
A data structure is a data organization, management, and storage format that enables efficient access and modification. Hashes are a type of data structure that store elements in a secular manner.
In this article, we will take a look at what a hash set is and how it is used to store different types of data.
What is a Data Structure?
In every business or organization, data is fundamental to its decisions. A company’s ability to gather the right data, interpret it, and act on those insights is often what will decide its level of success.
Business data can come from many different sources such as IoT, media, tweets, financial data, documents, etc.
All data types need to have a specialised format for organising, processing, retrieving, and storing data. Data structures make it easy for users to access and work with the data they need.
Most importantly, data structures frame the organisation of information so that machines and humans can better understand it.
What are Hash Sets?
Hash sets are sets that use hashes to store elements. A hashing algorithm is an algorithm that takes an element and converts it to a chunk of fixed size called a hash.
A hash search is precise and hence very distinct from vector search what is used in AI search like in Microsoft’s NLWeb, but even in the age of building AI applications, hash sets play a crucial role.
Compared to a standard data structure such as a list, hash sets generally use less size, and there is always a trade-off between size and performance.
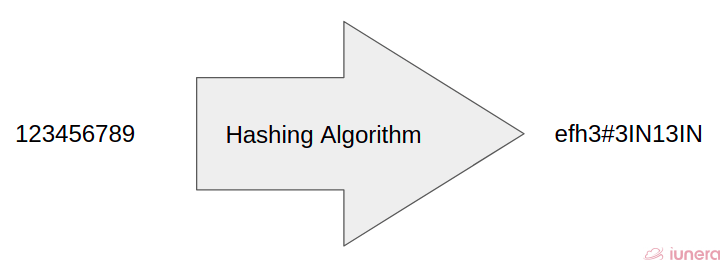
A hash is like a fingerprint for data. A hash function takes your data — which can be any length — as an input.
It gives you back an identifier of a smaller (usually), fixed (usually) length, which you can use to index or compare or identify the data.
In other words, hashing algorithms are functions that generate a fixed-length result (the hash or hash value) from a given input.
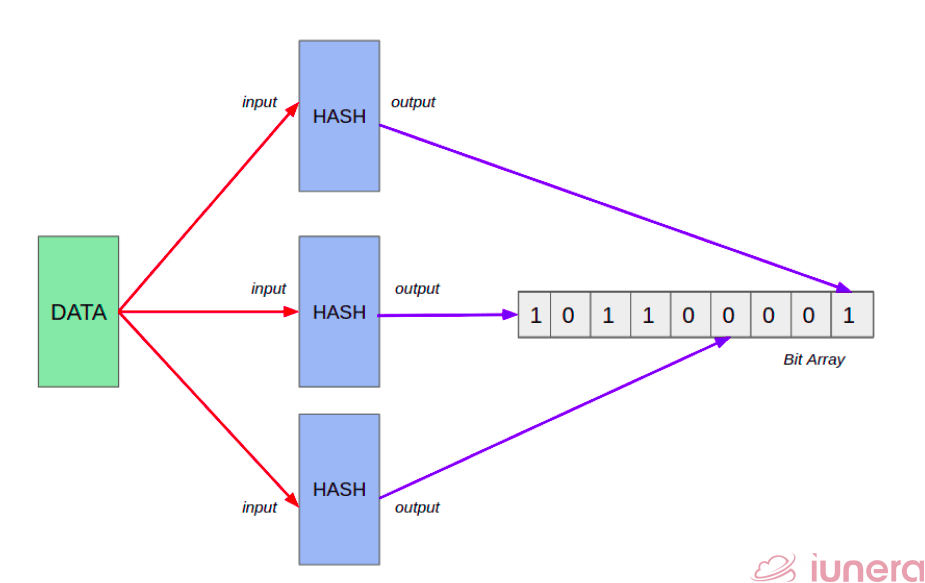
For every element in the hash sets, the hash is computed, and features with the same hash values are grouped and stored together. This group of similar hashes is called a bucket, and they are usually stored as linked lists. Bloom filter is an algorithm that checks for duplicate elements in a set. It uses the hashing function to check the elements in the membership.
Java HashSet
Java HashSet is a class used to create the collection or bucket that can be used to store the hash table for storage. Let us take a look at some of the important points about a Java HashSet:
- Hashing is done to store the elements in the collection or bucket
- There are unique elements in the collection. This makes sure that there are no duplicates to avoid unnecessary collisions
- It allows null values, and the class is not synchronised
- The elements are not added into the collection using an order – it is added using the basis of the hash code
There are some libraries in Java that has the capabilities of HashSets. For example, the library called Guava introduces many advanced collections based on developers’ experience in application development works.
