
Meta Description: Can Gemma 12B Coder running locally compete with frontier AI like Fable 5? We compare coding quality, privacy, enterprise deployment, governance, and total cost of ownership honestly.
Target Keywords: Gemma 12B Coder vs Fable 5, local AI coding model 2026, Gemma 12B enterprise, best local coding LLM, Fable 5 alternative local, open source coding model, local AI vs cloud AI coding, Gemma coder deployment, self-hosted AI coding assistant, enterprise coding AI comparison
The Gap Is Closing. Faster Than Most People Realize.
Two years ago, this comparison would have been almost unfair to write.
Frontier cloud AI models like Fable 5 operated at a capability level that locally deployable models simply could not reach. If you wanted serious AI-assisted coding, you sent your code to the cloud. That was the deal.
In 2026, that deal is worth renegotiating.
Google’s Gemma 12B Coder is part of a generation of open-weight models that have closed the gap with frontier AI on specific, well-defined tasks to a degree that would have seemed implausible even 18 months ago. Not on every dimension. Not in every context. But on the coding tasks that most developers actually do every day, the performance delta is smaller than most organizations assume.
More importantly, the comparison between Gemma 12B Coder and Fable 5 is not really a benchmarking exercise. It is a strategic decision about what enterprise AI infrastructure should look like, who should control it, and what happens when a frontier model gets suspended overnight.
If you missed that last point, read our piece on why the Fable 5 restrictions are a wake-up call for local AI.
Why This Comparison Actually Matters
Fable 5 represents a specific philosophy: managed, continuously updated, frontier AI delivered as a service. The infrastructure is handled. The updates are automatic. The capability ceiling is high. You just pay and use.
Gemma 12B Coder represents a different philosophy: open-weight, locally deployable, organizationally owned AI. You own the weights. You control the deployment. You decide when to update. The cloud cannot suspend your access.
For many development teams, the question of which produces slightly better code on a given benchmark is less important than the question of which deployment model they can actually build reliable engineering infrastructure on top of.
Both philosophies have legitimate strengths. The honest comparison covers both.
Architecture and Deployment Philosophy
Fable 5
Fable 5 is a frontier model accessed via Anthropic’s API. Like all cloud-hosted frontier models, it runs on Anthropic’s infrastructure, receives continuous updates, and is governed by Anthropic’s policies, pricing, and availability decisions.
The recent export-control suspension demonstrated that availability is not entirely within the customer’s control. Organizations that experienced that disruption learned, sometimes expensively, what operational dependency on a cloud AI actually means in practice.
Gemma 12B Coder
Gemma 12B Coder is part of Google’s Gemma 3 family, released under the Gemma license that permits research and commercial use. The model weights are available on Hugging Face and can be deployed on your own hardware using Ollama, LM Studio, vLLM, llama.cpp, or enterprise orchestration platforms like Ypipe.
At 12 billion parameters, Gemma 12B Coder runs comfortably on hardware with 16 to 24GB of VRAM, or on Apple Silicon machines from the M2 Pro generation onward. It is a serious model that serious development teams can deploy on real enterprise hardware.
Honest Coding Performance Comparison
Rather than cherry-picked demos, here is how the two models compare across the coding task categories that enterprise developers actually encounter:
Code Generation From Natural Language
| Task | Fable 5 | Gemma 12B Coder |
|---|---|---|
| Simple function generation | Excellent | Excellent |
| Multi-file feature implementation | Excellent | Good |
| API integration boilerplate | Excellent | Very Good |
| Algorithm implementation | Excellent | Good |
| Test generation | Excellent | Very Good |
| SQL query generation | Excellent | Very Good |
On routine code generation tasks, the gap is smaller than most people expect. Gemma 12B Coder performs strongly on the majority of tasks that fill a typical development day. Where frontier models pull ahead meaningfully is on complex multi-file implementations and abstract algorithm design that requires sustained reasoning over long contexts.
