

Enterprise AI Integration & Custom MCP (Model Context Protocol) Server Development Building Your Enterprise AI Future […]

Revolutionize enterprise AI with agentic RAGs. This guide explores a 15-step pipeline and offers insights for enterprise AI implementation.
Explore a scalable polyglot data ingestion framework for AI-driven search ecosystems, supporting vector, SQL, and graph indexing. A flowchart details 6 steps for preprocessing and embedding, enabling robust RAG search.

An in-depth analysis of the intricate challenges of vector-only Retrieval-Augmented Generation (RAG) pipelines, spotlighting these issues […]
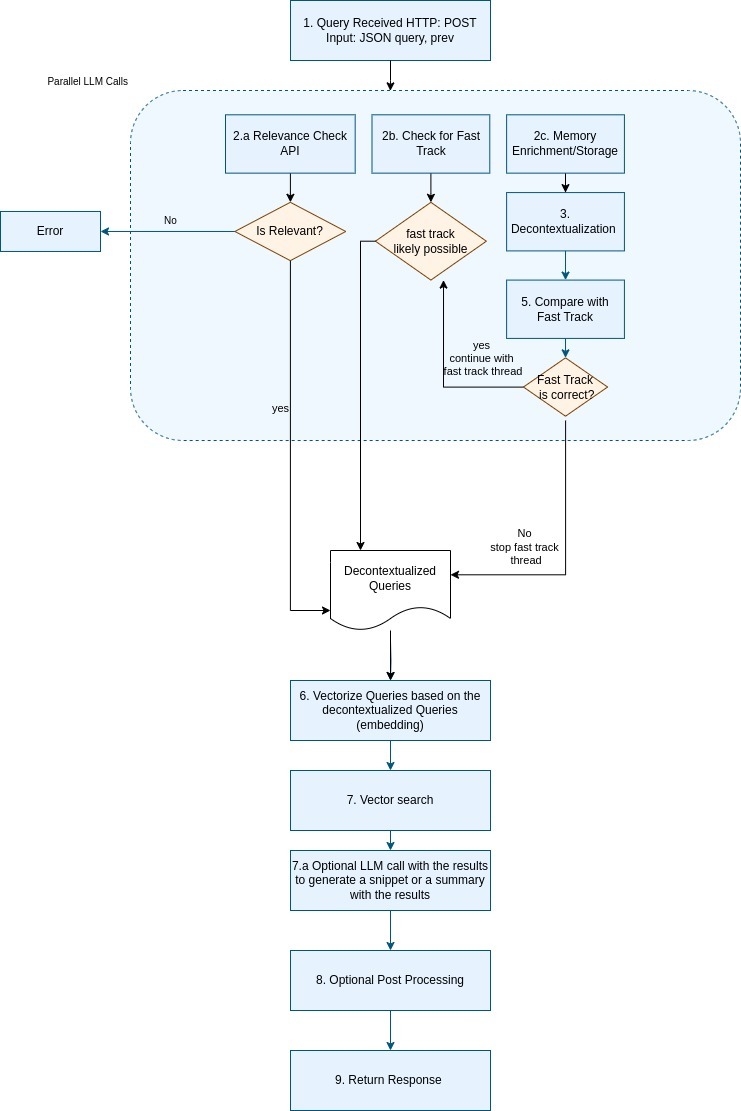
Explore the NLWeb search prototype’s query processing pipeline in this detailed NLWeb example, showcasing how it handles "Find vegetarian recipes for Diwali" with prior context. Learn from flowcharts and insights drawn from the NLWeb GitHub repository, illustrating the system’s use of AI, Schema.org, and vector search to deliver precise results.

Learn how JSON-LD and Schema.org enhance RAG and NLWeb with structured data. Discover howto use markdown for AI training data, boosting SEO, and creating a digital AI twin.

Discover how to expose enterprise data for AI indexing with Java and Spring using the jsonld-schemaorg-javatypes library for NLWeb. Learn to leverage Schema.org, JSON-LD, and OrientDB for semantic search, knowledge graphs, and interoperability, with sustainable Fair Code licensing.

The software industry confronts a defining moment. Open Source Software, as delineated by the Open Source Initiative (OSI), has long been a cornerstone of technological advancement, enabling collaborative triumphs like the Linux kernel. Yet, its open-access ethos harbors a persistent flaw: exploitation. Can we stop it?
Analysis and predictions of occupancy in public transport are essential in order to use vehicles intelligently […]
Business capabilities and opportunities result from these Big Data Landscape maturity levels of an enterprise. We describe what they are and how they matter.