
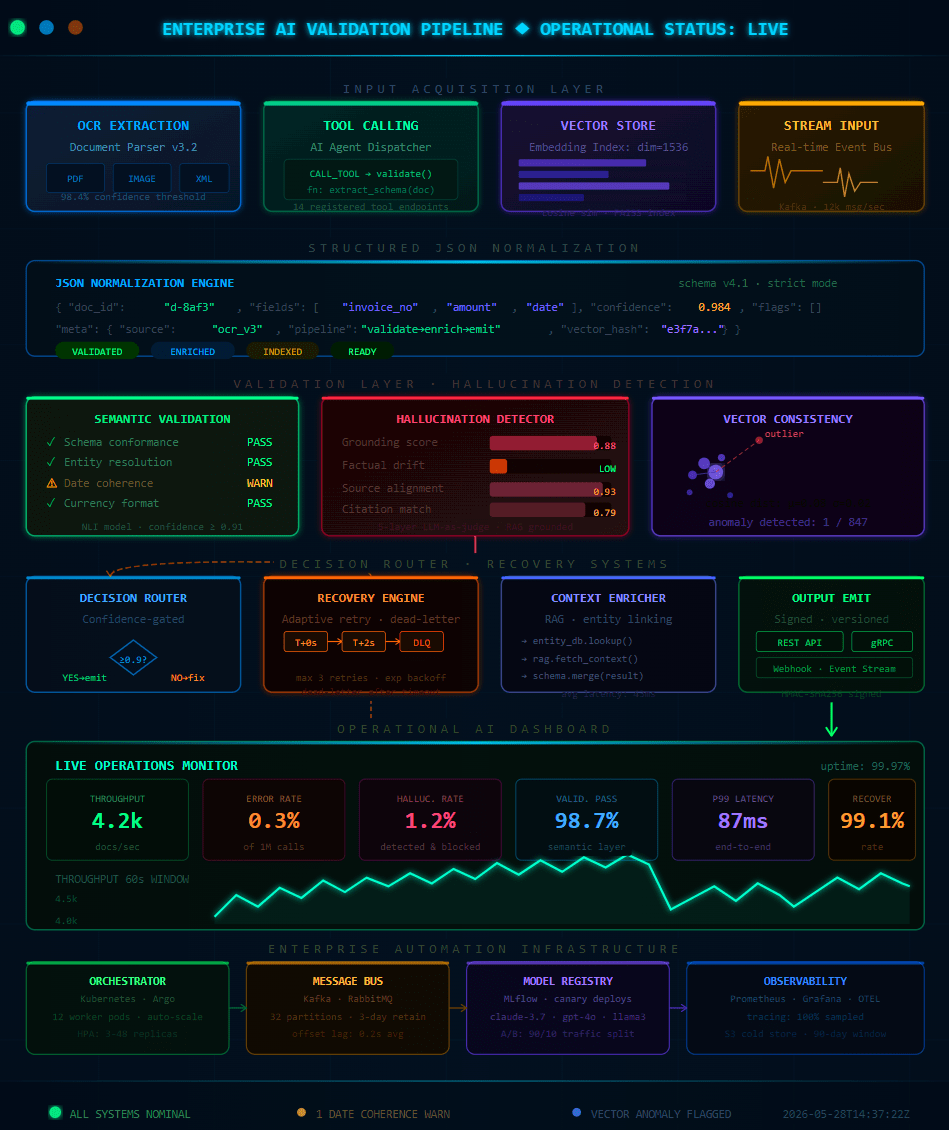
“The pipeline didn’t crash. The JSON was valid. The workflow completed. And the data was quietly […]
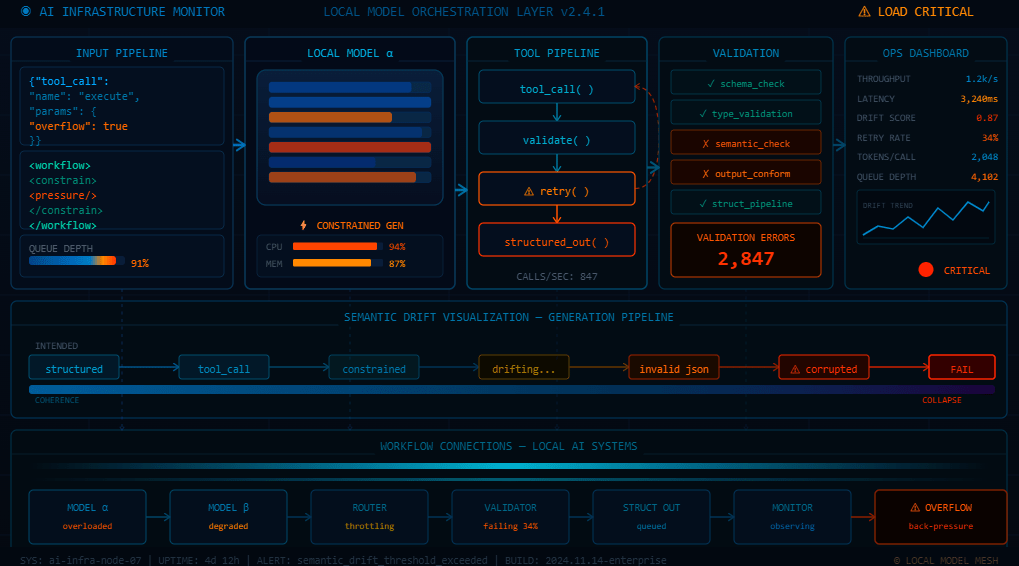
“The more I locked down the output format, the worse the actual content got. Tighter constraints, […]
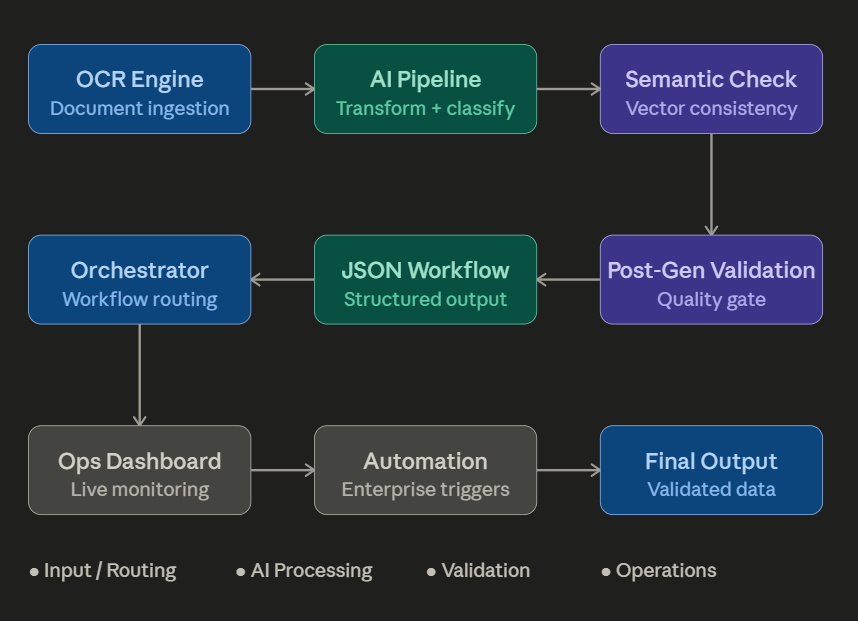
“The model didn’t fail. The output looked perfect. But the data it returned never existed in […]
