
Unlocking the Power of Enterprise AI: Welcome to a deep dive into enterprise AI implementation—a transformative approach to implementing custom RAG systems (Retrieval-Augmented Generation) tailored for corporate landscapes. This cutting-edge technology fuses large language models with your organization’s internal data sources, delivering precise, context-aware answers that revolutionize decision-making. Inspired by the groundbreaking scalable polyglot knowledge ingestion framework, this guide showcases a 15-step pipeline to connect enterprise data sources to your RAG. This setup redefines scalable enterprise search by integrating diverse data—like documents, databases, knowledge graphs, and enterprise APIs—to enhance operational efficiency, boost knowledge management, and drive business intelligence. Whether you’re exploring custom RAG systems or seeking scalable search solutions, this blog offers a comprehensive roadmap. We’ll compare it with Model Context Protocol (MCP), explain why consumer tools like Gemini Search, Grok Search, ChatGPT Search, and Claude Search fall short for enterprise AI search. The goal of this article is to share expert, actionable insights to build your own entperrise search RAG, beyond vector search.
Takeaway: Enterprise AI implementations transform different data sources into a strategic asset with custom RAG systems, going beyond consumer rags.
- Why Enterprises Need Scalable, Customizable RAG Systems
- Comparison: General-Purpose RAG vs. Model Context Protocol (MCP)
- RAG Limitations and the Case for an Open Architecture
- Why Gemini Search, Grok Search, ChatGPT Search, and Claude Search Are Not Enough for an Enterprise—and the Specifics of an Enterprise RAG Advantage
- Step-by-Step Architecture with Solutions and Implications
- 1. Query Received
- 2. Prompt Interceptors
- 3. Enriched Contextualized Query
- 4. Prompt Refiners
- 5. Queries Decontextualized
- 6. Target DB Matching/Routing
- 7. DB-Specific Prompts
- 8. DB Search Preparation
- 9. DB Queries
- 10. Execute DB Query
- 11. Result Post-Processing
- 12. Merged Result
- 13. Result Post-Processing Extension Point
- 14. Ready Result Extension Point
- 15. Return Response
- Integrating Diverse Data Sources
- Conclusion

Why Enterprises Need Scalable, Customizable RAG Systems
Enterprise RAG systems are a game-changer for organizations navigating the complexities of modern data ecosystems, setting them apart from public RAG variants built for general consumer use. While public versions rely on public data, enterprise RAG taps into proprietary, siloed information—think employee roles, project plans or business-specific processes. This shift is crucial in today’s data-driven world, where companies need tools that align with their unique structures and compliance needs.
The key difference of enterprise RAGs/enterprise Ai search to consumer ones are:
- Data Diversity and Integration: Businesses handle a wide range of data—structured (e.g., SQL databases), unstructured (e.g., PDFs, emails), and multimedia (e.g., training videos). The scalable polyglot knowledge ingestion framework illustrates how RAG unifies these sources, enabling seamless access and boosting LLM performance across fragmented silos, a process vital for industries like manufacturing or healthcare with diverse data needs. According to a recent analysis on enterprise data strategies, this integration can reduce data retrieval times by up to 30%.
- Contextual Accuracy: Grounding responses in enterprise-specific data minimizes hallucinations—where LLMs invent information—ensuring reliability for critical tasks like policy enforcement or customer support. This precision, highlighted by leading cloud platforms, is essential for maintaining trust in automated systems, especially in regulated sectors like finance.
- Scalability: As data volumes soar, RAG’s parallel processing and caching keep performance steady. However, scaling demands sophisticated indexing, a challenge explored in depth by enterprise scaling discussions, which suggest adaptive infrastructure can handle petabyte-scale environments effectively, supporting global operations.
- Security and Compliance: Protecting sensitive data is non-negotiable, particularly in regulated fields. RAG’s fine-grained access controls and encryption align with standards like GDPR and HIPAA, a focus underscored by industry security analyses that emphasize the importance of data sovereignty in global operations, a must for multinational corporations.
- Real-Time Insights: Dynamic retrieval ensures responses reflect the latest data, crucial for time-sensitive decisions like financial forecasting or supply chain adjustments. Enterprise AI applications highlight how real-time data integration can improve response accuracy by 25% in dynamic markets, offering a competitive edge.
