
Due to the growing demand for real-time data processing, traditional (on-disk) database management systems are under extreme pressure to enhance performance. With the growing amount of data, which is anticipated to reach 40ZB (1ZB = 1 billion terabytes) by 2025, or 5,247 GB of data per person[!], on top of using traditional DBMS design, processing the data producing analytical findings in the near real-time is becoming increasingly difficult.
In case you didn’t know about in-memory databases, this article will help you to understand what in-memory type databases are and how they work.
Introduction to In-Memory Database
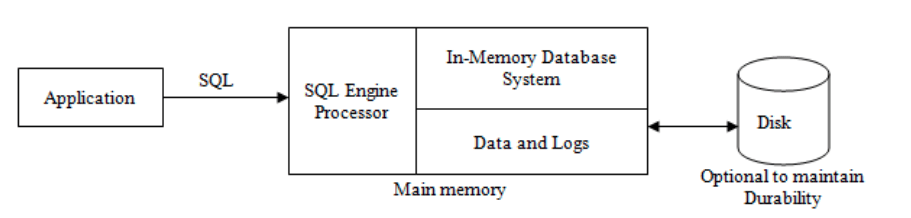
An in-memory database is a database that keeps the whole dataset in RAM, in contrast to traditional databases which are stored on disk drives. This means that only the main memory can be accessed every time a query or update of the database is made. As a result, no disk I/O is involved, leading to much faster main memory than any disk.
FACT
The working memory is also called RAM and contains all programs, program parts, and any data required for running these programs.
An in-memory database can store relational data, document data, key-value data, or even a hybrid database structure comprising of many different structures.
How Does it Actually Work?
In-memory database work by keeping all data in RAM in a server or a machine with large amounts of RAM.

To protect against data loss, most in-memory databases also store data in many different computers.
Another good use of an in-memory type database is a real-time embedded system. IMDSs running on real-time operating systems (RTOSs) enable the responsiveness required in IP network routing, telecom switching, and industrial control applications. In MP3 players, IMDSs manage music databases and in set-top boxes, IMDSs controls the programme data.
In some database applications, In-memory databases can also perform compression, so they store more in the memory for the trade-off of having to use more CPU but being able to use the memory more efficiently. This makes sense since the CPU is still faster than the disk.
In-memory also enables column views very well which makes them well suited for analytics investigations with data warehouse techniques where you roll across or pivot the data. Hence, when it comes to data warehouse analytics and data manipulation, in-memory could be a good system to use.
What Happens During a System Crash?
The majority of in-memory database systems have features for adding persistence, or the ability to withstand a hardware or software environment disturbance.
One critical tool is transaction logging, which involves writing periodic snapshots of the in-memory database (referred to as “savepoints”) to non-volatile media.
Durability can also be added to in-memory database systems by retaining one or more copies of the database. Fail-over processes enable the system to continue using a standby database under this method, dubbed database replication for high availability.
Multiple processes or threads inside the same hardware instance can maintain the “master” and “replica” databases. Additionally, they can be housed on two or more boards in a chassis connected through a high-speed bus, run on separate computers connected via a LAN, or exist in other configurations.
Comparison of Disk vs In-Memory
Let us first understand the differences between an on-disk database and an in-memory database. Below are some basic differences between the 2 of them.
On Disk

- All data is stored on disk potentially causing some bottlenecks
- Data is always persisted to disk
- Traditional data structures like B-Trees designed to store tables and indices efficiently on disk
In-Memory
- All data stored in the main memory of the server
- Data is persistent or volatile depending on the in-memory database product.
- Specialized data structures and index structures assume data is always in the main memory.
- In the event of a failure, the stored database can be accessed.
To summarise the differences, an in-memory database system eliminates the need for file I/O. Its design can be simplified from the start, with the purpose of decreasing memory use and CPU cycles. Though the cost of memory has decreased, developers properly regard it as more valuable—and because memory equals storage capacity for an in-memory database system, IMDSs should be built to maximise memory use.
Because an in-memory database is expressly chosen for performance reasons, a secondary design goal is always to avoid wasting CPU cycles.
In-Memory Database Systems and Technologies

