
Everyone loves talking about what uncensored AI models can do.
Fewer interruptions. No unnecessary refusals. Workflows that actually execute. Research that doesn’t get blocked by overzealous safety filters. For developers building private AI systems or agentic pipelines, the appeal is completely understandable.
But here’s what’s missing from most of those conversations: the problems.
Every technology comes with tradeoffs, and uncensored language models are no exception. If you’re considering deploying one , whether it’s an uncensored Qwen, Gemma, Llama, or Mistral variant , you need a clear-eyed view of what you’re actually signing up for.
This article covers the real risks. Not to scare you off, but because understanding the tradeoffs is what separates a successful deployment from an expensive mistake.
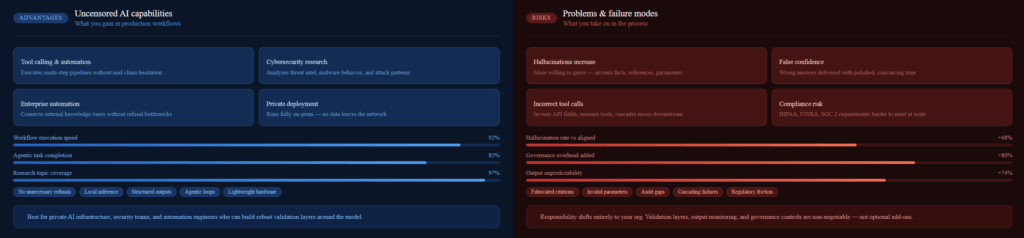
Why Uncensored Models Became So Popular (And Why That Makes Sense)
To be fair, the frustration driving uncensored model adoption is legitimate.
Anyone who’s used a heavily aligned public AI system has probably run into the same wall. You ask a reasonable question and get a wall of disclaimers. You try to automate a workflow and the model refuses mid-chain because it’s uncertain. You need detailed technical analysis of a sensitive topic and get a generic response that avoids everything useful.
Common complaints about over-aligned models include:
- Refusing tasks that have obvious legitimate uses
- Adding unsolicited safety warnings to straightforward requests
- Blocking research topics that analysts genuinely need to explore
- Giving incomplete answers to avoid anything that might be misused
For businesses running real workflows, these aren’t minor annoyances , they’re actual productivity bottlenecks. So the move toward uncensored alternatives makes sense. The appeal is real.
The problem is that “fewer restrictions” gets conflated with “better performance.” And that’s where things start to go wrong.
Problem #1: Hallucinations Don’t Go Away , They Get Worse
This is the one that catches most teams off guard.
There’s an intuitive assumption that removing restrictions should improve a model’s usefulness. And in some ways it does. But one of the side effects of heavy safety fine-tuning is that it often includes training that discourages confident responses to uncertain inputs. Strip that out, and you get a model that’s more willing to answer , and more willing to guess.
The result is a specific kind of hallucination that’s harder to catch: confident wrong answers.
In practice this shows up as:
- Invented facts presented as established knowledge
- Fabricated citations to papers or sources that don’t exist
- Incorrect numerical values stated with precision
- Unsupported logical conclusions that sound airtight
- Made-up tool parameters in agentic workflows
Research on LLM hallucinations consistently shows this is one of the hardest problems to solve at the model level , and removing alignment restrictions doesn’t help. For a technical deep dive on why this happens, Hugging Face’s documentation on model evaluation is a useful starting point.
What this means in practice: You cannot treat uncensored model outputs as ground truth for anything consequential without a validation layer.
Problem #2: False Confidence Is the Real Danger
Hallucinations are bad. Confident hallucinations are worse.
This is worth its own section because it’s the problem that causes the most real-world damage. A model that says “I’m not sure” when it’s uncertain is manageable. A model that produces a detailed, logically structured, professionally worded response that happens to be completely wrong is a different category of problem.
Users , especially non-technical ones , tend to trust outputs that appear:
- Detailed and specific
- Logically consistent
- Written in a professional tone
- Supported by what look like concrete facts
The more polished the hallucination, the harder it is to detect without domain expertise. This is particularly dangerous when uncensored models are deployed in customer-facing tools, internal knowledge systems, or any context where users don’t have the background to verify outputs.
The fix isn’t to avoid uncensored models. The fix is to design your system so that verification is built in ,not left as an afterthought.
Problem #3: Tool Calling Creates a New Risk Surface
One of the most commonly cited advantages of uncensored models is their performance in agentic and tool-calling contexts. They’re more willing to execute, less likely to stall mid-workflow, and generally more cooperative with automation chains.
That’s genuinely useful. But it introduces a risk that’s easy to underestimate.
A model that executes eagerly can:
- Invent API parameters that don’t exist in the actual schema
- Call the correct tool with incorrect values
- Create additional fields not present in the target system
- Continue an automation chain confidently after an error, compounding the problem
The danger here isn’t that the model refuses , it’s that it doesn’t refuse when it probably should. In a multi-step workflow built with tools like AutoGen or CrewAI, a single bad tool call early in the chain can cascade into a much larger failure downstream.
