
Meta Description: Installing Ollama and pulling a Qwen model is not the same as having an AI system. Discover what actually separates a language model from a production-ready enterprise AI system in 2026.
Target Keywords: local LLM vs AI system, LLM orchestration enterprise, AI system architecture, local AI enterprise deployment, LLM memory planning tools, agentic AI components, enterprise AI stack 2026, AI orchestration layer, local AI beyond inference, MCP enterprise AI
A language model is one component of an AI system. The real intelligence emerges from what you build around it.
You Pulled the Model. You Do Not Have an AI System Yet.
There is a moment that almost every developer and enterprise team goes through in the same sequence.
They install Ollama. They run ollama pull qwen3:14b. The model loads. They type a question. The answer comes back. It is impressive.
And they think: we have AI now.
They do not.
What they have is an extraordinarily capable text prediction engine running on local hardware. That is genuinely valuable. It is also roughly equivalent to having an engine block sitting on the floor of a garage and concluding that you now have a car.
The engine is the hardest part to build. But without the drivetrain, the wheels, the steering, the fuel system, and the chassis, it goes nowhere.
In 2026, the gap between “we are running a local LLM” and “we have a production AI system” is where most enterprise AI projects either stall or quietly fail. This article explains exactly what fills that gap and what it takes to cross it.
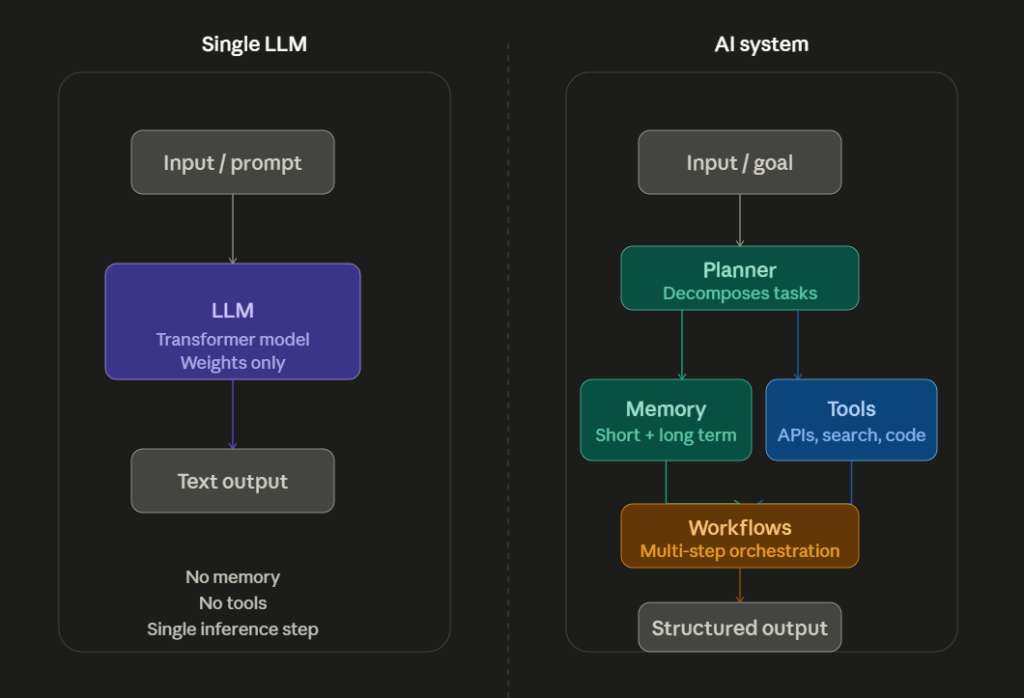
What a Language Model Actually Does
Before talking about what a language model cannot do alone, it helps to be precise about what it actually does.
A large language model trained on text performs one fundamental operation: predict the next token based on the context it receives.
That is it. Everything that makes it impressive, the ability to answer questions, explain concepts, write code, summarize documents, and hold conversations, emerges from doing this prediction extraordinarily well across extremely large context windows.