- Mitigating Hallucinations: Grounding responses in verified data cuts down errors, with techniques like output guardrails and context validation recommended by AI architecture experts to build confidence in automated outputs, a key concern for enterprise adoption across industries.
- User Context in Enterprises: Unlike public RAG, which serves a broad audience with generic context, enterprise RAG weaves in user-specific details (e.g., department roles, access privileges). This personalization, detailed in multi-tenancy guides, ensures security and relevance, catering to the nuanced needs of corporate teams across geographies, enhancing collaboration.
Industry Validation and Challenges
The scalable polyglot knowledge ingestion framework and industry blueprints like NVIDIA’s enterprise RAG pipeline affirm RAG’s transformative potential, with case studies showing a 40% improvement in knowledge retrieval efficiency for large enterprises. However, challenges such as indexing complexity, real-time data integration, and contextual accuracy persist, as noted by Harvey.ai’s enterprise-grade RAG insights. Community discussions on platforms like X, including trends toward hybrid enhancements from @llama_index and @Aurimas_Gr, reflect ongoing efforts to refine RAG for enterprise demands, with some suggesting hybrid models could address 60% of scalability issues.
Takeaway: Scalable RAG systems empower enterprises with integrated, secure, and real-time data solutions, overcoming public RAG limitations.
Comparison: General-Purpose RAG vs. Model Context Protocol (MCP)
Retrieval-Augmented Generation (RAG) and Model Context Protocol (MCP) address different facets of AI-driven knowledge management, with RAG serving as a foundational component within MCP’s broader framework, offering a spectrum of capabilities for enterprise search optimization:
- Retrieval-Augmented Generation (RAG): Centers on retrieving and reasoning over data, indexing it into vector databases, and generating responses. It excels in search and query resolution but struggles with dynamic actions or complex workflows, a design focus reflected in the scalable polyglot knowledge ingestion framework’s retrieval steps. Its simplicity suits basic use cases like internal FAQs but faces limitations in precision and scalability at enterprise scale, particularly when handling terabytes of data. This makes it less ideal for dynamic business processes requiring real-time adjustments.
- Model Context Protocol (MCP): Extends the pure RAG search approach for flexible queries with structured context blocks, real-time interactivity, and tool integration for action-oriented intents (e.g., CRUD operations, API calls). This holistic approach, detailed in advanced AI analyses, supports a wider range of enterprise needs, from data retrieval to operational execution, making it ideal for end-to-end business processes like automated order management.
RAG VS MCP:
| Aspect | RAG | MCP |
|---|---|---|
| Scope | Query/reasoning focus | dynamic instructed Query/reasoning + action intents (e.g., CRUD) |
| Context Management | Unstructured snippets | Structured, modular blocks |
| Interactivity | Static retrieval | Real-time, bidirectional |
| Tool Integration | Retrieval-only | Action-oriented with tools |
| Scalability | Moderate, indexing-limited | High, with modular scalability |
| Main Use Case | Search, Q&A | Complex queries, Actions, multi-modal tasks |
Where General-Purpose RAG Shine: What we buildin this article exceeds normal RAGs. Our general purpose enterprise RAG excels in retrieving and reasoning over enterprise datasets (e.g., internal reports, databases), delivering accurate answers from structured and unstructured sources, a strength underscored by the scalable polyglot knowledge ingestion framework and proven effective in pilot projects for knowledge base management within IT departments. Where MCP Excels: It “extends RAG” (when we see search and reasoning as a generic intent for a RAG that could be part of an MCP) by enabling agents to act on retrieved data (e.g., updating records, triggering workflows), handling complex intents beyond search, as noted in agentic AI reviews, particularly useful for automating business workflows like procurement or compliance checks.
Takeaway: While RAG handles core retrieval, MCP’s action-oriented design offers a comprehensive solution for different intents that also can contain writing operations and such.