Bug Detection and Fixing
Gemma 12B Coder performs well on common bug patterns: null pointer exceptions, off-by-one errors, SQL injection vulnerabilities, incorrect async/await handling, and type mismatches. On the HumanEval and MBPP benchmarks, the 12B parameter class of Gemma models scores competitively with GPT-3.5-level performance.
Where frontier models like Fable 5 maintain a meaningful advantage is on subtle architectural bugs, complex concurrency issues, and deeply nested logic errors in large codebases where reasoning over extensive context is required.
Code Explanation and Documentation
This is one of Gemma 12B Coder’s strongest categories. Explaining what code does, generating JSDoc, Sphinx, or Javadoc comments, and creating README documentation from codebases are tasks where the model performs at a level that satisfies enterprise production requirements. The gap with frontier models on these tasks is minimal for most teams.
Refactoring and Code Quality
Both models handle common refactoring patterns well: extracting functions, renaming for clarity, applying SOLID principles, converting imperative to functional style, and modernizing deprecated patterns. Gemma 12B Coder handles these confidently for well-scoped tasks. On large-scale architectural refactoring across dozens of files, frontier models have the edge.
Language and Framework Coverage
Gemma 12B Coder covers all major languages effectively: Python, JavaScript/TypeScript, Java, Go, Rust, C++, SQL, Bash, and YAML/JSON configuration. Framework knowledge covers React, Spring Boot, FastAPI, Django, Next.js, and Kubernetes manifests with solid competence.
The Dimensions That Benchmarks Do Not Capture
Raw coding performance is only one dimension of this comparison. For enterprise deployments, several other factors often matter more.
Data Privacy and Code Sovereignty
Every line of code, every internal API specification, every proprietary algorithm, and every security-sensitive configuration you send to a cloud AI becomes data that traverses external infrastructure.
Anthropic’s privacy policy describes how data is handled, but no policy eliminates the fundamental fact that proprietary source code leaves organizational control. For organizations under GDPR, HIPAA, SOX, PCI DSS, or defense-related regulations like CMMC and ITAR, sending source code through external APIs is a compliance conversation, not just a preference.
Gemma 12B Coder deployed locally means your code never leaves your machine. Period.
Latency for Real Developer Workflows
Cloud AI introduces network round-trips. On high-speed connections, this is measured in milliseconds. In enterprise environments with VPNs, proxy servers, and network security appliances, it can be measured in seconds. For interactive coding assistance where a developer is waiting for a response, local inference on capable hardware is often faster in practice than a cloud API call.
On an Apple M3 Max or NVIDIA RTX 4090, Gemma 12B with GGUF Q4 quantization generates at 40 to 80 tokens per second, which is faster than most developers read.
Total Cost of Ownership
Cloud AI costs are per-token and variable. A development team of 20 engineers using AI coding assistance extensively can generate substantial monthly API bills. OpenAI’s API pricing, Anthropic’s pricing, and Google’s Gemini pricing are all denominated per million tokens, and active development workflows generate millions of tokens quickly.
Local deployment has upfront infrastructure costs and ongoing operational overhead. But the marginal cost of additional inference is zero. For high-volume development teams, the break-even calculation often favors local deployment within months.
Customization and Fine-Tuning
You cannot fine-tune Fable 5 on your internal codebase, your proprietary frameworks, or your organization-specific coding standards. Whatever behavior the model has is the behavior you get.
Gemma 12B Coder can be fine-tuned using LoRA or QLoRA on your own repositories. A model that has been trained on your internal libraries, your API contracts, your naming conventions, and your architectural patterns will outperform a generic frontier model on your specific codebase. Tools like Unsloth, Axolotl, and LLaMA-Factory make this accessible without a dedicated ML team.
Operational Resilience and Availability
The Fable 5 suspension demonstrated what happens when a cloud AI becomes unavailable. Your development team’s AI assistance disappears. Workflows break. Pipelines fail.