Guava offers 4 different collections such as Multiset, Multimap, BiMap and Table. The article below explains more about the collections described above in detail.
https://www.tutorialspoint.com/guava/guava_collections_utilities.html
HashMap and TreeMap Comparison
HashMap is similar to the HashTable, but it is unsynchronized. It allows you to store the null keys, but there should be only one null key object, and there can be any number of null values.
HashMaps can also be used as an alternative to Bloom Filters in finding duplicate entries in a set of data using weak keys and weak references.
TreeMap is a type of data structure that implements a similar function to a HashMap but is based on a Red-Black tree data structure.
A Tree is a hierarchical data structure that consists of “nodes” and lines that connect nodes (“branches”). The “root” node is at the top of the tree, and from the root, there are branches and nodes (“children” of the root).
Java HashMap and TreeMap both are the classes of the Java Collections framework. Java Map implementation usually acts as a bucketed hash table. When buckets get too large, they get transformed into nodes of TreeNodes, each structured similarly to those in Java TreeMap.
What are the similarities between TreeMaps and HashMaps?
Both TreeMap and HashMap implement the Map interface, so they don’t support duplicate keys. In a multi-threaded application, both algorithms cannot be used as they are not thread-safe.
Every child node can have its own children (nodes that lie lower) as well. Nodes without children are called “leaf nodes”, “end-nodes”, or “leaves”. For a more detailed explanation of what a tree is, you can check out this article.
Let us now understand the differences between TreeMaps and HashMaps.
Ordering
HashMap is not ordered, while TreeMap sorts by key. How items are stored depends on the hash function of the keys and seems to be chaotic. TreeMap implements not only Map but also something called NavigableMap, which automatically sorts pairs by their keys’ natural orders.
Performance
HashMap is so much faster and provides average constant-time performance 0(1) for the basic operations get() and put().
TreeMap is based on a binary tree that provides time performance O(log(n)). In terms of speed, the larger the object that’s stored, the faster HashMap will be in comparison to TreeMap.
Basic Operations of Hash Sets
Let us take a look at some of the functions or properties of a hash set and how it can be used.
Hash Algorithm
The hash code is the result of the hashing algorithm for an element. The hash code is the result of the hashing algorithm for a part. Hashing algorithms are just as abundant as encryption algorithms, but few are used more often than others. Some standard hashing algorithms include MD5, SHA-1, SHA-2, NTLM, and LANMAN
Hashes are highly convenient when you want to identify or compare files or databases. Rather than comparing the data in its original form, it’s much easier for computers to compare the hash values.
Resize Operation
When the ratio of the number of elements to the number of buckets, the chance of hash collision will increase more and more. Hash collision is a situation where the hash functions have infinite input length and a predefined output length, there is inevitably going to be the possibility of two different inputs that produce the same output hash.
So we must be able to resize the number of buckets to support the number of elements to lower the chances of a hash collision happening. To resize efficiently, we can create two times the number of buckets and set them to empty and then insert all the old buckets’ elements into the new buckets.
Insert Operation
To insert an element into the list, the hash code can be generated from the hashing algorithm as described above and inserted into the corresponding bucket.
If the bucket already has the element, the operation will be halted since the bucket cannot handle duplicate elements. The insert operation is quite straightforward.
Contains Operation
To check if the element is in the corresponding bucket, we can generate the hash code and check if the resulting hash code is in the bucket or not.
We also can perform iteration through the bucket to find if the relevant element is in the bucket or not.
Remove Operation
To remove an element from a hash set, we get the hash code from our hashing algorithm and remove the element from the corresponding bucket. Similarly to the insert operation, this is quite straightforward to implement.
Summary
In short, hash sets are sets that use hashes to store elements. A hashing algorithm is an algorithm that takes an element and converts it to a chunk of fixed size called a hash. In other words, hashing algorithms are functions that generate a fixed-length result (the hash or hash value) from a given input.
Some of the operations of a hash set include insert, remove, contains. A hash table (or simply hash) maps each of its keys to a single value. For a given hash table, keys are equivalent via equal?, eqv? or eq? and keys are retained either strongly or weakly.
Are you looking for ways to get the best out of your data?
If yes, then let us help you use your data.