But notice what is absent from that description:
- It does not remember your conversation from yesterday
- It does not know what happened in your company’s systems this morning
- It cannot query your PostgreSQL database
- It cannot send an email or create a calendar event
- It cannot run Python code and use the result
- It cannot coordinate with another model to verify its own output
- It cannot enforce access controls or produce audit logs
- It cannot stop itself from generating a confident wrong answer
All of these limitations are real and consequential. None of them are solved by choosing a bigger model or a better quantization. They are solved by building a system around the model.
The Seven Components That Turn a Model Into a System
Modern enterprise AI systems are not a single model. They are architectures. Here is what those architectures actually contain.
1. Memory: Continuity Across Time
A raw language model forgets everything the moment a conversation ends. Ask it something today, come back tomorrow, and it has no recollection of who you are or what you discussed.
Enterprise AI requires multiple layers of memory:
Short-term (in-context) memory: What the model can see within its current context window. Qwen 3 14B supports 128K token contexts. Llama 3.3 70B supports similar lengths. This handles what is needed within a single interaction.
Session memory: Conversation history stored and retrieved across multiple turns. LangChain’s ConversationBufferMemory and LlamaIndex’s chat history are standard implementations.
Long-term memory: Persistent storage of facts, preferences, and context that survives across sessions. MemGPT introduced the idea of virtual context management for long-term agent memory. Zep provides production-ready persistent memory for AI applications. LangMem is LangChain’s approach to the same problem.
Semantic memory via vector databases: Storing information as embeddings for semantic retrieval. Chroma, Qdrant, Weaviate, Pinecone, and Milvus are the primary options. This powers RAG (Retrieval-Augmented Generation) pipelines that give models access to organizational knowledge bases.
Without memory, every AI interaction starts from zero. That is fine for simple questions. It is crippling for enterprise workflows that require context continuity.
2. Orchestration: The Conductor of the System
A single model answering a single question is not an enterprise AI system. An enterprise AI system coordinates multiple components: models, databases, APIs, validation steps, routing logic, and error handling. The orchestration layer is what coordinates all of these.
Without an orchestrator, there is no reliable workflow. There is just a model that answers questions.
Key orchestration frameworks:
- LangChain: The most widely used orchestration framework. Provides chains, agents, tool integrations, memory modules, and LangSmith for observability.
- LlamaIndex: Focused on data-connected AI with strong RAG and document retrieval orchestration.
- Haystack: deepset’s pipeline-based orchestration framework optimized for document search and question answering.
- DSPy: Stanford NLP’s framework for programmatic LLM pipelines with automatic prompt optimization.
- Ypipe: A Java-native local AI client and MCP orchestration engine that handles orchestration alongside inference, governance, and enterprise integrations in a single platform. No Python dependency management, no separate orchestration server.
3. Tool Use and MCP Integrations: Connecting to the World
A language model trained on historical text cannot tell you what is in your database right now. It cannot check whether a customer’s order has shipped. It cannot read the log file from last night’s deployment.
Tool use gives the model the ability to act on live, real-world data rather than just generate text about it.
Tool calling (also called function calling) is the mechanism by which models invoke external functions with structured parameters. The Model Context Protocol (MCP) by Anthropic has become the standard interface for defining these integrations.
With MCP, an AI system can connect to:
- Databases: PostgreSQL, MySQL, SQLite, SQL Server, Apache Druid, ClickHouse, MariaDB
- File systems: Local files, Nextcloud, Google Drive, SharePoint
- Communication: Slack, Microsoft Teams, email via SMTP
- Developer tools: GitHub, GitLab, Jira, Linear
- Web: Brave Search, Tavily, Firecrawl for structured web data
- Code execution: Python interpreters, Jupyter kernels, Docker containers
The MCP community server registry catalogs hundreds of available integrations. Ypipe’s Couplings dashboard provides a governed catalog of enterprise MCP integrations with fine-grained tool-level authorization controls.
