
The NLWeb search prototype, developed by Microsoft Research, is a Python-based framework designed to process natural language queries for specific websites, delivering relevant and structured results. This article provides a detailed explanation of how the NLWeb search prototype handles an example query, such as “Find vegetarian recipes for Diwali”, in its normal flow with prior context (prev). Using insights from the NLWeb GitHub repository, we’ll walk through the query processing pipeline, supported by two flowcharts: a simplified version (Figure 1) and an extended version with fast track comparison steps (Figure 2). This NLWeb example illustrates the system’s integration of AI, Schema.org, and vector search technologies.
Overview of the NLWeb Search Prototype
NLWeb is a proof-of-concept system that processes queries using OpenAI’s large language models (LLMs) for analysis and embeddings, Qdrant for vector search, and Schema.org for structured data, such as Recipe entities. The system supports conversational queries by maintaining context through previous queries (prev) and optimizes performance with parallel processing. Key scripts—ask.py, memory.py, prompt_runner.py—and documentation (LifeOfAChatQuery.md, RestAPI.md) define its architecture.
For this NLWeb example, we’ll examine the normal flow (with prev, non-fast track) for the query:
{
"query": "Find vegetarian recipes for Diwali",
"site": "example.com",
"prev": ["What are some Indian festival recipes?", "Any vegetarian options?"],
"mode": "list",
"streaming": true
}Simplified NLWeb Query Processing Pipeline
The simplified normal flow, shown in Figure 1, processes the query through 8 steps, focusing on core functionality.
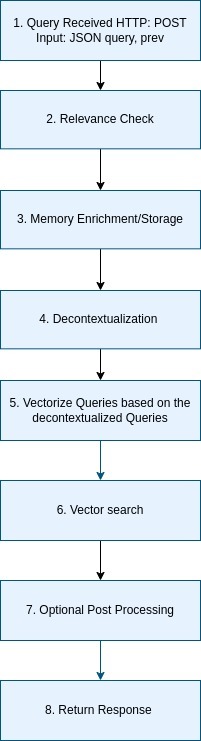
- Query Received (Step 1): The pipeline starts with an HTTP POST to the /ask endpoint in `ask.py`. NLWeb parses the JSON query, extracting
– the query text, site (e.g. we imagine that license-token.com is defined as a recipe_website in the NLWeb configuration),
– prev (potential prior queries),
– mode (list), and streaming preference.
In detail the NLwerb Server loads `site_type.xml` to identify license-token.com as a recipe_website with Schema.org Recipe context. - Relevance Check (Step 2): NLWeb verifies query relevance to recipe_website using `analyze_query.py`, sending an LLM request to OpenAI. It outputs {“is_relevant”: true} if the query aligns with the Recipe schema.
- Memory Detection (Step 3): The `memory.py` script stores or loads data from memory depending on the prompt given. E.g. the user can say in the prompt remember the current instructions in the future and and refer to such prior instructions. Basically the what is remembered logic and pulled out of storage is done with an LLM, producing memory_items JSON.
- Decontextualization (Step 4): The `prompt_runner.py` script rewrites the query with prev using an LLM, outputting a standalone query. Subsequent queries are combined in a single query that does not need to know from the prior chat context.
- Vectorize Queries (Step 5): ask.py sends the decontextualized query and memory_items to an embedding API (text-embedding-ada-002, per `config_embedding.yaml`), generating a numerical embedding vector.
- Vector Search (Step 6): ask.py queries Qdrant with the embedding and memory_items filters (e.g., suitableForDiet: Vegetarian is expressed as a vector), returning matching Recipe documents (e.g., “Vegetarian Diwali Samosas”).
- Optional Post Processing (Step 7): If mode=summarize, ask.py applies additional formatting or enrichment (skipped for mode=list).
- Return Response (Step 8): ask.py formats results as Schema.org Recipe JSON (e.g., {“@type”: “Recipe”, “name”: “Vegetarian Diwali Samosas”}) and streams to the client if streaming=true.
Extended Query Processing Pipeline with Fast Track Nodes
The extended normal flow, shown in Figure 2, includes 10 steps, adding custom fast track validation steps to ensure robustness. Steps 2–5 run in parallel, followed by sequential steps and validation nodes.