The real story isn’t about which AI model is smartest. It’s about which one your business […]

The controversy around “uncensored” AI models is mostly noise. The operational reality is actually pretty interesting. […]
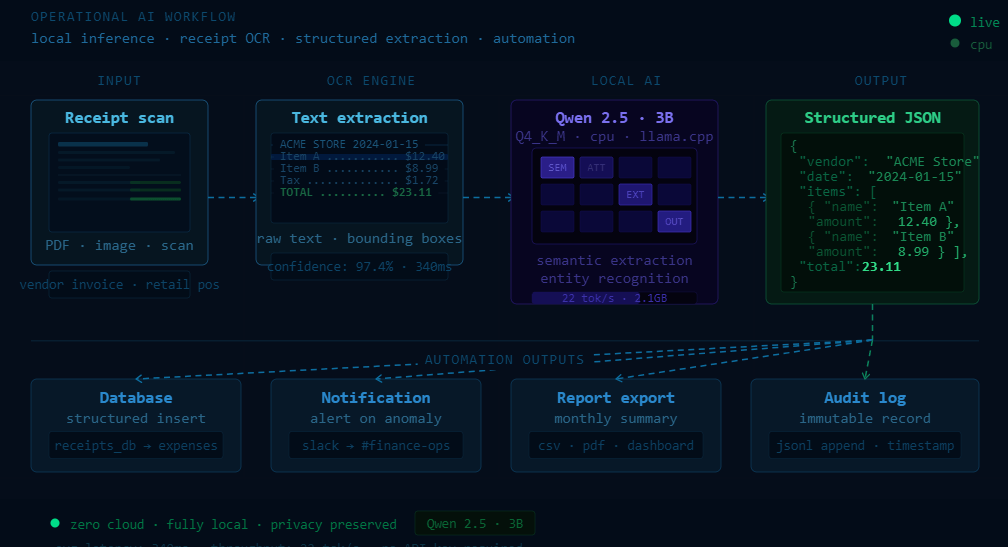
TL;DR: Small Qwen models running locally on consumer hardware are already good enough for OCR automation, […]
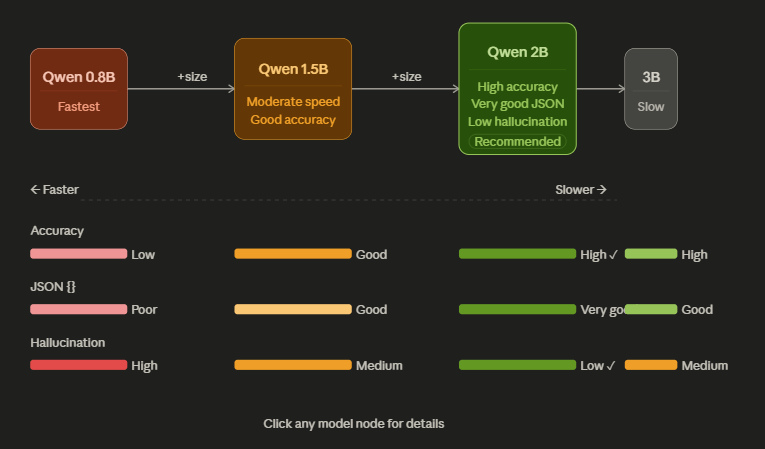