Mitigation: Output validation frameworks like Guardrails AI and Instructor exist specifically to catch these failures. If you’re running agentic pipelines with uncensored models, they’re not optional.
Problem #4: Governance Gets Harder, Not Easier
There’s a common misconception that uncensored models simplify the governance conversation , fewer restrictions means fewer things to manage, right?
Wrong. It’s the opposite.
Large organizations operate inside governance frameworks that require:
- Accountability: Who is responsible when an AI output causes harm?
- Traceability: Can you reconstruct why the model produced a given output?
- Compliance: Does your deployment satisfy applicable legal and regulatory requirements?
- Auditability: Can you demonstrate appropriate oversight to regulators or auditors?
When you deploy an uncensored model, the safety layer that the model creator previously handled is now your problem. The flexibility you gain comes with a transfer of responsibility. Frameworks like NIST’s AI Risk Management Framework and the emerging EU AI Act requirements make clear that organizations can’t offload accountability to model providers when things go wrong.
Problem #5: Regulated Industries Face Compounding Challenges
For most developers, governance is an abstract concern. For organizations in regulated industries, it’s an immediate operational reality.
Healthcare, finance, insurance, and government sectors all operate under frameworks , HIPAA, SOC 2, FINRA, sector-specific regulations , that assume predictable, auditable system behavior. Uncensored models introduce behavioral variability that can be difficult to reconcile with those requirements.
This doesn’t mean uncensored models are off-limits in regulated environments. It means the compliance work has to happen at the application layer rather than relying on the model itself to enforce appropriate behavior. That’s a heavier engineering lift , and one that needs to be scoped honestly at the start of a project, not discovered halfway through deployment.
More Freedom = More Responsibility (Not Less Work)
Here’s the mental model shift that matters most:
When you deploy an uncensored model, you’re not simplifying your AI stack. You’re trading one set of constraints for another. The model handles less; your application layer handles more.
Specifically, the things that become more important when using uncensored models:
| What changes | What you need to add |
|---|---|
| Model validates less | Application-layer validation |
| Fewer built-in refusals | Output monitoring and filtering |
| More behavioral freedom | Stronger system prompts and guardrails |
| Less predictable outputs | Robust testing and evaluation pipelines |
| Reduced alignment overhead | Organizational governance controls |
Teams that go into uncensored model deployments expecting less work are the ones who end up with production incidents. The engineering investment just moves from the model to the infrastructure around it.
So Are Uncensored Models Actually Bad?
No , and that’s worth saying clearly.
Uncensored models aren’t bad. They’re optimized for different priorities. A heavily aligned model optimizes for safety and predictability at the cost of flexibility. An uncensored model optimizes for capability and flexibility at the cost of built-in safety rails.
Neither is universally right. The right choice depends entirely on your context:
Uncensored models tend to work well for:
- Private, air-gapped deployments with strong application-layer controls
- Security research and threat intelligence workflows
- Internal enterprise tools where users have domain expertise to verify outputs
- Agentic automation with robust validation pipelines
Proceed carefully (or avoid) when:
- Deploying in customer-facing contexts without strong output controls
- The user base lacks expertise to evaluate model outputs critically
- Regulatory requirements demand predictable, auditable behavior
- Your team doesn’t have capacity to build and maintain governance infrastructure
For a practical evaluation framework, Stanford’s HELM benchmarks and EleutherAI’s evaluation harness can help you test model behavior in your specific use case before committing to a production deployment.
What Good Uncensored Deployments Actually Look Like
The organizations getting the most value from uncensored models aren’t the ones using them as drop-in replacements for aligned systems. They’re the ones treating them as a component in a larger, carefully designed system.
A production-ready uncensored AI deployment typically combines:
- Strong system prompts that define operational scope clearly
- Structured output schemas to constrain what the model can produce
- Validation layers that check outputs before they’re acted upon
- Monitoring systems that catch systematic errors and edge cases
- Documented governance policies that define accountability
The model itself is one piece. The infrastructure around it is what makes it trustworthy.
The Bottom Line
The future of AI isn’t going to be fully censored or fully uncensored , it’s going to be layered. Organizations will increasingly combine powerful, flexible models with application-level controls that match their specific risk tolerance and compliance requirements.
The real question isn’t whether uncensored models are good or bad. The real question is: does your organization understand what it’s taking on when it deploys one?
Teams that go in with clear eyes , acknowledging the hallucination risk, building the validation infrastructure, taking governance seriously ,will unlock capabilities that heavily aligned systems genuinely can’t match.
Teams that treat uncensored deployment as an easy shortcut will eventually find out, the hard way, why alignment became important in the first place.