4. Planning: From Single Answers to Multi-Step Goals
Most real enterprise tasks cannot be completed in a single model response. Filing an expense report, investigating a security incident, generating a competitive analysis, or onboarding a new customer involves multiple steps, multiple data sources, and multiple decision points.
Planning gives AI systems the ability to decompose complex goals into executable steps and work through them systematically.
Key planning approaches:
ReAct (Reason + Act): The foundational framework for combining reasoning and tool use in a loop. The model reasons about what to do, acts, observes the result, and repeats. Most modern agent frameworks build on this pattern.
Chain-of-Thought prompting: Encouraging models to reason step by step before producing a final answer. Improves accuracy on complex tasks significantly.
Tree-of-Thought reasoning: Exploring multiple reasoning paths simultaneously and selecting the best. Useful for problems with multiple valid approaches.
Plan-and-Execute: Separating the planning step (create a list of steps) from the execution step (execute each step in sequence). More reliable for long multi-step workflows than pure ReAct.
Without planning, the model can only respond to what is directly in front of it. With planning, it can pursue goals that span hours of work and dozens of steps.
5. Workflows: Repeatable Enterprise Processes
Many enterprise AI applications are not open-ended conversations. They are structured, repeatable processes: invoice approval, incident response, compliance reporting, customer onboarding, code review.
Workflow systems define these processes explicitly, orchestrate the AI components that handle each step, and integrate with existing enterprise systems. This is the domain of tools like:
- Flowise: Visual no-code AI workflow builder
- LangFlow: Open-source visual pipeline builder for LangChain workflows
- n8n: Workflow automation with native AI integrations
- Zapier AI: Consumer-grade workflow automation with AI steps
- Ypipe: Enterprise workflow orchestration with built-in inference, governed MCP integrations, and audit logging
The key difference between a workflow system and a chatbot is repeatability. A workflow can run the same structured process a thousand times with consistent behavior. A chatbot varies with every conversation.
6. Knowledge Retrieval: Grounding the Model in Organizational Reality
No language model, regardless of size, memorizes your organization’s internal documents, current policies, recent meeting notes, or proprietary research. The training data cutoff means the model does not know about anything that happened after its training ended. And even for things it was trained on, hallucination means it may confidently state incorrect facts.
Retrieval-Augmented Generation (RAG) solves this by retrieving relevant documents at inference time and including them in the model’s context. The model answers based on real organizational information rather than uncertain memory.
A production RAG pipeline requires:
- Document ingestion: Parsing and chunking PDFs, Word documents, Markdown, code files, and web pages using tools like LlamaIndex, Unstructured, or Apache Tika
- Embedding generation: Converting text chunks into vector representations using models like nomic-embed-text or text-embedding-3-small locally via Ollama
- Vector storage: Storing embeddings in Chroma, Qdrant, Weaviate, or Milvus
- Retrieval: Finding semantically relevant chunks at query time
- Reranking: Improving retrieval quality using models like Cohere Rerank or bge-reranker
- Context assembly: Constructing a prompt that includes retrieved information alongside the user’s question
Without RAG, enterprise AI answers from uncertain memory. With RAG, it answers from your actual documents.
7. Governance and Security: The Production Requirement
This is the component that most local AI projects skip and then discover they needed all along.
Running a capable model locally is not the same as running a governed AI system. Governance requires:
Access control: Not every user should access every AI capability. Role-based access control (RBAC) for AI tools and model access is a baseline enterprise requirement.
Audit logging: Every AI interaction in a production system needs to be logged with enough detail to answer audit questions: who, what, when, which model version, which tools were called, what data was accessed. The EU AI Act Article 17 requires technical documentation. ISO 27001 requires information security management evidence.
Data handling: GDPR requires documented data processing purposes. HIPAA requires specific safeguards for health information. PCI DSS restricts payment data processing. Local AI helps with data residency, but governance documentation is still required.
