
This post is the summary of a series on Apache Druid Query Performance.
- Apache Druid Query Performance Bottlenecks: A Q&A Guide
- The Foundations of Apache Druid Performance Tuning: Data & Segments
- Apache Druid Advanced Data Modeling for Peak Performance
- Writing Performant Apache Druid Queries
- Apache Druid Cluster Tuning & Resource Management
- Apache Druid Query Performance Bottlenecks: Series Summary (You are here)
Optimizing Apache Druid query performance is a systematic process that begins with the data itself and extends through query construction to cluster resource management. The most common and severe bottlenecks can be traced back to a violation of Druid’s core design principles, and resolving them requires a hierarchical approach.
A Summary of the Performance Tuning Hierarchy
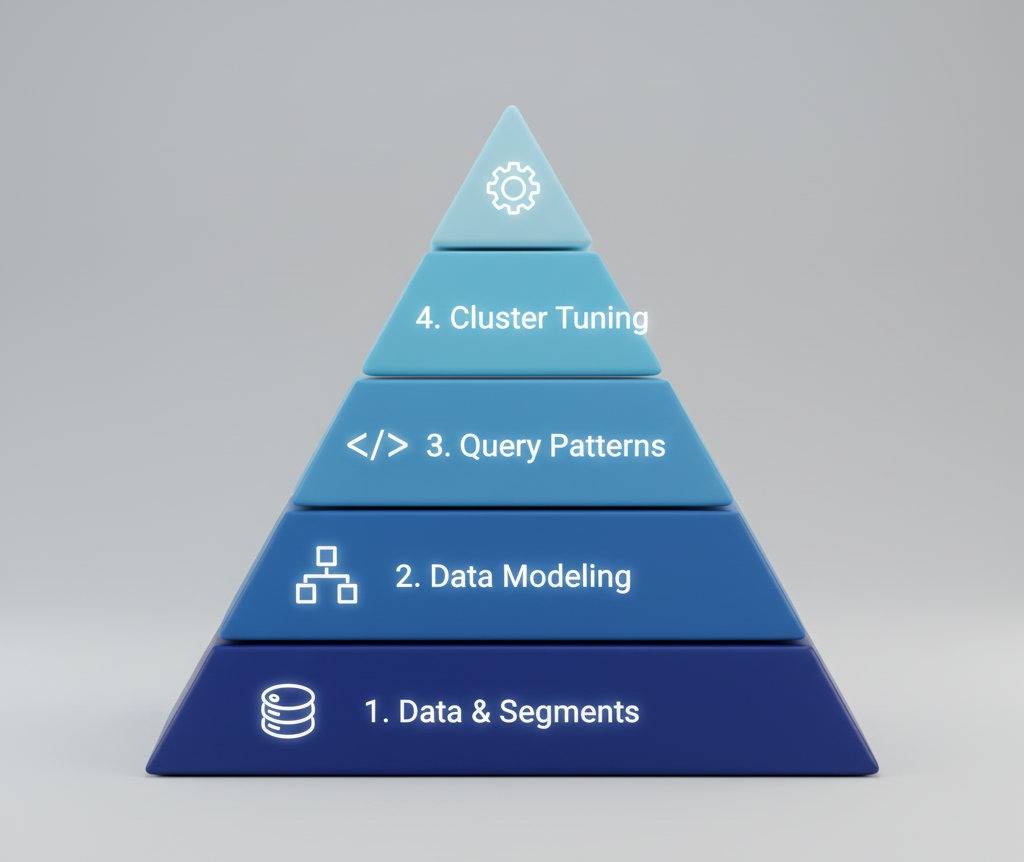
Throughout this series, we’ve explored the systematic process of optimizing Druid. Here are the key takeaways from each stage:
- Part 1: Data & Segments: We established that the most critical optimizations begin with the physical layout of data. Aggressive, automated compaction to create optimally-sized segments (around 5 million rows) is non-negotiable for preventing the massive overhead that comes from segment proliferation.
- Part 2: Data Modeling: We delved into schema design, emphasizing the power of rollup to pre-aggregate data at ingestion. We also covered partitioning strategies to improve data locality and the use of sketch aggregators to handle high-cardinality dimensions without crippling
GROUP BYperformance. - Part 3: Query Patterns: We learned to write queries that align with Druid’s strengths, such as always filtering on
__time, preferringTopNoverGroupByfor ranked lists, and usingEXPLAIN PLANto ensure the query engine is executing the plan you expect. - Part 4: Cluster Tuning: Finally, we covered the resource management layer, discussing how to correctly size JVM heap vs. direct memory and configure processing threads to maximize CPU utilization. For mixed workloads, we explored using Query Laning and Tiering to isolate resources and guarantee performance for high-priority applications.
Tuning is not a one-time event but an iterative, metric-driven process. By using the diagnostic tools and metrics discussed to identify bottlenecks, making targeted changes, and measuring the impact, you can methodically enhance the performance and stability of your Druid cluster. For teams deploying on Kubernetes, our guide on deploying Druid on Kubernetes provides further insights into modern deployment strategies.
For organizations seeking to accelerate their real-time analytics initiatives, Iunera offers specialized Apache Druid consulting services, from performance health checks and architecture reviews to hands-on implementation and support. As the operational complexity of Druid can be a bottleneck, we are also pioneering new ways to interact with the database. Our open-source Druid MCP Server leverages Large Language Models (LLMs) to create a conversational bridge to Druid’s powerful engine, translating natural language into complex data workflows. You can explore the project on our GitHub repository.
Visit our page on Apache Druid AI Consulting to learn how we can help you build and maintain a world-class Druid platform.