<!– Placeholder for Figure 2 –>
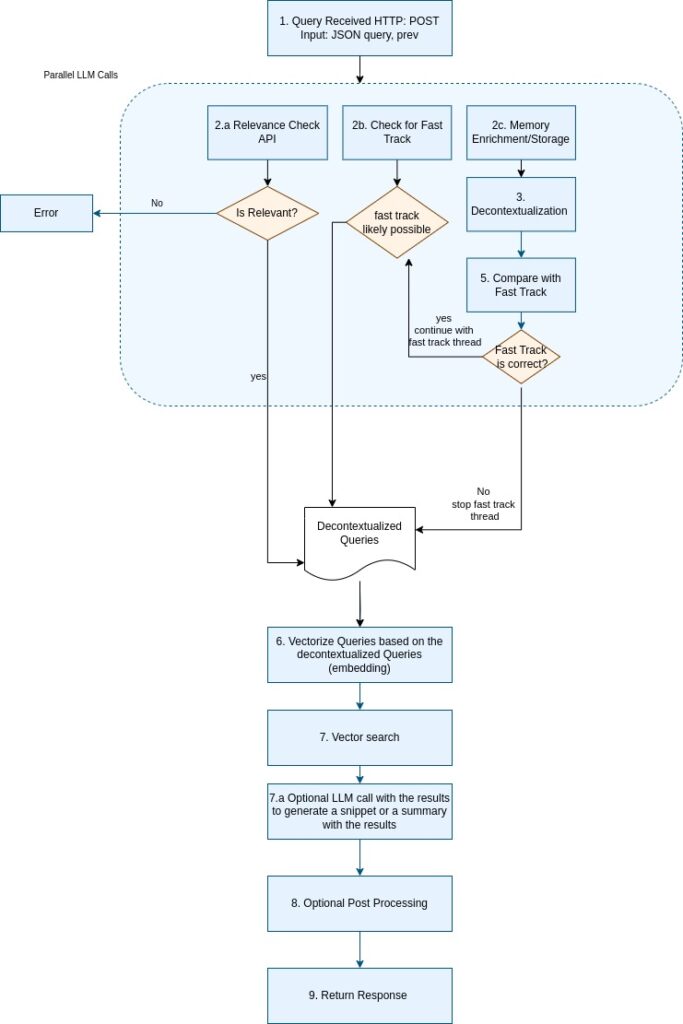
How queries work in the NLWeb prototype:
- Query Received (Step 1): Identical to the simplified flow, ask.py parses the JSON query and prev, loading site_type.xml for recipe_website context. Sequential, no API calls.
- Relevance Check (Step 2a): analyze_query.py verifies relevance using OpenAI LLM, outputting {“is_relevant”: true}. Could be executed in parallel with Steps 3–5, with an “Is Relevant?” decision branching to an Error node if false terminating all threads if not relevant.
- Check for Fast Track (Step 2b): analyze_query.py checks query simplicity via LLM, outputting {“is_simple”: false}. In case of a simple query it continues directly to process further while the regular processing still happens in another thread.
- Memory Detection (Step 2c): memory.py extracts memory_items or stores new details in the memory to use them in later queries.
- Decontextualization (Step 4): prompt_runner.py rewrites the query with prev, outputting a decontextualized query.
- Once the query id decontextualized it can be check if the fast track decision was correct. If the current query is the same like the query at the beginning the fast track was correct and can be followed otherwise the fast track thread is stopped.
- Decontextualized Queries (Unnumbered): The decontextualized query output feeds into vectorization. Sequential, handled in ask.py.
- Vectorize Queries (Step 6): Identical to simplified flow, generates embedding via an embedding provider. Sequential.
- Vector Search (Step 7): Queries 8 (e.g. Qdrant) with embedding, returning Recipe documents. Sequential.
- Optional LLM Call (Step 8): If mode=summarize, ask.py uses OpenAI LLM to summarize results (skipped for mode=list). Sequential, optional.
- Optional Post Processing (Step 9): Applies additional formatting if requested (skipped for mode=list). Sequential, optional.
- Return Response (Step 10): Formats results as Schema.org Recipe JSON and streams to the client. Sequential, final step.
TL;DR Key Features of the NLWeb Search Prototype
The NLWeb search prototype, offers several key features:
- Parallel Processing: Reducing latency to approximately 0.5–0.7 seconds, compared to 1.2–2 seconds sequentially.
- Conversational Context: Handles prev through decontextualization and memory detection, supporting follow-up queries in chat-like interfaces.
- Vector Search: E.g. Qdrant delivers accurate results, filtered by memory_items for relevance.
Practical Implications
The flowcharts highlight NLWeb’s modular design, adaptable to domains like e-commerce or news by updating site_type.xml. Developers can explore this NLWeb example by forking the NLWeb GitHub repository to build custom search solutions.
Conclusion
The NLWeb search prototype, visualized in Figures 1 and 2, processes queries with precision and efficiency, transforming an example query like “Find vegetarian recipes for Diwali”. The simplified flowchart (Figure 1) provides a clear overview of the 8-step process, while the extended flowchart (Figure 2) includes additional fast track validation steps. This NLWeb example showcases the power of AI-driven search, offering a foundation for developers to create intelligent, context-aware systems. Visit the NLWeb GitHub repository to explore the code and adapt it for your projects.