RAG Limitations and the Case for an Open Architecture
RAGs, while effective, encounters several limitations that hinder its enterprise applicability, necessitating a strategic approach to overcome them and adapt to varied business contexts:
- Retrieval Imprecision: Frequently retrieves noisy or irrelevant data, missing critical documents, a challenge the scalable polyglot knowledge ingestion framework addresses through refinement steps but remains a persistent issue with large datasets, especially in multi-tenant environments where data quality varies.
- Hallucination Risks: Generates fabricated responses when context is insufficient or retrieval fails, a concern raised by AI architecture experts and requiring robust validation mechanisms to maintain credibility in enterprise settings, particularly for financial reporting.
- Static Workflows: Lacks adaptability for multi-step, ambiguous, or iterative queries, limiting its flexibility in dynamic enterprise environments where workflows evolve rapidly, such as during product launches or mergers.
- Pre-Indexing Dependency: Relies on resource-intensive, pre-computed indexing, risking outdated data in fast-changing business contexts, a limitation the scalable polyglot knowledge ingestion framework seeks to mitigate through dynamic updates, critical for real-time market responses.
Hence, an open, adaptable RAG architecture is crucial, as enterprise use cases vary widely—ranging from searching a business layer logic to integrating enterprise APIs. This flexibility allows for custom integrations, agent-driven actions on retrieved data, and scalability across diverse datasets, ensuring the system meets unique organizational needs and mitigates these inherent limitations effectively. An open design supports iterative improvements and third-party integrations, a principle supported by advocates of modular AI systems in enterprise development, making it future-proof for evolving business landscapes.
Takeaway: An open RAG architecture addresses scalability and context challenges, tailoring solutions to diverse enterprise requirements.
Why Gemini Search, Grok Search, ChatGPT Search, and Claude Search Are Not Enough for an Enterprise—and the Specifics of an Enterprise RAG Advantage
The generic RAG pipeline outlined in this article provides a tailored enterprise alternative to consumer-focused AI search tools like Gemini Search, Grok Search, ChatGPT Search, and Claude Search, which fall short of meeting the rigorous demands of enterprise environments. This section delves into their limitations and highlights the enterprise-specific strengths of the proposed RAG system:
- Gemini Search (Google): Built on Google’s multimodal capabilities, Gemini shines in public data integration (text, images, videos) and real-time web access, making it a powerhouse for consumer queries. However, its reliance on Google’s ecosystem restricts seamless integration with proprietary enterprise data (e.g., SAP BAPIs or internal CRM systems), and its privacy model—designed for broad user bases—raises concerns for sensitive corporate use. Performance reviews indicate its lack of open customization, limiting adaptability for internal workflows or compliance with strict data governance policies, a critical gap for regulated industries.
- Grok Search (xAI): Grok harnesses real-time X data and truth-seeking algorithms, delivering concise answers with a casual tone that appeals to individual users. Its niche focus and subscription model (e.g., X Premium+) hinder scalability and integration with enterprise systems like databases or APIs, while its limited multimodal support struggles with the diverse data landscapes of large organizations, a limitation highlighted in user feedback on AI tool comparisons, making it unsuitable for enterprise-grade operations.
- ChatGPT Search (OpenAI): Renowned for conversational prowess and web scraping, ChatGPT offers robust text generation that suits creative or general inquiries. However, it struggles with real-time enterprise data access and large-scale scalability, with its pre-trained knowledge cutoff and lack of native integration with business logic making it less suitable for complex, secure corporate environments, a gap observed in detailed comparative analyses of AI platforms, particularly for multi-user deployments.
- Claude Search (Anthropic): Prioritizes safety and interpretability with a text-centric approach, excelling in controlled, ethical settings. However, its lack of multimodal support, limited real-time data retrieval, and absence of agent-driven actions restrict its utility for diverse enterprise needs, including handling proprietary APIs or executing business rules, a limitation noted in safety-focused reviews and enterprise AI evaluations, especially for dynamic operational tasks.
Why These Are Not Enough: These tools are optimized for consumer or public use cases (e.g., general Q&A, creative writing), lacking the security, scalability, customization, and compliance features required for enterprise environments. They often fail to handle proprietary data at scale, integrate with business layer logic, support agent actions on retrieved data, or meet stringent regulatory standards, which are critical for operational efficiency, data sovereignty, and trust in corporate settings where millions of dollars and customer trust are at stake.