Local deployment means your coding assistant is available regardless of what happens at a cloud provider, what government directive arrives, what pricing decision is made, or what internet connectivity looks like. For engineering teams that have integrated AI deeply into their development workflow, this resilience is not theoretical. It is a business continuity requirement.
Developer Tooling Integration
Using Gemma 12B Coder With Existing Tools
Gemma 12B Coder integrates with the full ecosystem of local AI developer tools:
Continue.dev: Connect Gemma 12B as the backend for VS Code or JetBrains AI coding assistance. Full local inference, no code leaving the machine. The Continue documentation covers Ollama and LM Studio backend configuration.
Aider: Use Gemma 12B through Ollama for terminal-based git-aware coding assistance. The Aider leaderboard tracks coding performance across model sizes.
Cursor: Configure a local Ollama endpoint serving Gemma 12B as a custom model backend in Cursor’s settings.
LM Studio: Download Gemma 12B GGUF directly and run the local server for any OpenAI API-compatible coding tool.
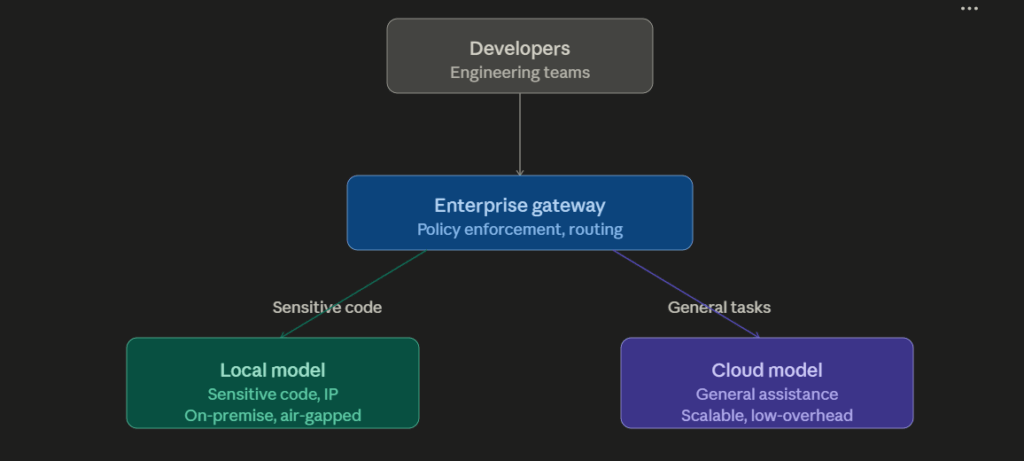
Ypipe: For enterprise teams needing more than personal coding assistance, Ypipe by iunera provides the orchestration layer that makes Gemma 12B Coder enterprise-ready. Governed MCP integrations connect the model to internal databases, code repositories, and enterprise systems. Audit logging satisfies EU AI Act and ISO 27001 requirements. Role-based model routing allows teams to use Gemma 12B for standard coding tasks while routing complex architectural queries to larger reasoning models like Qwen 3 32B.
Read our guide on the hidden governance gap in local AI to understand why enterprise coding AI needs more than just an inference runtime.
Hardware Requirements for Running Gemma 12B Coder Locally
| Hardware | Performance | Suitable For |
|---|---|---|
| Apple M2 Pro / M3 (18GB+) | Good | Individual developer use |
| Apple M3 Max / M4 Max (36GB+) | Excellent | Power users and small teams |
| NVIDIA RTX 4080 (16GB VRAM) | Very Good | Developer workstations |
| NVIDIA RTX 4090 (24GB VRAM) | Excellent | Team servers |
| NVIDIA A10G (24GB VRAM) | Excellent | Cloud / on-premise enterprise |
| CPU only (32GB+ RAM) | Acceptable | Lightweight or overnight batch tasks |
For GGUF quantized versions from bartowski or LoneStriker, Q4_K_M quantization offers the best balance of quality and memory efficiency. Available via Ollama with ollama pull gemma3:12b.