Human oversight: EU AI Act Article 14 requires meaningful human oversight for high-risk AI applications. This means defined escalation paths, review checkpoints, and documentation that oversight occurred.
Prompt injection protection: OWASP’s LLM Top 10 identifies prompt injection as the top risk for LLM applications. Production systems need defense layers beyond trusting model outputs.
None of these requirements are satisfied by running Ollama with Open WebUI. They require deliberate architecture decisions and dedicated infrastructure.
For the full governance picture, read our guide on why local AI does not automatically make you EU AI Act compliant.
What the Full Architecture Actually Looks Like
A production enterprise AI system is not a model with a chat interface. It is a layered architecture where the model is one component among many.
User / Application
|
v
Authentication + Access Control
|
v
Orchestration Layer (LangChain / LlamaIndex / Ypipe)
|
|---- Memory System (short-term + long-term + vector DB)
|
|---- Planning Engine (ReAct / Plan-and-Execute)
|
|---- Tool Registry (MCP integrations, APIs, databases)
|
|---- RAG Pipeline (document retrieval + reranking)
|
|---- Validation + Reflection (output verification)
|
v
Language Model (reasoning engine)
|
v
Audit Logging + Compliance Layer
|
v
Final Response
Notice where the language model sits: in the middle of this stack, not at the top. It is the reasoning engine. The system is everything around it.
Why Local AI Specifically Needs This Layer
Running AI on local hardware solves the data sovereignty problem. Data stays on your infrastructure, your costs are predictable, and you are not dependent on a cloud provider whose access can be suspended overnight, as the Fable 5 situation demonstrated.
But local AI without the surrounding system layer is just local inference. The sovereignty benefits are real. The capability ceiling without orchestration is low.
The good news is that the full stack can run entirely locally:
- Vector database: Chroma or Qdrant run locally with no external dependency
- Embedding model: nomic-embed-text via Ollama runs entirely local
- Orchestration: LangChain, LlamaIndex, or Ypipe run on your own hardware
- MCP integrations: Model Context Protocol servers run locally alongside your existing enterprise systems
- Inference: Ollama, vLLM, llama.cpp, or Ypipe’s built-in inference
The entire AI system, from user interface to model output, can run on infrastructure you own and control.
Ypipe: From Local Model to Local AI System
Ypipe by iunera is designed for exactly this transition: from running a local model to having a production-ready local AI system.
Where a standalone inference runtime like Ollama provides model serving, Ypipe provides the full system layer:
Built-in inference with no external dependencies. No Ollama or vLLM required. Ypipe ships with self-contained inference optimized for Apple Silicon, NVIDIA CUDA, and Vulkan. Direct GGUF model import from Hugging Face.
MCP orchestration as a first-class feature. The Couplings dashboard provides a governed catalog of enterprise MCP integrations: Apache Druid, PostgreSQL, MySQL, SQL Server, ClickHouse, SQLite, Nextcloud, LibreOffice, and local file systems. Fine-grained control over which tools AI agents can access.
Agentic Gearbox for intelligent model routing. Tasks are routed to appropriately sized models: lightweight Falcon H1 for fast classification, mid-size Qwen 3 14B for analysis, larger models for complex synthesis. See our breakdown of how small specialist models like Falcon H1 fit into multi-model agentic workflows.
Audit infrastructure for compliance. Every AI interaction logged with model version, tool calls, parameters, and results. Headless deployment mode for enterprise-scale audit logging. EU AI Act, NIS2, DORA, and ISO 27001 compliance infrastructure built in.
Java-native stability. No Python dependency hell. Fits into existing enterprise DevOps pipelines. OpenAI API compatibility for existing toolchains. Kubernetes support for enterprise scale.
Total data sovereignty. Every prompt, context window, and response stays on organizational hardware. No cloud routing. No telemetry. If the internet disappears, Ypipe keeps running.
Start in seconds with JBang:
jbang ypipe@iunera/ypipe
Platform installers for Windows, macOS, and Linux at ypipe.com.