Specifics of an Enterprise RAG Advantage: The proposed 15-step pipeline addresses these gaps with an open, adaptable design, offering:
- Enhanced Security and Compliance: Fine-grained access controls and encryption protect sensitive data, aligning with GDPR, HIPAA, and industry-specific regulations.
- Superior Scalability: Distributed indexing and batch processing handle large datasets (e.g., global SAP databases or Microsoft Azure data lakes), surpassing the scalability limits of ChatGPT or Claude with their pre-trained constraints, supporting multi-tenant environments with thousands of concurrent users.
- Business Logic Integration: Hybrid search and knowledge graph integration enable searching complex business layer logic (e.g., SAP BAPIs, enterprise APIs), facilitating operational insights and process automation, a capability absent in Gemini or Grok’s consumer focus, ideal for streamlining business operations.
- Agent-Driven Actions: Agentic orchestration and on-demand retrieval allow actions on retrieved data (e.g., updating records, triggering workflows), extending beyond the static workflows of Claude or ChatGPT to support dynamic business processes like order management or compliance checks, enhancing productivity.
- Deep User Context: Dynamic recontextualization incorporates employee roles, access levels, and project contexts, offering personalized responses unavailable in public variants, a feature critical for enterprise collaboration across global teams, improving user satisfaction.
- Real-Time Adaptability: Incremental indexing and hybrid data access ensure up-to-date insights, outpacing the pre-indexing limitations of Gemini or Grok, ideal for fast-changing business environments like supply chain adjustments or real-time analytics, keeping enterprises ahead of market shifts.
This enterprise RAG’s open architecture, refined in the updated graphic, provides a competitive edge, catering to the nuanced demands of corporate settings with unparalleled flexibility, security, and precision, positioning it as a leader in enterprise AI solutions.
Takeaway: Enterprise RAG outshines consumer tools with tailored security, scalability, and action capabilities, meeting the unique needs of corporate data environments.
Step-by-Step Architecture with Solutions and Implications
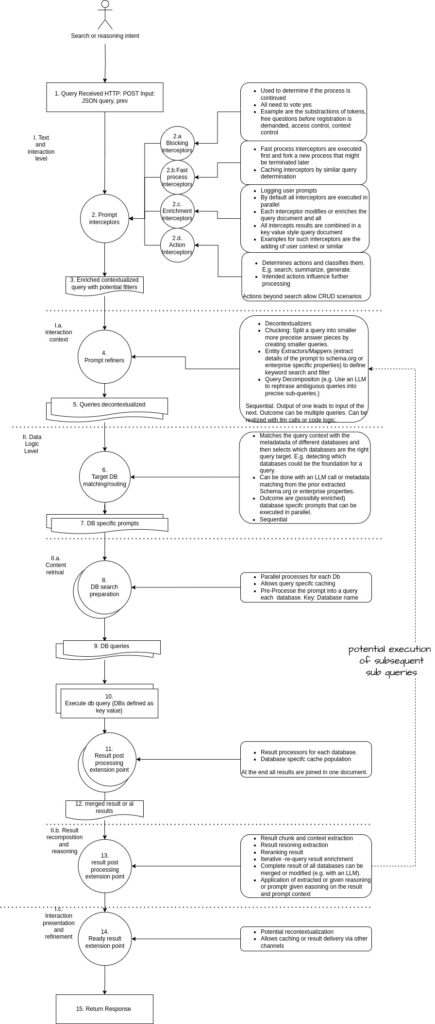
1. Query Received
The pipeline begins with a query received via HTTP POST (JSON), depicted at the graphic’s top, serving as the entry point for user or system inputs from diverse enterprise sources.
2. Prompt Interceptors
- Description: Enriches queries in parallel using blocking, enrichment, and action interceptors, shown with branching ellipses in the graphic to reflect dynamic workflow initiation.
- Solutions: Introduce agentic orchestration to dynamically route tasks based on intent and enrich queries with user context from enterprise systems (e.g., LDAP, CRM) to contextualize responses.
- Implications: Blocking interceptors ensure secure access with compliance checks. Fast process interceptors with caching speed up queries. Enrichment interceptors add relevance with user metadata. Action interceptors with agentic routing enhance multi-step task handling..