The Hybrid Architecture Most Enterprises Will Adopt
The strongest AI coding strategy for most enterprises in 2026 is not choosing between Gemma 12B Coder and Fable 5. It is knowing when to use each.
Use Gemma 12B Coder locally for:
- Any code involving proprietary algorithms, internal APIs, or sensitive business logic
- Regulated environments where code cannot leave organizational infrastructure
- High-volume tasks where per-token cloud costs add up: documentation generation, test writing, boilerplate
- Air-gapped or high-security environments
- Fine-tuned workflows specialized on your internal codebase
Use frontier cloud AI for:
- Exploratory prototyping with no sensitive IP involved
- Complex architectural questions that benefit from frontier reasoning capability
- Tasks where the performance gap justifies the privacy trade-off on non-sensitive code
- Teams without the infrastructure budget or operational capacity for local deployment
Ypipe’s OpenAI API compatibility makes this hybrid approach straightforward: point sensitive workflows at the local Ypipe endpoint, point non-sensitive workflows at cloud providers, and manage both through a unified orchestration layer.
Conclusion: Close Enough to Matter, Different Enough to Choose Deliberately
Gemma 12B Coder will not match Fable 5 on every coding task. That is an honest statement. On complex multi-file implementations and deep architectural reasoning, frontier models maintain real advantages.
But on the majority of coding tasks that fill a real development team’s day, the gap is smaller than the marketing implies and the trade-offs clearly favor local deployment for any organization that takes data privacy, operational resilience, and AI governance seriously.
The Fable 5 suspension made the cost of cloud AI dependency concrete for many organizations. The question is no longer whether local AI is viable for enterprise coding workflows. It demonstrably is.
The question is whether your organization is going to treat AI infrastructure with the same strategic seriousness it brings to databases, version control, and CI/CD pipelines, or whether it is going to keep renting capability it cannot fully control.
Frequently Asked Questions
Is Gemma 12B Coder good enough for production enterprise use?
Yes, for the majority of enterprise coding tasks. Gemma 12B Coder performs at a level competitive with GPT-3.5 on coding benchmarks like HumanEval and MBPP, handles all major languages and frameworks confidently, and integrates with tools like Continue.dev and Aider. For highly complex multi-file reasoning, larger models provide better results.
How do I run Gemma 12B Coder locally?
The fastest path is Ollama: run ollama pull gemma3:12b. For a GUI, LM Studio supports direct Hugging Face download. For enterprise deployment with governance, Ypipe provides self-contained inference with MCP orchestration. See our guide on top 20 tools to run LLMs locally in 2026 for a full comparison.
What hardware do I need to run Gemma 12B locally?
Minimum practical setup is 16GB of VRAM (NVIDIA RTX 4080 or equivalent) or an Apple Silicon Mac with 18GB unified memory. For production team servers, a 24GB VRAM GPU provides comfortable inference at full quality.
Can I fine-tune Gemma 12B on my own codebase?
Yes. LoRA and QLoRA fine-tuning are well supported for Gemma models. Tools like Unsloth and Axolotl make this accessible. A model fine-tuned on your internal repositories, APIs, and conventions will outperform a generic frontier model on your specific codebase.
What is the difference between Gemma 12B and Gemma 3 12B?
Gemma 3 is Google’s third generation of the Gemma family, released in 2025. It includes significant improvements in instruction following, coding performance, and multilingual capability over earlier Gemma generations. When running Gemma for coding tasks, always use the Gemma 3 generation.
How does Ypipe help with enterprise Gemma 12B deployment?
Ypipe provides the governance and orchestration layer that makes Gemma 12B Coder enterprise-ready beyond personal use: audit logging for EU AI Act compliance, governed MCP integrations to enterprise databases and systems, role-based model routing, and a Java-native architecture that fits existing enterprise infrastructure. Read our guide on why local AI does not automatically make you EU AI Act compliant for the full governance picture.
Enterprise local AI with governance built in: Ypipe | Developed by iunera