“The question isn’t whether small models are perfect. It’s whether they’re useful enough to build with.” […]
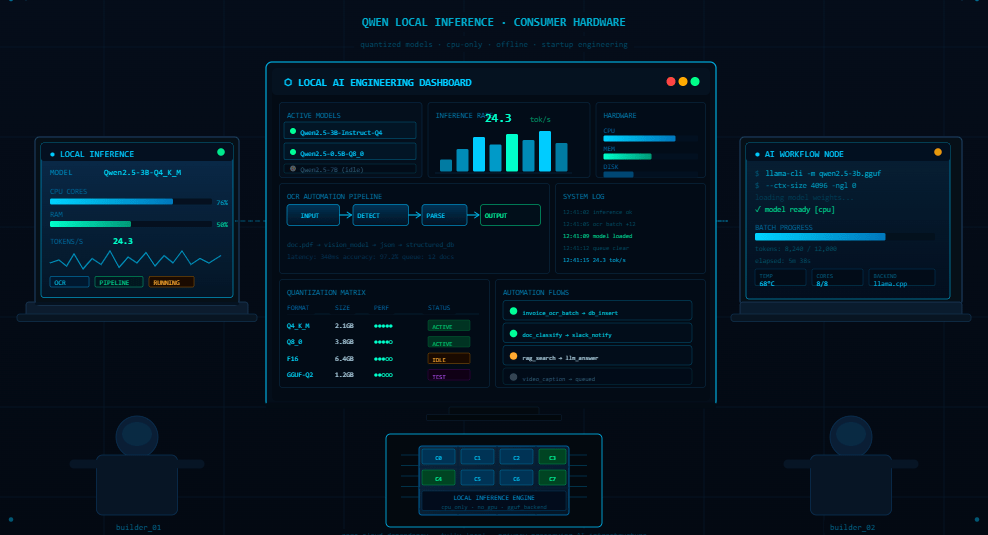
“You don’t need a data center to run useful AI anymore. That changes everything.” I remember […]
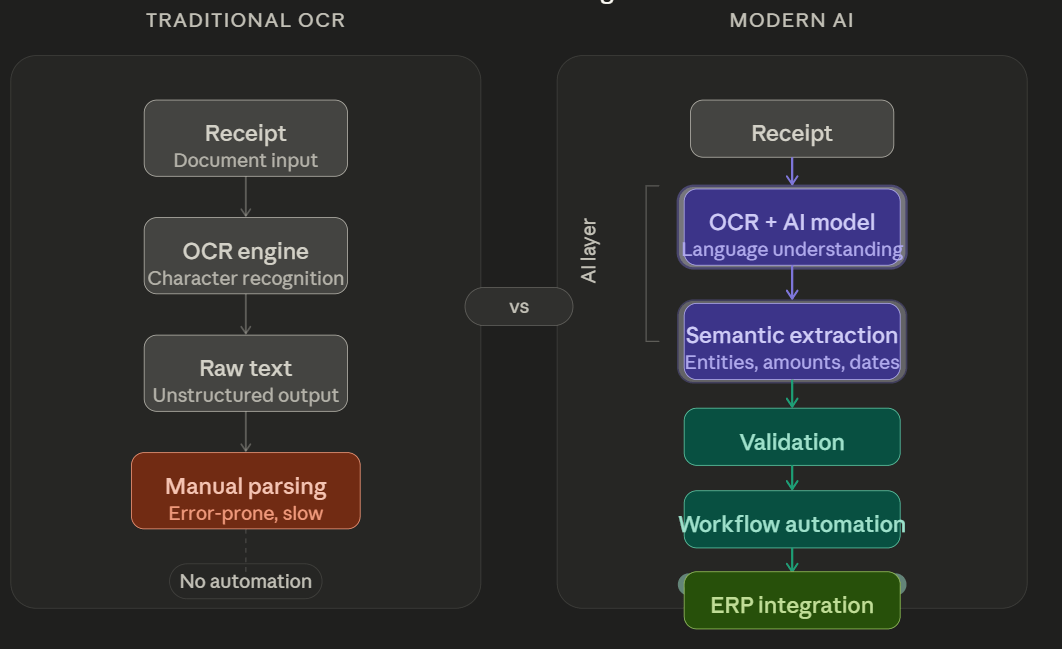
Receipt extraction initially appears to be a straightforward OCR problem. Scan the document.Extract the text.Convert it […]