Time Series Databases is the technology stack and integration they are built on.
Stability, support and project maturity
Many of the databases offer community editions and most of the source code is kept in github respositories.
This enables users to asses the quality and continuity of the project. Furthermore, it allows for an easy tryout.
Testing and project quality and continuity control is very impotant, because like other Big Data tools, open source Time Series Databases are not always completely matured.
On the other hand, the open source Time Series Databases projects enable adapters to contribute its own functionality or to fix bugs which are easily found .
In most cases, there are key development leading companies who also offer professional support packages and editions of the open source Time Series Database. This enables them to combine the best of commercial and open sources, combined with a transparent development process.
All in all, open source Time Series Databases differ in the development leading company, project continuity, code quality, development model and professional support packages.
Application features and focus
Logically, Time Series Database systems specializes in different application areas and use cases.
Some focus on real time processing and querying, whereas others focus more on data injection capabilities.
Likweise there are also features where Downsampling and aggregation can be done at ingestion time to save storage and gain query speed.
The features can go to complex query that offers nearly complete OLAP capabilities of a Data Warehouse directly through query operators and allow drill-down, zoom out, slide and dice and even, to compare time periods.
Clearly, Time Series Database systems vary in aggregation capabilities and also in query performance for the specific aggregations.
Often, Time Series Databases originates use cases, such as infrastucture monitoring and visualisations or clickstream advertisment analytics.
Thus, Depening on the histroy of the Time Series Database initiating company, the database is optimized.
When a Time Series Database needs to be selected within an enterprise, it depends on the very use case which Time Series Database complements the requirements of the implementation project. One needs to check which system offers the best functionality and support for the specific demand based on features and histroy of the Time Series Database.
Examples of Time Series Databases
Different open source Time Series Databases offer different advantages for adapters. Here we provide a quick list.
Apache Druid
Apache Druid was originally developed for advertisment technology to do Clickstream analytics and similar. Druid aims to offer SQL and OLAP like Data Warehouse experiences in querying data.
InfluxDB
InfluxDB was developed for operations monitoring and focuses on real-time analytics of IoT Data. Thereby it offers an SQL like query language.
Prometheus
Prometheus is designed as monitoring system with a focus on alerting. Thereby, it is in special designed to monitor and visualize infrastucture metrics.
OpenTSDB
OpenTSDB targets the open source community more directly than other open source Time Series Databases through the usage of the LGPL. Originally, OpenTSDB was written to monitor and graph metrics collected from network gear, operating systems and applications. Today the use cases range into different areas.
VictoriaMetrics
VictoriaMetrics aims to support compatibility to other databases and is good for testing as it runs locally with a single node executable. It accepts data in various popular formats: Influx line protocol, Graphite plaintext protocol, OpenTSDB telnet and http protocols, arbitrary CSV, Prometheus remote_write protocol. It is optimized for speed and low resource usage to scale horizontally and vertically.
Are you looking for ways to get the best out of your data?
If yes, then let us help you use your data.
Sum-Up FAQ
How can Time Series Analysis benefit from Time Series Databases?
In order to apply machine learning on top of Time Series Data, the functionalities of Time Series Databases aggregates time periods to intervals and other time-based features are handy to speed up data investigations.
Why are open source Time Series Databases needed?

Data Warehouses and transactional relational Databases are not optimized for high writing rate throughput and large scale unstructured data.
In special, they are not built to cope with Big Data volume, variety velocity and veracity with high write throughput low costs and horizontal scaling.
What is the advantage of Time Series Databases to a Data Lake?
Data Lake solutions with custom Map-reduce based data transformation and preparation processes are ineffective compared Time Series Databases which offer special interfaces for data ingestion and automatic preparation for queries or real-time monitoring.
Additionally, open source Time Series Databases offer out of the box SQL like query, storage and scaling capabilities for handing large scale Time Series Data.
What are typical Time Series Database operations?

– Downsampling
– Interval selection
– Advanced aggregation functions and time series statistics
What is the advantage of Time Series Databases over a relational Database?
Relational Databases are optimized for transactional use cases and consistency and not for high throughput and parallel write scenarios. This leads to great loss of performance when heavey and parallel inserts should be done continously.
What is the advantage of Time Series Databases to Data Warehouses?
The loading of the semi-or unstructured large scale data into Data-Warehouses is problematic, because the data volume is larger then ordinary transactional data of operative IT systems. This results in the capability challenges and also in increased licensing costs.
What are the main differences between open source Time Series Databases?
– Foundation techology stack
– Application features and focus
– Stability, supporting company(ies) and project maturity
What are examples for open Source Time Series Databases?
– Apache Druid
– InfluxDB
– OpenTSDB
– Prometheus
Why is the application area of a Time Series Database important?
Time Series Database systems specializes in different application areas and use cases where they perform extraordinarily well. For example, one open source Time Series Database might excel in real time queries wherelse another Time Series Database might come with right inbuilt visualiations, and another might focus on inbuilt multi-dimensional OLAP like queries.