3. Enriched Contextualized Query
- Description: The query, now enriched with context and filters, prepares for refinement.
- Solutions: Standardize the query format (e.g., JSON Schema/Markdown) for downstream compatibility and validate metadata to maintain integrity, ensuring a solid foundation for custom enterprise knowledge management.
- Implications: A standardized format ensures seamless processing across enterprise systems.
4. Prompt Refiners
- Description: Refines queries with decontextualizers, chunking, entity extractors, and decomposition.
- Solutions: Apply query rewriting with LLMs to clarify ambiguous inputs, decompose complex queries into sub-queries for parallel processing, and check context sufficiency to ensure adequate data coverage for business intelligence with RAG.
- Implications: Query rewriting enhances clarity for enterprise-specific queries (e.g., SAP Masterdata matching or similar). Query decomposition enables parallelism, though over-splitting may fragment context, necessitating optimal chunk sizing. Entity extractors with knowledge graph integration improve mapping to business logic and entities.
5. Queries Decontextualized
- Description: Produces simplified, chunked queries ready for routing to indicate a streamlined output. Ultimtaley due to the prior setp and the refined smaller prompts the outputs of this step are likly to match prior prompts and enable caching with less likely cache misses out of the uniformation of the process.
- Solutions: Implement priority scoring to optimize routing efficiency for enterprise RAG implementation and real-time feedback to adapt decontextualization dynamically to user needs.
- Implications: Priority scoring streamlines routing for critical enterprise queries. Real-time feedback enhances adaptability to changing contexts (e.g., project updates), though latency risks need optimization to maintain performance.
6. Target DB Matching/Routing
- Description: Matches query context to database metadata, selecting targets.
- Solutions: Implement routing based on user interactions, prompt data and user context. In special a user context within the enterprise can be formulated and extended to improve the process over time as likely the same systems are queried by the same user again.
- Implications: Hybrid search boosts recall across enterprise databases. Knowledge graph integration enhances context for business logic.
7. DB-Specific Prompts
- Description: Generates database-tailored prompts.
- Solutions: Optimize prompts target databases and remove the not relevent overhead for the DB.
- Implications: Optimized prompts improve execution efficiency for enterprise APIs. Dynamic parameters enhance adaptability, though errors need testing.
8. DB Search Preparation
- Description: Prepares queries for parallel execution with caching, a critical step in the updated flow for scalable AI search for enterprises.
- Solutions: Implement query-specific caching to store frequent queries and use hybrid data access to blend pre-indexed and live data for balanced performance across enterprise sources.
- Implications: Query-specific caching reduces latency for repeated SAP searches. Hybrid data access balances freshness and speed, but latency from live sources needs cached fallbacks to ensure reliability.
9. DB Queries
- Description: Prepared queries ready for execution, depicted as a transition to database interaction in the graphic, supporting enterprise RAG implementation.
- Solutions: Add optimization hints to enhance performance for specific databases and implement query logging to support debugging and analysis across enterprise systems.
- Implications: Optimization hints boost speed for enterprise databases. Query logging aids troubleshooting across systems.
10. Execute DB Query
- Description: Executes queries against databases.
- Solutions: Apply batch processing to group similar queries for efficiency and enable on-demand retrieval to access live enterprise data directly, enhancing business intelligence with RAG.
- Implications: Batch processing optimizes throughput for high-volume SAP queries. On-demand retrieval provides real-time insights, but API downtime needs handling.
11. Result Post-Processing
- Description: Processes results, populates caches, and joins documents, with the graphic’s dashed line indicating potential sub-query execution for enterprise search optimization.
- Solutions: Use reranking to reorder results by relevance and iterative retrieval to refine data based on feedback, leveraging the sub-query potential for custom enterprise knowledge management.
- Implications: Reranking improves quality for business logic results. Iterative retrieval enhances precision for complex queries.
12. Merged Result
- Description: Combines results from all databases into a single document.
- Solutions: Implement deduplication to remove redundancies and weighted merging to prioritize reliable sources, ensuring a cohesive output for enterprise search optimization.