Where to Start: A Practical Path to Production
If your organization is at “we are running Ollama” and needs to get to “we have a production AI system,” here is a realistic sequence:
Step 1: Add an orchestration layer
LangChain or LlamaIndex for Python teams. Ypipe for Java enterprise environments or teams that want inference and orchestration in one platform.
Step 2: Add knowledge retrieval
Set up Chroma or Qdrant locally. Ingest your most-used internal documents. Connect to your orchestration layer. Your AI now answers from your data, not just its training.
Step 3: Add tool integrations via MCP
Connect the AI to the systems it needs to interact with. Start with your most-used database and a file system integration. Use MCP servers for standardized integrations. See our guide on top 20 tools to run LLMs locally in 2026 for infrastructure options.
Step 4: Define workflows for your highest-value use cases
Pick two or three repeatable enterprise processes where AI could save significant time. Define them explicitly as workflows rather than open-ended conversations.
Step 5: Add governance before scaling
Implement audit logging, access controls, and human oversight checkpoints before rolling out to more users or higher-stakes workflows. This is far cheaper to build in early than to retrofit later. Read our guide on the hidden governance gap in local AI.
Conclusion: The Model Is the Starting Point, Not the Destination
Running a local LLM is an impressive achievement and a genuine first step. The models available in 2026 are remarkable. Qwen 3 32B running locally competes seriously with frontier cloud models on most enterprise tasks. Llama 3.3 70B on a capable server delivers output that would have required expensive cloud APIs two years ago.
But the model is the engine. The system is everything else.
Memory gives the engine continuity. Orchestration gives it coordination. Tool use gives it reach. Planning gives it purpose. Workflows give it repeatability. Knowledge retrieval gives it accuracy. Governance gives it accountability.
The question that separates organizations that extract durable value from AI from those that are perpetually impressed but perpetually disappointed is not “which model should we run?”
It is:
What system are we building around the model?
That is the question worth answering in 2026.
Frequently Asked Questions
What is the difference between a local LLM and an AI system?
A local LLM is an inference runtime serving a model that generates text responses. An AI system combines that model with memory, orchestration, tool use, planning, knowledge retrieval, and governance to perform real enterprise workflows. Tools like LangChain, LlamaIndex, and Ypipe provide the surrounding system architecture.
Why is RAG necessary for enterprise AI?
RAG (Retrieval-Augmented Generation) grounds model responses in real organizational documents rather than uncertain training data. Without RAG, the model answers from memory that may be outdated, incorrect, or irrelevant to your specific organization. With RAG, it answers from your actual policies, documentation, and knowledge bases.
What is MCP and why does it matter for AI systems?
The Model Context Protocol is an open standard by Anthropic that defines how AI systems connect to external tools and data sources. It standardizes tool integration across databases, file systems, APIs, and enterprise systems. Ypipe uses MCP as its primary integration mechanism, providing a governed catalog of enterprise connections.
Do I need Python to build a local AI system?
Most AI orchestration frameworks (LangChain, LlamaIndex, AutoGen) are Python-based. Ypipe is a Java-native alternative that provides orchestration, inference, MCP integrations, and governance in a single platform without Python dependency management. Semantic Kernel also supports .NET and Java.
What governance requirements apply to enterprise AI systems?
Key frameworks include EU AI Act for AI governance and transparency, GDPR for data processing, NIS2 for security documentation, DORA for financial entities, and ISO 27001 for information security management. All require audit logging, access controls, and human oversight documentation that inference runtimes alone do not provide.
How does Ypipe compare to just using Ollama with LangChain?
Ollama plus LangChain provides inference and basic orchestration. Ypipe adds governed MCP enterprise integrations, built-in audit logging for compliance, role-based model routing via the Agentic Gearbox, Java-native stability without Python dependencies, and total data sovereignty with no external runtime dependencies. For personal projects, Ollama plus LangChain is fine. For regulated enterprise deployments, Ypipe addresses the governance gap directly.
From local model to production AI system: Ypipe | Developed by iunera