The main concept of an in-memory database system refers to a database system that has been designed to take advantage of larger memory capacities available on modern database systems. Let us take a look at some of the technologies that an in-memory database can offer. (This is taken from Microsoft NoSQL)
- Hybrid Buffer Pool enables readings of database files on persistent memory (PMEM) devices. The hybrid buffer loads and stores operations against memory-mapped files to leverage the PMEM device as a cache for the buffer pool and database files storage.
- In-Memory OLTP can significantly improve the performance of transaction processing, data ingestion, data load and transient data scenarios.
- Persistent Log Buffers, also known as the tail of log caching, uses persistent memory for the database log buffer, eliminating possible bottlenecks on busy systems waiting for the log buffer to flush to disk.
Challenges of an In-Memory Database
Despite its promising performance characteristics, IMDS have significant limitations when compared to standard on-disk databases. While robust classical database systems, by virtue of their construction on hard disc, ensure the transactions are atomic, consistent, isolated, and durable (ACID). Due to their RAM-based construction, IMDSs face numerous hurdles in terms of ensuring their durability.
Let us take a look at how the these challenges are faced:
Transactional Logging
Each transaction will be logged to a persistent store, allowing the roll-forward method to restore the database in the event of a power failure. To avoid making transaction logging the bottleneck for overall performance, different design strategies include first writing the logs to stable memory (which is faster than writing to disc) and then to disc in asynchronous processes, so that the main database operations do not have to wait for the logging to complete.
Persistent Power
Recent advancements in the main memory area, such as NVRAM (NonVolatile RAM) or battery-powered main memory, offer a scenario in which data in the main memory is never destroyed.
High Availability Design and Implementation
Implementing high availability is another design strategy for resolving this issue. High availability refers to the process of duplicating data in real-time to other access nodes. This enables the creation of data duplicates in near real-time, reducing the likelihood of full data failure. If one of the nodes fails, another will take over and handle the request.
Common Use Cases
Online Bidding
Online bidding refers to the buying and selling of a product during bidding. During this time period, real-time bidding applications request bids from all buyers for the ad spot, select a winning bid based on multiple criteria, display the bid, and collect post-ad-display information. In-memory databases are ideal choices for ingesting, processing as well as analysing this data at a very high speed.
Caching
A cache is a rapid data storage layer that maintains a portion of data that is often temporary in nature in order to serve subsequent requests for that data as quickly as feasible. The fundamental objective of a cache is to improve data retrieval performance by eliminating the need to contact the slower storage layer beneath.
Examples of In-Memory Database
H2 Database
H2 is an open-source database written in Java that supports standard SQL for both embedded and standalone databases. It is swift and contained within a JAR of only around 1.5 MB. It supports inner and outer joins, subqueries, read-only views and inline views. Contains built-in functions, including XML and lossless data compression. Supports compatibility modes for IBM DB2, Apache Derby, HSQLDB, MS SQL Server, MySQL, Oracle, and PostgreSQL.
HSQLDB (Hyper-SQL Database)
HSQLDB is an open-source project, also written in Java, representing a relational database. It follows the SQL and JDBC standards and supports SQL features like stored procedures and triggers. It can be used in the in-memory mode, or it can be configured to use disk storage.
SAP HANA
The SAP HANA (high-performance analytic appliance) in-memory database is a combination of hardware and software. Unlike other in-memory databases, SAP HANA doesn’t store data temporarily, but instead stores it on the working memory permanently, and saves the data using transaction logs. It states to offer support for complex queries and high performance for complex queries.
MongoDB
There has been an increase in interest in utilizing MongoDB as an in-memory database, which means that no data is kept on disc. MongoDB makes an excellent design choice by utilising memory-mapped files to manage access to data files on the disc. This means that MongoDB is unaware of the distinction between RAM and disc; it simply accesses bytes at offsets in massive arrays representing files, and the OS handles the rest! This architectural choice enables MongoDB to run natively in RAM.
Keeping in mind
In-memory databases have established themselves as a successful form of technology for storing and processing data. In-memory database work by keeping all data in RAM in a server or a machine with large amounts of RAM.
In the actual production environment, they enable companies and organisations to handle large amounts of data to analyze big data as quickly as possible and access it at any time.
When it comes to processing vast volumes of data quickly and efficiently, an in-memory database appears to be the ultimate solution and a watershed moment in design techniques.
They provide numerous benefits, and it is only a matter of time before we see numerous new inventions to overcome their current shortcomings or restrictions.
If all of the world’s knowledge can be processed and utilised at fast speeds, it will result in a decisive revolution in a variety of high-tech disciplines, including Artificial Intelligence, various forecasting services, and so on.