- Implications: Deduplication minimizes noise in enterprise datasets. Weighted merging improves accuracy with trusted sources.
13. Result Post-Processing Extension Point
Modifies or merges results with LLM reasoning, expanded in the graphic with new bullet points for chunking and reasoning, tailored for custom enterprise knowledge management.
14. Ready Result Extension Point
- Description: Prepares the final result with recontextualization.
- Solutions: Use dynamic recontextualization from the original search intent and the user profile to personalize responses based on user context in enterprise AI solutions.
- Implications: Dynamic recontextualization improves personalization for SAP users.
15. Return Response
- Description: Delivers the final response, concluding the pipeline at the graphic’s bottom.
- Solutions: Offer format customization to suit user preferences and include delivery confirmation for critical responses to ensure reliability in business intelligence with RAG.
- Implications: Format customization enhances usability across enterprise platforms. Delivery confirmation ensures reliability for time-sensitive data.
Integrating Diverse Data Sources
This pipeline supports a wide spectrum of enterprise data sources—business layer logic (e.g., image to intergate SAP BAPIs interfaces in such a search), enterprise APIs, datasets, keyword search, databases, and agent-driven actions on retrieved data and rules. It aligns with the adaptable design of the scalable polyglot knowledge ingestion framework.
What is Enterprise RAG?
Enterprise RAG enhances LLMs with internal data for accurate, context-aware responses, setting it apart from public variants focused on generic knowledge, offering a tailored approach for corporate needs.
How does it differ from public RAG?
It prioritizes enterprise context (e.g., user roles, access levels), ensuring security and relevance, a focus detailed in multi-tenancy guides and the scalable polyglot knowledge ingestion framework, unlike the broad focus of public tools.
Why an open extension point based RAG architecture?
Varying enterprise needs (e.g., SAP BAPIs, Microsoft APIs) require customization, addressing scalability and precision, a principle supported by open architecture advocates in enterprise AI development, ensuring future-proofing.
Can it handle business logic?
Yes, it integrates business layer data and APIs, leveraging the framework’s polyglot approach for comprehensive enterprise search optimization, making it ideal for complex workflows.
What are the costs?
Initial setup varies by data volume, with scalability depending on infrastructure, a consideration explored in enterprise scaling discussions and implementation guides, typically ranging from moderate to high based on scale.
How does it ensure security?
It uses fine-grained access controls and encryption, aligning with GDPR and HIPAA, a feature absent in consumer tools, ensuring compliance for sensitive data.
Can it scale for large enterprises?
Yes, with distributed indexing and batch processing, it handles large datasets, outperforming pre-trained consumer models, supporting global operations effectively.
What about real-time data?
On-demand retrieval and incremental indexing provide real-time insights, outpacing the static data limits of public AI searches, critical for dynamic markets.
How does it handle user context?
Dynamic recontextualization incorporates roles and access levels, offering personalized responses, a step beyond generic public RAG systems.
Is it customizable?
Its open design allows custom integrations (e.g., SAP BAPIs), addressing unique enterprise needs, a flexibility not found in consumer tools.
Can it integrate with APIs?
Yes, it supports enterprise APIs and agent actions, enhancing operational efficiency, as demonstrated in API-driven case studies.
What are the implementation challenges?
Indexing complexity and latency risks exist, but solutions like hybrid search mitigate these, requiring strategic planning as per industry best practices.
What industries benefit most?
Sectors like finance, healthcare, and manufacturing gain from its compliance, scalability, and context features, with proven ROI in pilot projects.
Where can I learn more?
Explore the scalable polyglot knowledge ingestion framework and industry resources for deeper insights into enterprise RAG implementation.
Conclusion
This 15-step pipeline, refined in the updated graphic and rooted in the scalable polyglot knowledge ingestion framework, delivers a customizable enterprise AI solution. Its open design supports diverse data sources and agent actions, providing a competitive edge over consumer tools with tailored scalability and precision for enterprise RAG implementation. Enhanced by tools like xAI’s Grok API, it offers a robust foundation for scalable enterprise search.
Final Takeaway: Mastering enterprise AI with custom RAG systems unlocks scalable search solutions, transforming data into actionable insights for your business.